
Android-Flutter逆向原理及实战
Android-Flutter逆向原理及实战
文章原理部分参考:Android-Flutter逆向 | LLeaves Blog
最近实战逆向一些APP发现都有用到flutter,因此学习下flutter逆向,本文预计包括flutter介绍,flutter例题,flutter实战逆向几部分
Flutter介绍
Flutter 是由 Google 推出的一个跨平台 UI 开发框架,最早在 2017 年发布。它允许开发者使用一套代码同时构建Android、iOS、Web、Windows、macOS、Linux 等多个平台的应用。Flutter 的核心语言是 Dart。
从逆向角度看,Flutter 与传统 Android 应用(Java/Kotlin + XML UI)在结构上差异非常大,因此分析方法也不同。
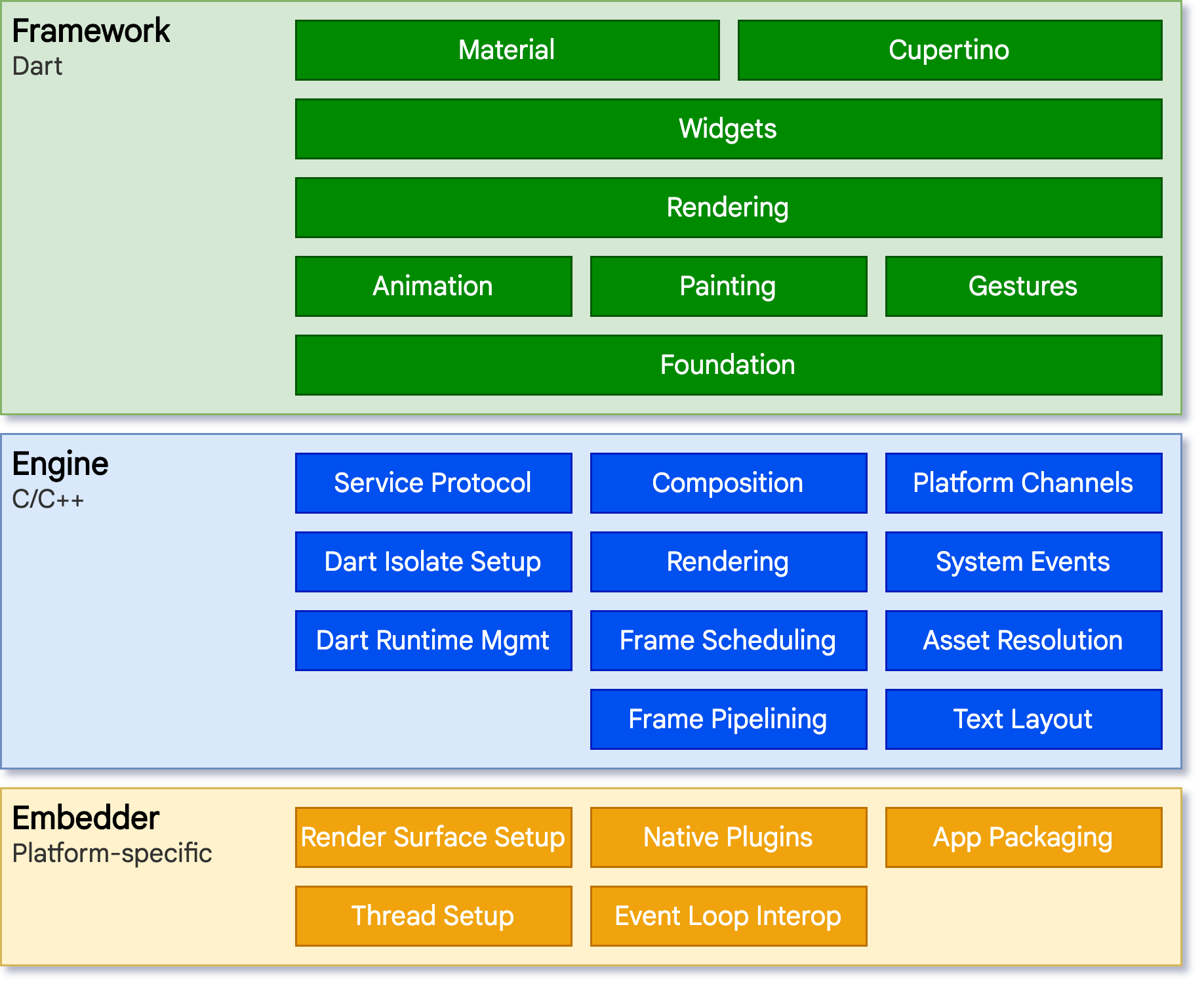
Flutter的基本架构
Flutter 的架构大致分为三层:
Framework(Dart 层):这是开发者主要编写代码的地方,全部使用 Dart
Flutter框架层,开发者可以通过 Flutter框架层 与 Flutter 交互,该框架提供了以 Dart 语言编写的现代响应式框架。Flutter框架相对较小,因为一些开发者可能会使用到的更高层级的功能已经被拆分到不同的软件包中,使用 Dart和 Flutter的核心库实现
主要包含:
- Widget 层:Flutter 的 UI 构建方式
- Rendering 层:布局与绘制逻辑
- Animation / Gesture:动画与手势系统
Flutter 的 UI 不是 XML,而是通过 Widget Tree 构建,例如:
1 | MaterialApp |
这些 Widget 最终会被转换为 RenderObject 并交给底层绘制。
Engine(C++ 层)
Flutter引擎是一个用于高质量跨平台应用的可移植运行时,由C/C++编写。它实现了Flutter的核心库,包括动画和图形、文件和网络I/O、辅助功能支持、插件架构,以及用于开发、编译和运行Flutter应用程序的Dart运行时和工具链。引擎将底层C++代码包装成 Dart代码,通过dart:ui暴露给 Flutter框架层。
主要组件:
- Dart VM
- Skia 图形引擎
- 文本布局
- GPU 渲染
- 平台通道(Platform Channel)
Flutter 的 UI 不是使用 Android 原生控件,而是:
1 | Dart Widget |
因此 Flutter UI 全部是自己绘制的。
这也是为什么:
uiautomator很难识别控件- Android Layout Inspector 基本无效
Embedder
