
pwn入门-ELF文件概述程序装载与虚拟内存
pwn入门-ELF文件概述程序装载与虚拟内存
参考程序加载 - CTF Wiki和https://www.bilibili.com/video/BV1Uv411j7fr?spm_id_from=333.788.videopod.episodes&vd_source=d76ad0aadca055336653cd966075f064&p=3

pwn概述
exploit:用于攻击的脚本与方案
payload:攻击载荷,是的目标进程被劫持控制流的数据
shellcode:调用攻击目标的she的代码
攻击流程:
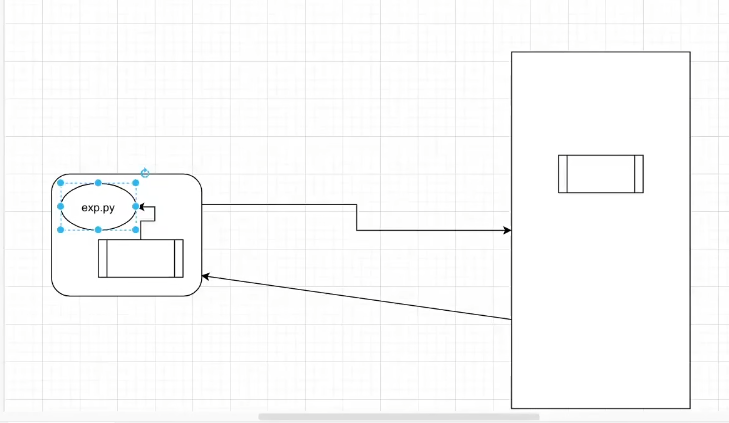
C语言执行流程
C语言代码到可执行文件流程:

目标文件未经过链接,虽然知道自己任务但是不知道如何去做,比如put为何就是输入,需要将多个机器码目标文件链接成一个可执行文件

广义:文件中的数据是可执行代码的文件.out、.exe、.sh、.py
狭义:文件中的数据是机器码的文件.out、.exe、.dll、.so
Windows:PE(Portable Executable)
可执行程序:.exe
动态链接库:.dl
静态链接库:.lib
Linux:
ELF可执行程序.out
动态链接库.so
静态链接库.a
操作系统会自动去找.so和.a
ELF文件结构(静态)
ELF文件结构:

ELF目标文件格式最前部ELF文件头(ELF Header),它包含了描述了整个文件的基本属性,比如ELF文件版本、目标机器型号、程序入口地址等。
其中ELF文件与段有关的重要结构就是段表(Section Header Table)
- 可重定向文件:文件保存着代码和适当的数据,用来和其他的目标文件一起来创建一个可执行文件或者是一个共享目标文件。(目标文件或者静态库文件,即linux通常后缀为.a和.o的文件)
- 可执行文件:文件保存着一个用来执行的程序。(例如bash,gcc等)
- 共享目标文件:共享库。文件保存着代码和合适的数据,用来被下连接编辑器和动态链接器链接。(linux下后缀为.so的文件。)
ELF文件格式提供了两种视图,分别是链接视图和执行视图。
链接视图是以节(section)为单位,执行视图是以段(segment)为单位。链接视图就是在链接时用到的视图,而执行视图则是在执行时用到的视图。下图左侧的视角是从链接来看的,右侧的视角是执行来看的。总个文件可以分为四个部分:
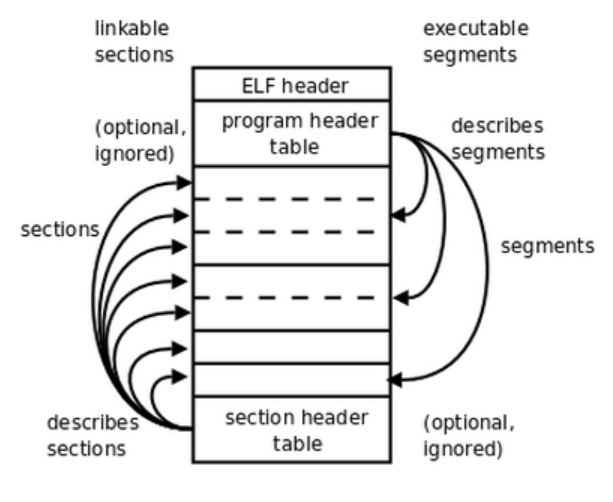
- ELF header: 描述整个文件的组织。
- Program Header Table: 描述文件中的各种segments,用来告诉系统如何创建进程映像的。
- sections 或者 segments:segments是从运行的角度来描述elf文件,sections是从链接的角度来描述elf文件,也就是说,在链接阶段,我们可以忽略program header table来处理此文件,在运行阶段可以忽略section header table来处理此程序(所以很多加固手段删除了section header table)。从图中我们也可以看出, segments与sections是包含的关系,一个segment包含若干个section。
- Section Header Table: 包含了文件各个segction的属性信息,我们都将结合例子来解释。
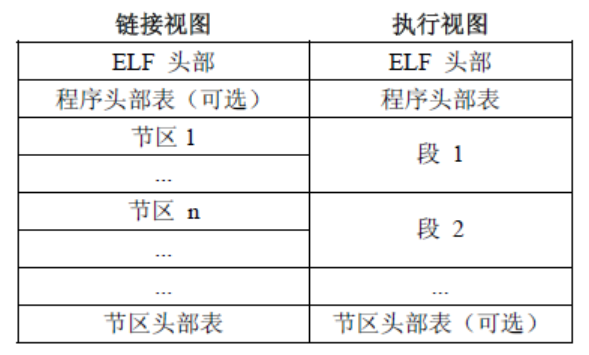
程序头部表(Program Header Table),如果存在的话,告诉系统如何创建进程映像。
节区头部表(Section Header Table)包含了描述文件节区的信息,比如大小、偏移等。
ELF 文件头

