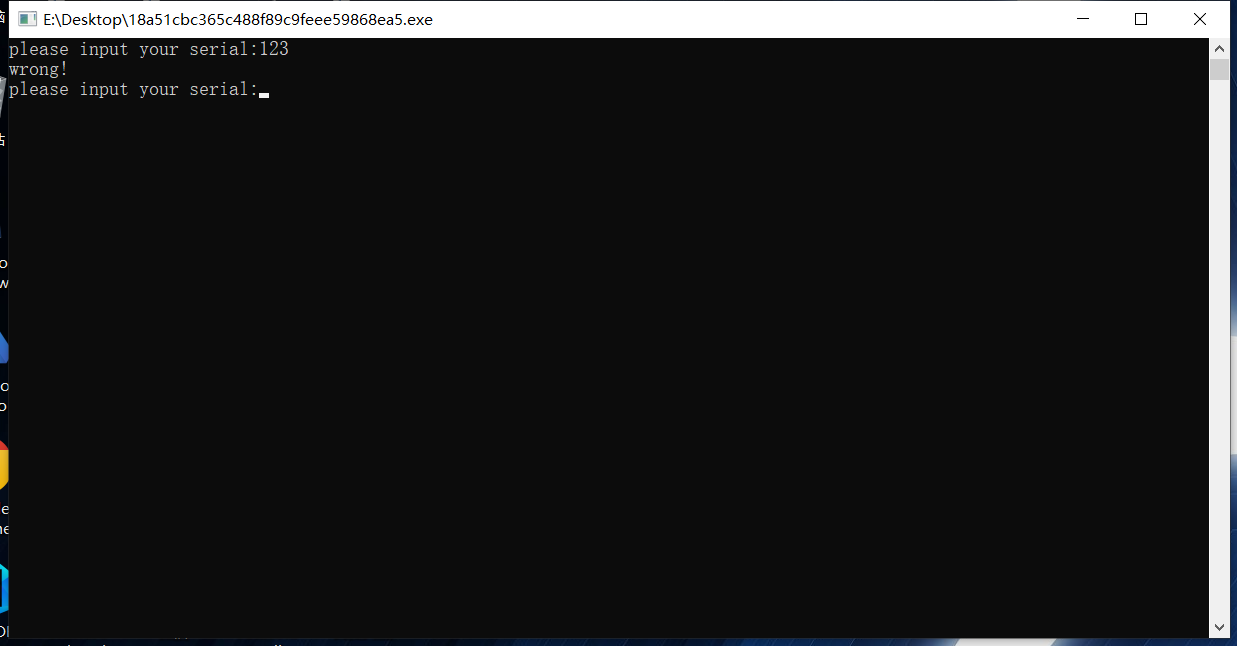
逆向攻防世界CTF系列40-ReverseMe-120
逆向攻防世界CTF系列40-ReverseMe-120
直接定位到关键函数
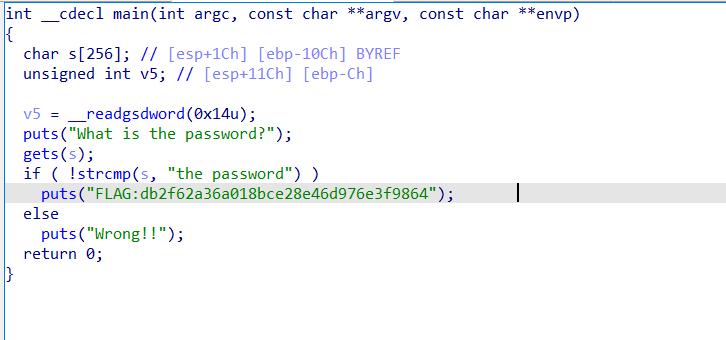
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
you_know_how_to_remove_junk_code提示有垃圾代码,动调了一下,发现if ( v13 )内的代码不执行,跟进sub_401000发现代码逻辑复杂,看不懂。
参考了大佬的wp,这里解释一下。
注意sub_401000main中只传了两个参数,但是跟进后发现四个(可能是隐式传递,放在寄存器里传递了),调试发现a4是输入长度,与最终的you_know_how_to_remove_junk_code比较的是v12(但是并没有被传入),开始怀疑是不是隐式传递了。还有函数结尾的

指针操作需要注意,再进行调试,调试没发现什么,只是变了值,在sub函数内没跟踪到是哪个参数
这里再次看了大佬们的wp

我的是这样的,后来用ida7.5打开是下面那样的

之前我一直只能验证v12是给了ecx,却无法验证ecx给了哪个参数(可能跟我没有细细研究汇编有关,没看懂),只好换版本,也就是v12传给了a1(如果换版本的话,v12就变成v13,我还是按v12来讲吧,我用的是ida8.3)有点乱,其实就是如果是ida7.5的话a1a2跟ia8.3的顺序是反的,然后变量名也不一样
ps:琢磨了一下,发现如果是函数调用的话,其实这样已经可以说明了a1是edx,a2是ecx,然后调用函数,涨知识了