Flutter可以通过一套代码在多个平台使用依靠着嵌入层,嵌入层采用了适合当前平台的语言编写,例如 Android使用的是 Java和 C++, iOS 和 macOS 使用的是 Objective-C 和 Objective-C++,Windows 和 Linux 使用的是 C++。嵌入层提供一个程序入口,程序由此可以与底层操作系统进行协调。
mbedder 是平台适配层,例如 Android 上:
1 | FlutterActivity |
Flutter Engine 会通过 Embedder 与系统交互,例如:
- Surface / OpenGL / Vulkan
- 输入事件
- 生命周期
- Platform Channel
Flutter APK的典型结构

Flutter Android APK 通常包含几个关键文件:
1 | lib/ |
最关键的是libflutter.so是Flutter 引擎
包含:Dart VM,Skia,Runtime
一般 所有 Flutter APP 共用同一套 engine。
libapp.so是 应用逻辑的 AOT 编译结果。
在 release 模式下:
1 | Dart → AOT → native code → libapp.so |
因此:
- 没有 Dart 源码
- 没有 Java 逻辑
- 业务代码在
libapp.so
Flutter 逆向的核心就是分析 libapp.so
flutter_assets有资源文件
Flutter编译模式
Dart AOT
Release Flutter APP 会把 Dart 编译成 native code:
1 | Dart → Kernel → AOT → ARM64 |
因此没有源码,函数名被去掉,类型信息消失
Flutter使用Dart作为应用程序开发编程语言,因此Flutter的编译模式与Dart的编译模式相关。下面这张表总结了Dart的编译模式。
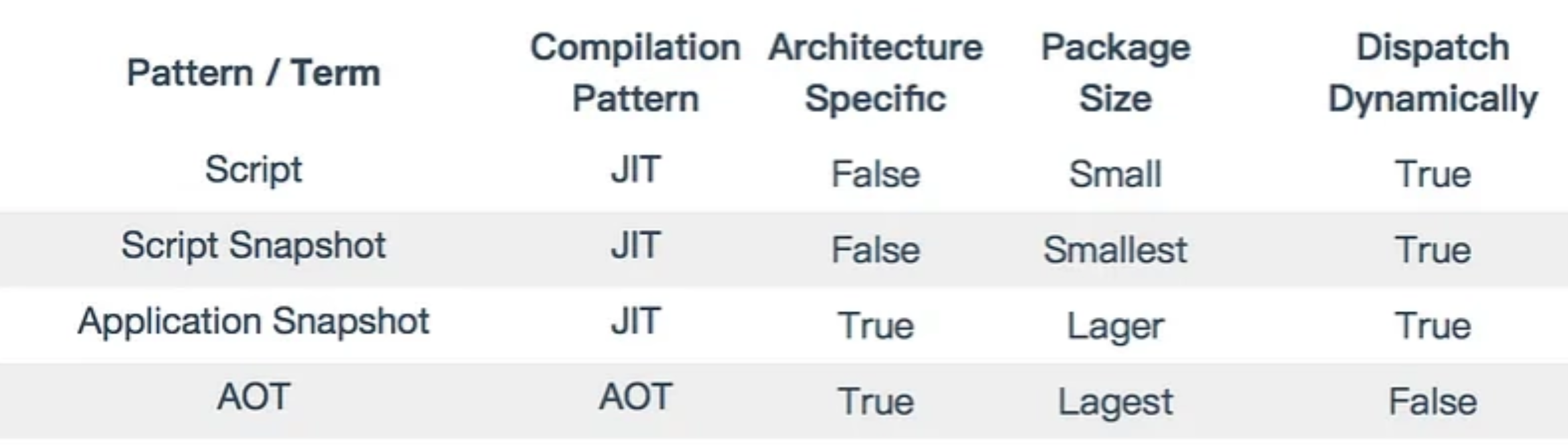
| 类型 | 含义 |
|---|---|
| Script | 最常见的JIT模式。就像Node.js一样,可以通过Dart VM命令行工具直接执行Dart源代码 |
| Script Snapshot | Dart 源码的运行时快照,JIT模式。与Script模式不同,Script Snapshot会将源代码打包成代码的Token形式,这可以节省了在编译时词法分析器所花费的时间。 |
| Application Snapshot | 完整应用快照,JIT模式。Dart的Application Snapshot有点像运行时的转储。它包含了从源代码解析的类和函数,所以运行时可以更快地进行加载和执行。但是这种快照与架构相关,在IA_32上生成的快照无法在X64平台上运行。 |
| AOT | 提前编译为机器码,在这种模式下,Dart源代码会被翻译成汇编文件,然后汇编文件由汇编器为不同架构编译成二进制代码。 |
对于Flutter,其在上述编译模式的基础上进行了调整
Script和Script Snapshot:与