在ELF文件头中,我们需要重点关注以下几个字段:
- e_entry:程序入口地址
- e_ehsize:ELF Header结构大小
- e_phoff、e_phentsize、e_phnum:描述Program Header Table的偏移、大小、结构。
- e_shoff、e_shentsize、e_shnum:描述Section Header Table的偏移、大小、结构。
- e_shstrndx:这一项描述的是字符串表在Section Header Table中的索引,值25表示的是Section Header Table中第25项是字符串表(String Table)。
段表(Section Header Table)
段表就是保存ELF文件中各种各样段的基本属性的结构。段表是ELF除了文件以外的最重要结构体,它描述了ELF的各个段的信息,ELF文件的段结构就是由段表决定的。编译器、链接器和装载器都是依靠段表来定位和访问各个段的属性的。段表在ELF文件中的位置由ELF文件头的“e_shoff”成员决定的,比如SimpleSection.o中,段表位于偏移0x118。
节,表(Section)
符号表(.dynsym)
符号表包含用来定位、重定位程序中符号定义和引用的信息,简单的理解就是符号表记录了该文件中的所有符号,所谓的符号就是经过修饰了的函数名或者变量名,不同的编译器有不同的修饰规则。例如符号_ZL15global_static_a,就是由global_static_a变量名经过修饰而来。
符号表项的格式如下:
1 | typedef struct { |
重定位表
重定位表在ELF文件中扮演很重要的角色,首先我们得理解重定位的概念,程序从代码到可执行文件这个过程中,要经历编译器,汇编器和链接器对代码的处理。然而编译器和汇编器通常为每个文件创建程序地址从0开始的目标代码,但是几乎没有计算机会允许从地址0加载你的程序。如果一个程序是由多个子程序组成的,那么所有的子程序必需要加载到互不重叠的地址上。重定位就是为程序不同部分分配加载地址,调整程序中的数据和代码以反映所分配地址的过程。简单的言之,则是将程序中的各个部分映射到合理的地址上来。
换句话来说,重定位是将符号引用与符号定义进行连接的过程。例如,当程序调用了一个函数时,相关的调用指令必须把控制传输到适当的目标执行地址。
具体来说,就是把符号的value进行重新定位。
字符串表(.dynstr)
ELF文件中用到了许多的字符串,比如段名,变量名等。因为字符串的长度往往是不定的,所以用固定的结构来表示它比较困难。一种常见的做法是把字符串集中起来存放到一个表,然后使用字符串在表中的偏移来引用字符串。
通常用这种方式,在ELF文件中引用字符串只需给一个数字下标即可,不用考虑字符串的长度问题。一般字符串标在ELF文件中国也以段的方式保存,常见的段名为“.strtab”或“.shstrtab”。这两个字符串分别表示为字符串表和段表字符串表。
只有分析ELF文件头,就可以得到段表和段表字符串表的位置,从而解析整个ELF文件。
.data 段
已初始化的全局变量和局部静态变量都保存在 .data 段。
.bss 段
未初始化的全局变量和局部静态变量默认值都为 0,本来它们也可以被放在 .data 段的,但是因为它们都是 0,所以为它们在 .data 段分配空间并且存放数据 0 是没有必要的。
程序运行的时候它们的确是要占内存空间的,并且可执行文件必须记录所有未初始化的全局变量和局部静态变量的大小总和,记为 .bss 段。
因此,.bss 段只是为未初始化的全局变量和局部静态变量预留位置而已,它并没有内容,所以它在文件中也不占据空间。
.code段(text)
代码段在内存中被映射为只读。它是由编译器在编译链接时自动计算的。通常是用来存放程序执行的指令。代码段输入静态内存分配。
Section’s name
系统预定义了一些节名(以.开头),这些节有其特定的类型和含义。