已经知道了v12是我们的传入,这里已经完全可以猜到a2是v13了,当然看汇编也可以看到edx的变化
然后就是看sub函数逻辑了
看ida8.3,不知道从何下手,然后看了汇编

发现有个ecx的赋值操作,说明这里反汇编少了

sub_401000(v12, &v13, (unsigned __int8 *)v11, strlen(v11))
1 | v12 = a1; |
这段上面的代码可能是垃圾代码,但我又不清楚v6的作用

有个数组v16 = byte_414E40[v15];

说是base64码表,没看出来(太菜)
ub_401000函数内对v13的主要操作代码说是base64解密操作,在一篇博客中可以有很好的理解和对比

2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
// base64.c
// base64
//
// Created by guofu on 2017/5/25.
// Copyright © 2017年 guofu. All rights reserved.
//
/**
* 转解码过程
* 3 * 8 = 4 * 6; 3字节占24位, 4*6=24
* 先将要编码的转成对应的ASCII值
* 如编码: s 1 3
* 对应ASCII值为: 115 49 51
* 对应二进制为: 01110011 00110001 00110011
* 将其6个分组分4组: 011100 110011 000100 110011
* 而计算机是以8bit存储, 所以在每组的高位补两个0如下:
* 00011100 00110011 00000100 00110011对应:28 51 4 51
* 查找base64 转换表 对应 c z E z
*
* 解码
* c z E z
* 对应ASCII值为 99 122 69 122
* 对应表base64_suffix_map的值为 28 51 4 51
* 对应二进制值为 00011100 00110011 00000100 00110011
* 依次去除每组的前两位, 再拼接成3字节
* 即: 01110011 00110001 00110011
* 对应的就是s 1 3
*/
// base64 转换表, 共64个
static const char base64_alphabet[] = {
'A', 'B', 'C', 'D', 'E', 'F', 'G',
'H', 'I', 'J', 'K', 'L', 'M', 'N',
'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z',
'a', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't',
'u', 'v', 'w', 'x', 'y', 'z',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'+', '/'};
// 解码时使用
static const unsigned char base64_suffix_map[256] = {
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 253, 255,
255, 253, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 253, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 62, 255, 255, 255, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 255, 255,
255, 254, 255, 255, 255, 0, 1, 2, 3, 4, 5, 6,
7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
19, 20, 21, 22, 23, 24, 25, 255, 255, 255, 255, 255,
255, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36,
37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255 };
static char cmove_bits(unsigned char src, unsigned lnum, unsigned rnum) {
src <<= lnum; // src = src << lnum;
src >>= rnum; // src = src >> rnum;
return src;
}
int base64_encode(const char *indata, int inlen, char *outdata, int *outlen) {
int ret = 0; // return value
if (indata == NULL || inlen == 0) {
return ret = -1;
}
int in_len = 0; // 源字符串长度, 如果in_len不是3的倍数, 那么需要补成3的倍数
int pad_num = 0; // 需要补齐的字符个数, 这样只有2, 1, 0(0的话不需要拼接, )
if (inlen % 3 != 0) {
pad_num = 3 - inlen % 3;
}
in_len = inlen + pad_num; // 拼接后的长度, 实际编码需要的长度(3的倍数)
int out_len = in_len * 8 / 6; // 编码后的长度
char *p = outdata; // 定义指针指向传出data的首地址
//编码, 长度为调整后的长度, 3字节一组
for (int i = 0; i < in_len; i+=3) {
int value = *indata >> 2; // 将indata第一个字符向右移动2bit(丢弃2bit)
char c = base64_alphabet[value]; // 对应base64转换表的字符
*p = c; // 将对应字符(编码后字符)赋值给outdata第一字节
//处理最后一组(最后3字节)的数据
if (i == inlen + pad_num - 3 && pad_num != 0) {
if(pad_num == 1) {
*(p + 1) = base64_alphabet[(int)(cmove_bits(*indata, 6, 2) + cmove_bits(*(indata + 1), 0, 4))];
*(p + 2) = base64_alphabet[(int)cmove_bits(*(indata + 1), 4, 2)];
*(p + 3) = '=';
} else if (pad_num == 2) { // 编码后的数据要补两个 '='
*(p + 1) = base64_alphabet[(int)cmove_bits(*indata, 6, 2)];
*(p + 2) = '=';
*(p + 3) = '=';
}
} else { // 处理正常的3字节的数据
*(p + 1) = base64_alphabet[cmove_bits(*indata, 6, 2) + cmove_bits(*(indata + 1), 0, 4)];
*(p + 2) = base64_alphabet[cmove_bits(*(indata + 1), 4, 2) + cmove_bits(*(indata + 2), 0, 6)];
*(p + 3) = base64_alphabet[*(indata + 2) & 0x3f];
}
p += 4;
indata += 3;
}
if(outlen != NULL) {
*outlen = out_len;
}
return ret;
}
int base64_decode(const char *indata, int inlen, char *outdata, int *outlen) {
int ret = 0;
if (indata == NULL || inlen <= 0 || outdata == NULL || outlen == NULL) {
return ret = -1;
}
if (inlen % 4 != 0) { // 需要解码的数据不是4字节倍数
return ret = -2;
}
int t = 0, x = 0, y = 0, i = 0;
unsigned char c = 0;
int g = 3;
while (indata[x] != 0) {
// 需要解码的数据对应的ASCII值对应base64_suffix_map的值
c = base64_suffix_map[indata[x++]];
if (c == 255) return -1;// 对应的值不在转码表中
if (c == 253) continue;// 对应的值是换行或者回车
if (c == 254) { c = 0; g--; }// 对应的值是'='
t = (t<<6) | c; // 将其依次放入一个int型中占3字节
if (++y == 4) {
outdata[i++] = (unsigned char)((t>>16)&0xff);
if (g > 1) outdata[i++] = (unsigned char)((t>>8)&0xff);
if (g > 2) outdata[i++] = (unsigned char)(t&0xff);
y = t = 0;
}
}
if (outlen != NULL) {
*outlen = i;
}
return ret;
}可以看到base64_suffix_map跟我们这个数组一模一样
分析完整个函数,知道函数sub_401000是base64解码函数了,得到的信息是程序将你的输入—->base64解码—->得到v13。