Dart的模式一样,但Flutter从未使用过。Kernel Snapshot:对应用代码进行中间字节码(Dart kernel格式)快照。通过避免Dart代码重新编译来实现移动端的快速启动,类似于Java字节码与JVM,核心快照是不依赖于体系架构的。
Core JIT:
Dart编译代码的一种二进制格式。程序数据和指令打包成特定的二进制格式,供Dart运行时加载。实际上该模式 是一种 AOT 模式。AOT Assembly:即Dart的AOT模式,完全AOT预编译的本地代码。
Dispatch Dynamically(是否支持动态调用)
这一列是逆向时很重要的一点。
| 类型 | 是否支持动态分发 |
|---|---|
| Script | True |
| Snapshot | True |
| AOT | False |
动态分发是什么意思
例如 Dart:
1 | dynamic obj; |
如果是 JIT:运行时可以决定调用哪个函数。
但 AOT 编译后:
1 | call 0x123456 |
函数地址已经固定。
因此:AOT 会失去很多动态信息。
Flutter release APK 使用 AOT 的原因:
- 启动更快
- 不需要 JIT 编译器
- 安全策略(iOS 不允许 JIT)
在开发阶段,开发Android App时,为了实现热重载技术加速UI的开发,Flutter在这个阶段使用Kernel Snapshot 模式,即核心快照模式。在编译生成的app-deug.apk 中的资源目录下存在isolate_snapshot_data vm_snapshot_data 以及kernel_blob.bin ,前两个文件分别用于加速isolate启动,加速dart_vm启动,最后一个文件为业务代码的字节码。在lib目录中还存在libflutter.so,即flutter动态链接库,与实际业务代码无关。
Flutter逆向
com from LLeaves
使用readelf -s命令读取保存快照信息的libapp.so将会输出下面的内容
1 | Symbol table '.dynsym' contains 6 entries: |
_kDartVmSnapshotData: 代表 isolate 之间共享的 Dart 堆 (heap) 的初始状态。有助于更快地启动 Dart isolate,但不包含任何 isolate 专属的信息。
Isolate 是 Dart 运行时中的 基本执行单元。可以把它理解为一个完全隔离的运行环境,类似轻量级进程,而不是传统意义上的线程。
在 Dart 设计中:
- 每个 isolate 拥有自己的内存(heap)
- 每个 isolate 有独立的全局变量
- 每个 isolate 有自己的事件循环
- isolate 之间 不能直接共享对象
因此 Dart 的并发模型不是传统的 共享内存 + 锁,而是 隔离 + 消息传递。
Dart 为了避免这些问题,采用了 Actor Model 的思想。
也就是:
2
3
4
heap A heap B
| |
---- message ----特点:
- 没有共享内存
- 只能 通过消息通信
Flutter 里为什么几乎只有一个 Isolate
在 Flutter 应用中通常结构是:
2
3
│
main isolate (Flutter UI / business logic)VM isolate:Dart VM 内部使用的管理 isolate。
main isolate:Flutter 应用真正执行代码的 isolate。
因为 Flutter UI 需要:
- 单线程渲染
- 事件循环
- 顺序执行
所以 Flutter 默认只使用一个业务 isolate。
如果需要后台任务,才会手动创建 isolate。
_kDartVmSnapshotInstructions:包含 VM 中所有 Dart isolate 之间共享的通用例程的 AOT 指令。这种快照的体积通常非常小,并且大多会包含程序桩 (stub)。
_kDartIsolateSnapshotData:代表 Dart 堆的初始状态,并包含 isolate 专属的信息。
_kDartIsolateSnapshotInstructions:包含由 Dart isolate 执行的 AOT 代码。
其中_kDartIsolateSnapshotInstructions 是最为重要的,因为包含了所有要执行的AOT代码,即业务相关的代码。
Dart VM中所有的代码都运行在一些isolate内,isolate可以看作是一个隔离的Dart执行环境,有自己的全局状态和通常自己的执行线程(mutator线程)。isolate被组织成isolate group ,同一个组内的isolate共享同一个垃圾回收堆,用于存储该isolate组分配的对象。
在Flutter 中,不会使用多个isolate,除了始终存在的 VM isolate之外,只使用一个isolate
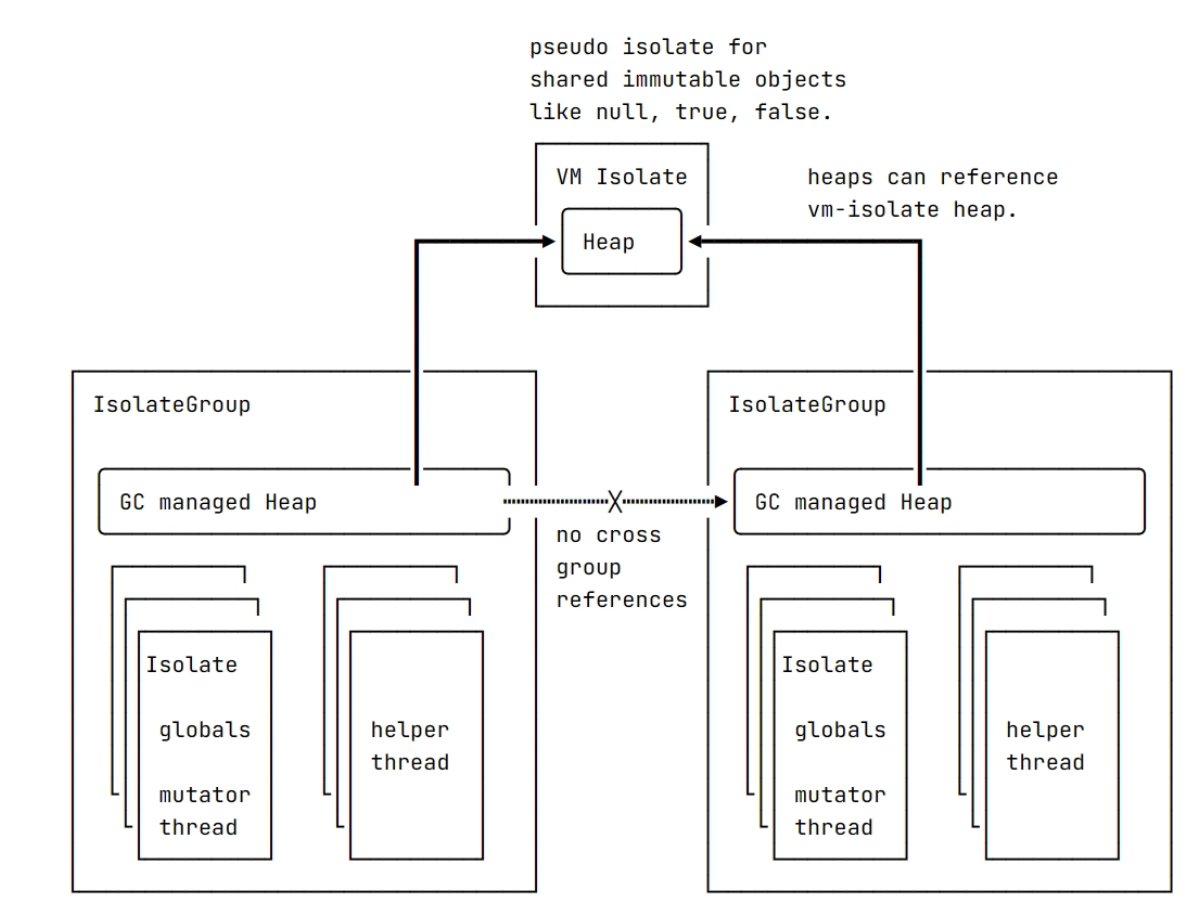
Isolate中维护了堆栈变量,函数调用栈帧,用于GC、JIT等辅助任务的子线程等, 而这里的堆栈变量就是要被序列化到磁盘上的东西,即IsolateSnapshot。此外像dart预置的全局对象,比如null,true,false等等等是由VMIsolate管理的,这些东西需序列化后即VmSnapshot。
最初快照不包括机器代码,但是后来在开发AOT编译器时添加了此功能。开发 AOT 编译器和带代码的快照的动机是允许在由于平台级别限制而无法进行 JIT 的平台上使用 VM。带代码的快照的工作方式与普通快照几乎相同,但略有不同:它们包含一个代码部分,与快照的其余部分不同,它不需要反序列化。此代码段的铺设方式允许它在映射到内存后直接成为堆的一部分。dart源码中runtime/vm/app_snapshot.cc处理快照的序列化和反序列化
在 Dart VM 里,运行一个 Dart 程序至少需要两类东西:
A. 对象堆的初始状态也就是一堆 VM 需要的对象,类对象、字段描述、字符串、常量、ICData/metadata、以及应用里用到的各种对象图等。