段和节

ELF文件结构(动态)
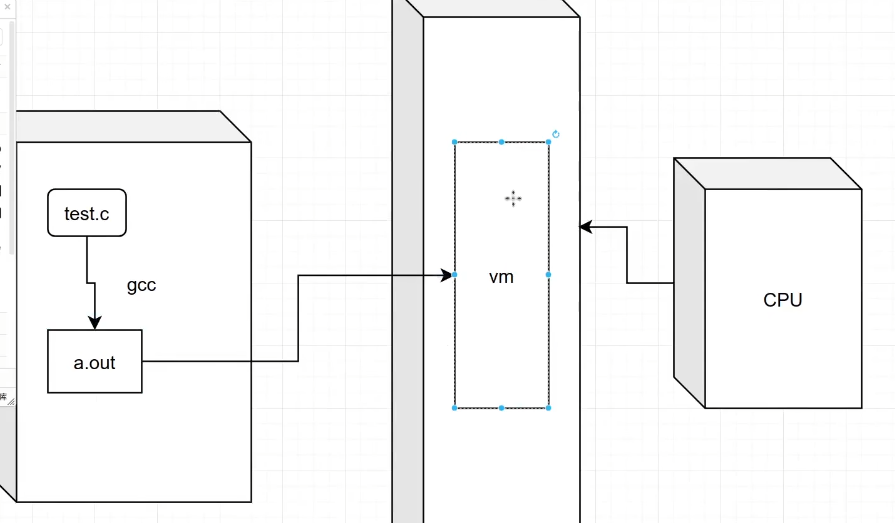
CPU是只能访问主存数据,a.out也不是原封不动的给内存,而是通过一个复杂的装载过程成了虚拟内存映像

.got里面存放的是地址,不可执行,.plt里存放的是代码,不可修改,可执行
code段也可以叫text段,.rodata最后被放入code段最主要的原因它没有被写入的权限

虚拟内存
地址以字节编码
- 虚拟内存用户空间每个进程一份
- 虚拟内存内核空间所有进程共享一份
- 虚拟内存 mmap 段中的动态链接库仅在物理内存中装载一份
物理内存地址其实不连续,为了方便程序员调试出了虚拟内存抽象层
32为的系统,虚拟内存空间的大小是4GB
出现32的地方就会有4G的限制

3G的用户空间1G的内核空间

桌面环境本质上也是一个用户软件,光Linux没有gnu,仅仅是个操作系统内核而非操作系统
GCC是——GNU编译器套装,那么问题来了,GNU又是啥?操作系统
Linux与其他GNU软件结合,完全自由的操作系统正式诞生。许多程序员参与了Linux的开发与修改,也经常将Linux当成开发GNU计划软件的平台。该操作系统往往被称为“GNU/Linux”或简称Linux。但Linux本身不属于GNU计划的一部分
Arch Linux,它是最受欢迎的 Linux 发行版之一,其他还有Debian,Ubuntu。
内核起到管理硬件作用,内核代码运行在内核空间中
不同进程占据物理内存一定空间,用不着没几个进程就把linux内核往物理内存拷贝一份,一份就行,其它共享
glibc在物理内存中也只占一份