猜i>0x10不成立
写解密代码
1 | import base64 |
XEpQek5LSlJ6TUpSelFKeldASEpTQHpPUEtOekZKQUA=
提交然后过了,你以为结束了吗?
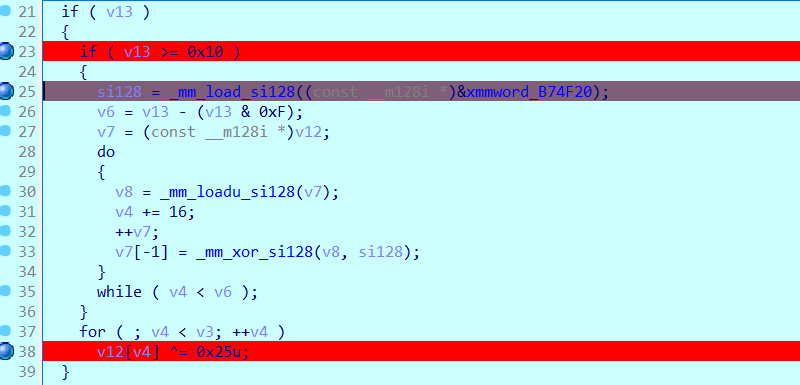
输入flag发现进入了if内部,还发现了^并没有执行
查了一下啊
这段代码实现了一种基于 SIMD(Single Instruction, Multiple Data)的优化操作,使用了 Intel 的 SSE 指令集(Streaming SIMD Extensions),用于快速处理数据
1 | v7 = (const __m128i *)v12; |
SEE指令,参考(https://www.jianshu.com/p/d718c1ea5f22)
load(set)系列,用于加载数据,从内存到暂存器。
__m128i _mm_load_si128(__m128i *p);
__m128i _mm_loadu_si128(__m128i *p);
store系列,用于将计算结果等SSE暂存器的数据保存到内存中。
void _mm_store_si128 (__m128i *p, __m128i a);
void _mm_storeu_si128 (__m128i *p, __m128i a);
_mm_load_si128函数表示从内存中加载一个128bits值到暂存器,也就是16字节
注意:p必须是一个16字节对齐的一个变量的地址。返回可以存放在代表寄存器的变量中的值。
_mm_loadu_si128函数和_mm_load_si128一样的,但是不要求地址p是16字节对齐。
store系列的_mm_store_si128和_mm_storeu_si128函数,与上面的load系列的函数是对应的。 表示将__m128i 变量a的值存储到p所指定的地址中去。
_mm_xor_si128用于计算128位(16字节)的按位异或,然后通过v14控制循环结束的条件,可以看到v14增长的步长为16,而且通过上面得到的flag值解码得到的字符串为32个字节大小,正好是16的整数倍。
听不懂理解为迭代器就行了,虽然这个比喻并不恰当
enc长度是32位,看一下si128

可以理解为16位16位的迭代,这段代码会被迭代两次
恰好完成之前未被执行的那段代码的功能
 wechat
wechat- alipay