- VM 级共享:跨 isolate 共用的那部分 →
VmSnapshotData- 某个 isolate 专属:应用相关的那部分 →
IsolateSnapshotDataB. 代码的初始状态
最初快照确实主要是 data(对象堆),机器码不在快照里;后来为了 AOT,快照加入了代码段,对应:
VmSnapshotInstructions:VM 共享的 stub / 通用例程(一般很小)IsolateSnapshotInstructions:应用 AOT 产生的机器码(业务逻辑的主体)为什么带代码的快照可以不反序列化代码段
code section 与快照其余部分不同,它不需要反序列化;映射到内存后直接成为堆的一部分。
直观理解:
- Data 部分:本质是对象图。里面有大量指针/引用关系,保存到磁盘时通常会变成 偏移/索引,加载时需要 重建对象、修复指针、补全引用 ——这就是反序列化的工作。
- Code 部分(AOT 指令):本质是一段 已经可执行的机器码。只要它的布局设计成“加载地址无关”或“可重定位/可打补丁”,就可以通过
mmap映射后直接执行,不必像对象那样重建。data 需要反序列化;instructions 更像一个可执行的镜像段,加载后做少量修补即可。
(逆向上就会看到:
_kDartIsolateSnapshotInstructions指向一块很大的.text/ROX 类似区域,而_kDartIsolateSnapshotData指向更像 blob 的数据段。)app_snapshot.cc 在做什么(序列化/反序列化的核心流程)
runtime/vm/app_snapshot.cc(以及它相关的几个文件)大体在做三件事:1 生成快照(Serialize / Write)
目标:把启动一个 isolate 所需的对象堆 +(可选)AOT 代码打包成两个 blob(data + instructions)。
典型步骤可以抽象为:
- 遍历对象图从一组根出发(例如 isolate 的 object store、class table、常量池等),把所有可达对象标记/收集。
- 给对象分配快照内的编号/偏移因为写到磁盘不能直接写内存指针,所以会把引用改写成 指向某个已写对象的ID/offset。
- 写出对象内容对不同类型对象有不同编码方式(小整数、字符串、数组、Class、Function、Field…),并记录必要的元信息。
- (AOT 情况)写出代码段把 AOT 产生的
Code/指令区域,按照 VM 约定的布局写入 instructions blob(或直接引用已生成的段)。可以把它理解为:一次把堆拍扁成二进制的过程。
2 加载快照(Deserialize / Read)
目标:把磁盘上的 blob 恢复成内存中可用的对象与代码,使 isolate 进入“可运行状态”。
典型步骤抽象为:
- 读取 header / 校验 BuildId:
_kDartSnapshotBuildId就是为了校验 快照与 VM 版本/编译参数匹配,不匹配直接拒绝加载。- 反序列化 data(重建对象堆)
- 分配内存空间
- 按顺序创建对象实例
- 把“对象引用ID/offset”修复成真实指针
- 初始化 isolate 的 object store / class table 等
- 装载 instructions(代码段)
- 这块通常不会“逐对象反序列化”
- 更接近:把 code blob 映射到内存(mmap/拷贝)后,做必要的 重定位/patch
- 把 data 里的 Code 对象与 instructions 段关联起来:对象堆里会有
Code对象,它需要指向实际的机器码入口地址,这个阶段会把地址填上。最终效果是:
- 反序列化后:Dart 的类、函数、字符串等都在堆里了
- 代码段映射后:函数入口能跳到实际机器码了
- VM 可以直接从
main/ entrypoint 开始跑3 VM Snapshot vs Isolate Snapshot的分工
app_snapshot.cc处理的是应用快照相关(更偏 isolate/app),但它会遵循整体模型:
- VM snapshot:负责共享区(基础对象、stub 等)
- Isolate snapshot:负责应用区(业务类/函数/常量 + 大量 AOT code)
一般情况下要想获取更多关于业务代码相关的信息,可以:
静态解析ibapp.so,即写一个解析器,将libapp.so中的快照数据按照其既定格式进行解析,获取业务代码的类的各种信息,包括类的名称、其中方法的偏移等数据,从而辅助逆向工作。(Blutter)
动态编译修改过的ibflutter.so并且重新打包到APK中,在启动APP的过程中,由修改过的引擎动态链接库将快照数据获取并且保存。
Impact-I/reFlutter: Flutter Reverse Engineering Framework (github.com)
第二种方法详细请参考Android-Flutter逆向 | LLeaves Blog
现在主要静态可以使用Blutter比较方便,(注意我用的是kali 2022) 其他可能会出现对gcc版本的要求的问题,很难处理
WMCTF VNCTF 2023 BabyAnti
WMCTF2023 VNCTF2023 BabyAnti 分析 | Matriy’s blog
WMCTF2025 Want2BecomeMagicalGirl
WMCTF2025 Want2BecomeMagicalGirl复现 | Matriy’s blog
Flutter 抓包
这里选用reqable
关掉系统代理(只抓手机)
手机扫码连接,注意关闭电脑防火墙

flutter抓包和普通APK抓包区别
如果只是安装了系统证书(system CA)就能解密大部分 Flutter 请求,其实这是完全正常的情况,也说明App并没有严格的 SSL pinning。关键点在于 Flutter 的证书信任模型。
Flutter App 可能混合使用:
| 网络来源 | TLS来源 |