堆空间满足用户动态申请的空间,malloc
mmp:映射一个外部文件,外部数据
栈:协助程序流转移和恢复。栈用来管理函数的执行流程,最经典的是递归函数,每次递归栈中会写入函数的地址


这样理解符合直觉
CPU与进程的执行
C语言程序执行内存组织形式

全局变量glb不占用存储空间,但会占用内存空间
“hello world”是只读数据,不可写和执行,因此放在代码段中
str放在Data段中:这跟字符串的性质有关,字符串是不可变的,所有对字符串的操作实质都是重新创建了个字符串,而不是去改变原本的字符串
局部变量:栈
堆:数组
xy存哪具体看系统,x86的老版本可能存在Stack,一些其它的可能存在寄存器
大端序与小端序
pwn中大部分是小端序

进程的执行

寄存器存储中间运算的结果,因为放回主存代价太大
寄存器结构

这张图出错了,RIP存放的是下一条指令的地址
x86入门一般pwn入门
amd64是向下兼容x86的,研究透amd64,x86问题不大
大体关系是amd64/2寄存器大小就是x86
程序装载与汇编
静态链接和动态链接
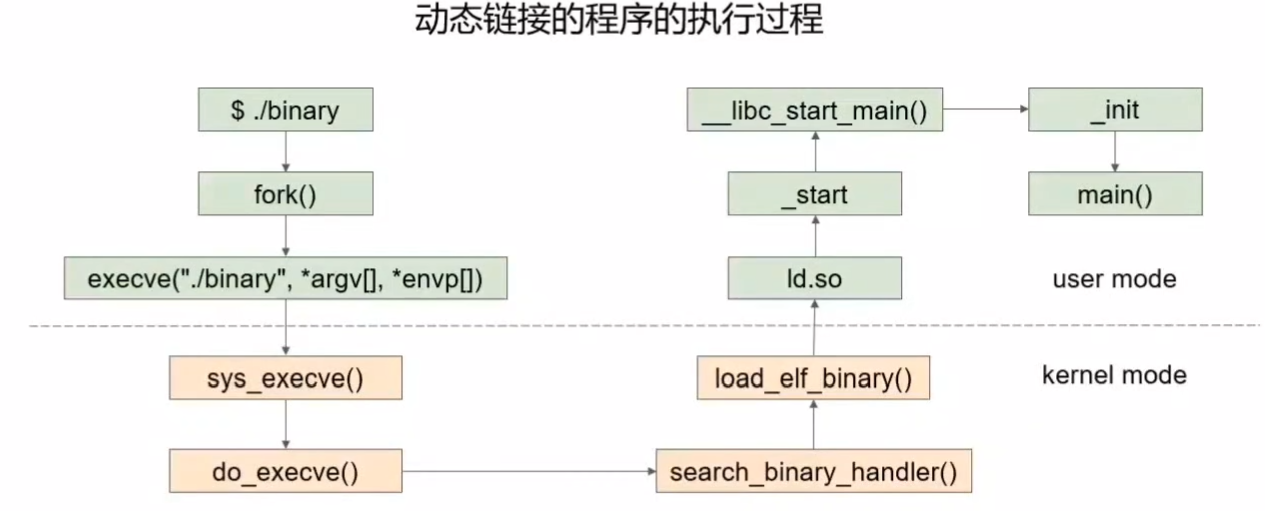
静态链接的程序执行过程