|---|---|
| Flutter HttpClient | BoringSSL |
| WebView | Android TLS |
| 第三方SDK | OkHttp |
很多 App 不是全局 pinning,而是只对关键接口 pinning
例如:
1 | api.payment.com |
其他接口:
1 | cdn |
不做 pinning。
Flutter App 抓包和普通 Android APK 抓包最大的区别在于TLS/证书校验实现的位置不同,因此会出现有些请求能看到响应、有些 SSL handshake 失败的情况。核心原因通常是Flutter 自带 TLS 栈 + 证书校验策略不同。下面我详细解释
普通 Android App(Java/Kotlin)通常使用:
HttpURLConnectionOkHttpVolleyRetrofit
这些库底层调用 Android 系统 TLS (Conscrypt / BoringSSL)。
因此:
- 安装抓包证书(Reqable / Charles / Burp)
- 系统信任该 CA
- HTTPS MITM 成功
- 可以看到明文 HTTP
1 | APP->Android TLS (系统) - > 信任用户CA-->代理工具MITM -->抓包成功 |
Flutter不是走 Android 系统 TLS。
Flutter 使用的是 Dart VM 内置的 HttpClient,底层是BoringSSL,并且很多版本:
- 不信任系统用户证书
- 或者使用自带证书验证逻辑
Flutter网络路径:
1 | Flutter App -> Dart HttpClient --> Flutter BoringSSL -> 证书验证 |
因此即使安装了抓包 CA Flutter也不信任,就会出现SSL Handshake failed
为什么会出现部分请求成功
可能结构是:
1 | Flutter App |
Flutter 抓包的常见解决方案
方法1:Frida Hook
Hook Flutter TLS 验证函数:
常见 hook 点:
1 | ssl_verify_peer_cert |
或者 Dart 层:
1 | badCertificateCallback |
常用脚本:
1 | flutter_ssl_bypass.js |
方法2:patch libflutter.so
直接:
1 | patch libflutter.so |
修改:
1 | ssl_verify_peer_cert |
返回成功。
方法3:使用专门工具
例如:
- objection
- frida-flutter
- reFlutter
Flutter逆向实战-某豆APP
分析的版本是5.5.3 当前已更新5.5.6 每个版本的包名什么的都不一样,因此分析还挺麻烦的,如果版本变了,大家看个思想就行了换汤不换药.
sign分析前言
为什么要分析signature?
一、判断 APK 是否被重新打包(防二次打包)