$ ./binary:程序还没执行的时候

LSB小端序。动态链接,解释器,哪个内核编译,hash,调试信息
fork()是将当前进程复制一份,之后执行execve()用新的可执行二进制文件代码替换新进程的代码,以此创建新进程
内核执行那的几个函数
静态链接使用同一个库函数,会存储两边,同时装载时也会存储两份
类似于硬链接和复制粘贴
load_elf_binary:当需要运行一个程序时,则扫描这个队列,依次调用各个数据结构所提供的load处理程序来进行加载工作,ELF中加载程序即为load_elf_binary,内核中已经注册的可运行文件结构linux_binfmt会让其所属的加载程序load_binary逐一前来认领需要运行的程序binary,如果某个格式的处理程序发现相符后,便执行该格式映像的装入和启动
内核中实际执行execv()或execve()系统调用的程序是do_execve(),这个函数先打开目标映像文件,并从目标文件的头部(第一个字节开始)读入若干(当前Linux内核中是128)字节(实际上就是填充ELF文件头,下面的分析可以看到),然后调用另一个函数search_binary_handler(),在此函数里面,它会搜索我们上面提到的Linux支持的可执行文件类型队列,让各种可执行程序的处理程序前来认领和处理。如果类型匹配,则调用load_binary函数指针所指向的处理函数来处理目标映像文件。
在ELF文件格式中,处理函数是load_elf_binary函数,下面主要就是分析load_elf_binary函数的执行过程(说明:因为内核中实际的加载需要涉及到很多东西,这里只关注跟ELF文件的处理相关的代码)
其流程如下
- 填充并且检查目标程序ELF头部
- load_elf_phdrs加载目标程序的程序头表
- 如果需要动态链接, 则寻找和处理解释器段
- 检查并读取解释器的程序表头
- 装入目标程序的段segment
- 填写程序的入口地址
- create_elf_tables填写目标文件的参数环境变量等必要信息
- start_kernel宏准备进入新的程序入口
静态链接
在我们的实际开发中,不可能将所有代码放在一个源文件中,所以会出现多个源文件,而且多个源文件之间不是独立的,而会存在多种依赖关系,如一个源文件可能要调用另一个源文件中定义的函数,但是每个源文件都是独立编译的,即每个*.c文件会形成一个*.o文件,为了满足前面说的依赖关系,则需要将这些源文件产生的目标文件进行链接,从而形成一个可以执行的程序。这个链接的过程就是静态链接
以下面这个图来简单说明一下从静态链接到可执行文件的过程,根据在源文件中包含的头文件和程序中使用到的库函数,如stdio.h中定义的printf()函数,在libc.a中找到目标文件printf.o(这里暂且不考虑printf()函数的依赖关系),然后将这个目标文件和我们hello.o这个文件进行链接形成我们的可执行文件

静态链接的缺点很明显,一是浪费空间,因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖,如多个程序中都调用了printf()函数,则这多个程序中都含有printf.o,所以同一个目标文件都在内存存在多个副本;另一方面就是更新比较困难,因为每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。但是静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。
动态链接
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序
假设现在有两个程序program1.o和program2.o,这两者共用同一个库lib.o,假设首先运行程序program1,系统首先加载program1.o,当系统发现program1.o中用到了lib.o,即program1.o依赖于lib.o,那么系统接着加载lib.o,如果program1.o和lib.o还依赖于其他目标文件,则依次全部加载到内存中。当program2运行时,同样的加载program2.o,然后发现program2.o依赖于lib.o,但是此时lib.o已经存在于内存中,这个时候就不再进行重新加载,而是将内存中已经存在的lib.o映射到program2的虚拟地址空间中,从而进行链接(这个链接过程和静态链接类似)形成可执行程序。
前面我们讲过静态链接时地址的重定位,那我们现在就在想动态链接的地址又是如何重定位的呢?虽然动态链接把链接过程推迟到了程序运行时,但是在形成可执行文件时(注意形成可执行文件和执行程序是两个概念),还是需要用到动态链接库。比如我们在形成可执行程序时,发现引用了一个外部的函数,此时会检查动态链接库,发现这个函数名是一个动态链接符号,此时可执行程序就不对这个符号进行重定位,而把这个过程留到装载时再进行。
汇编
| Base | index | scale |
|---|---|---|
| 0 | 2 | 4 |
偏移地址:0+2*4=8 Displacement,假设位移0X10 8+0x10 = 24 偏移:offset
模2加


正数加正数,不可能等于一个负数,如果出现了,就是溢出。负数加负数,也不可能等于一个正数,如果出现了,
就是溢出。溢出的概念,只发生在有符号数。无符号数,是没有溢出这个概念的。
于是,这就涉及到了,有符号数的大小判断。因为CMP,作的是目的操作数,减去源操作数的一个减法运算。试
想一下,如果目的操作数,是一个正数,而源操作数,是一个负数。那么,正数减去负数,就相当于正数加正数。
有符号数,正数的最高位,是0。但是,两个正数相加,最高位,可能谥出,变成了1。这不就出现了负数了吗。
从,目的操作数,与源操作数的符号(正负),可知,目的操作数为正数,肯定大于负数。结果为,大于。
发生了溢出之后,OF=1。但SF=1(负数)。此时,OF=SF,所以是大于。
 wechat
wechat- alipay