Android APK 在安装时必须经过 开发者私钥签名。
如果别人反编译 → 修改 → 重新打包,那么:
- 新 APK 必须重新签名
- 签名 一定会变化
因此很多应用会在运行时做类似检查:
1 | 获取当前应用的 signature |
常见代码逻辑:
1 | PackageManager pm = getPackageManager(); |
然后:
1 | SHA1(signature) |
再和硬编码的值比较。
逆向者如果想修改 APK,就必须:
- patch 掉 signature check
- 或伪造 signature 返回值
二、用于服务端认证
很多 APP 会把 签名 hash 作为客户端身份的一部分。
例如请求接口时:
1 | device_id |
服务器会检查:
1 | signature_hash == 官方签名 |
如果修改了 APK:
- 重新签名
- signature_hash 不一样
服务器就能识别出非官方客户端。
三、Android 的权限模型依赖 signature
Android 有一种权限叫:
1 | signature permission |
只有 相同签名的 APP 才能互相访问。
比如:
1 | android:protectionLevel="signature" |
一些系统 APP / SDK / 插件框架 会利用这一点。
如果想:
- 注入模块
- 调用隐藏 API
- 访问内部服务
就必须伪造或绕过 signature 校验。
四、很多安全壳也依赖 signature
很多壳会做类似检查:
1 | 1. 检查 APK signature |
signature 是最简单的一层
sign分析
可以看到被混淆了

/user/info

1 | POST /api/app/user/info HTTP/1.1 |
编辑了部分data信息 不能直接复制

1 | D:\Matriy\Desktop\VN\output>findstr /s /i /n "timestamp=" *.* |
可以看到这些字符串,有了 pp 偏移但没用,还没把它转换成加载这个 pp 槽位的指令模式(IDA中的数据是无法交叉引用的)
我是按抓包定输入 -> pp.txt 定对象池簇 -> 请求拦截器定调用点 -> 反汇编闭包定字段顺序 -> 本地回代验证这条链,把 sign 算法收出来的。
x-api-key是 timestamp=…;sign=…;nonce=…
我们按上面可以搜一下,在flutter里字符串不会直接在代码里裸引用,而是通过 PP,object pool取。所以交叉引用基本没用,要看 pp.txt。
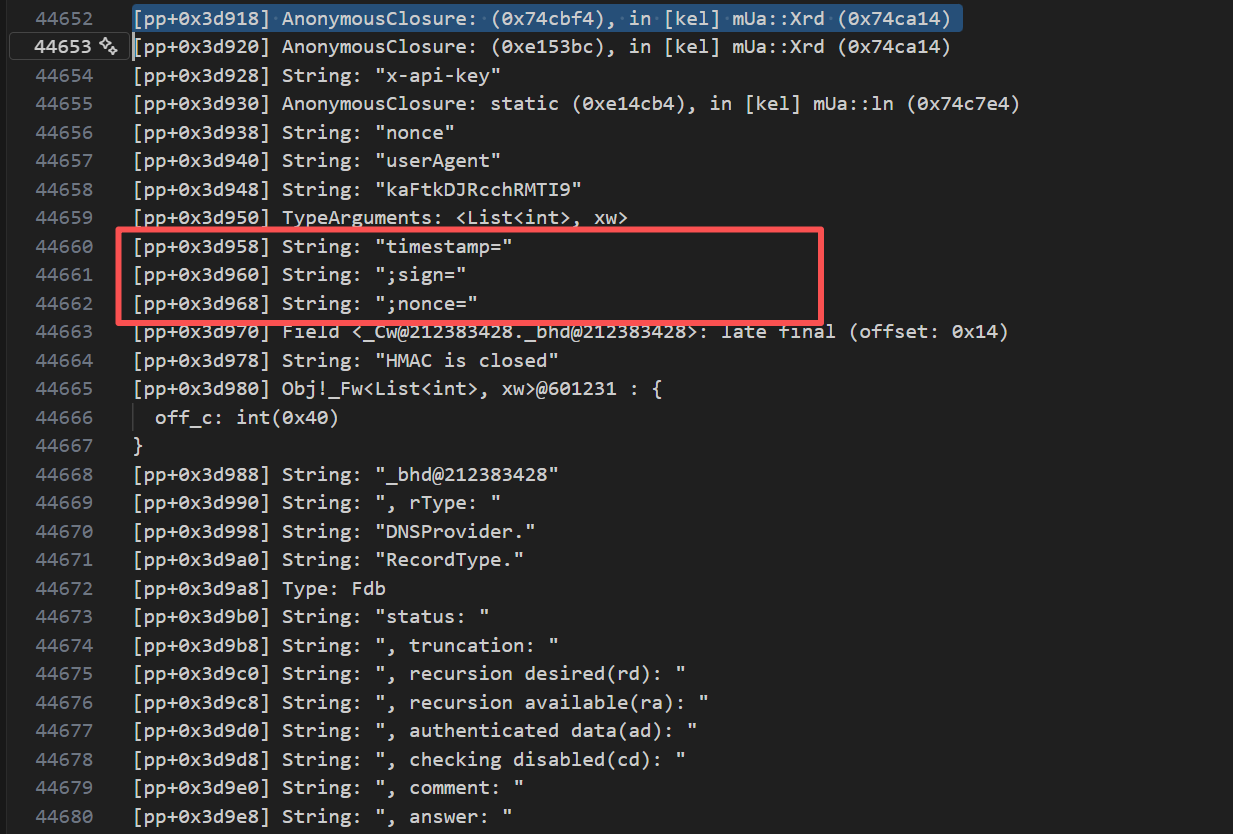
在pp.txt:44652到pp.txt:44668中
- x-api-key
- nonce
- userAgent
- kaFtkDJRcchRMTI9
- timestamp=
- ;sign=
- ;nonce=
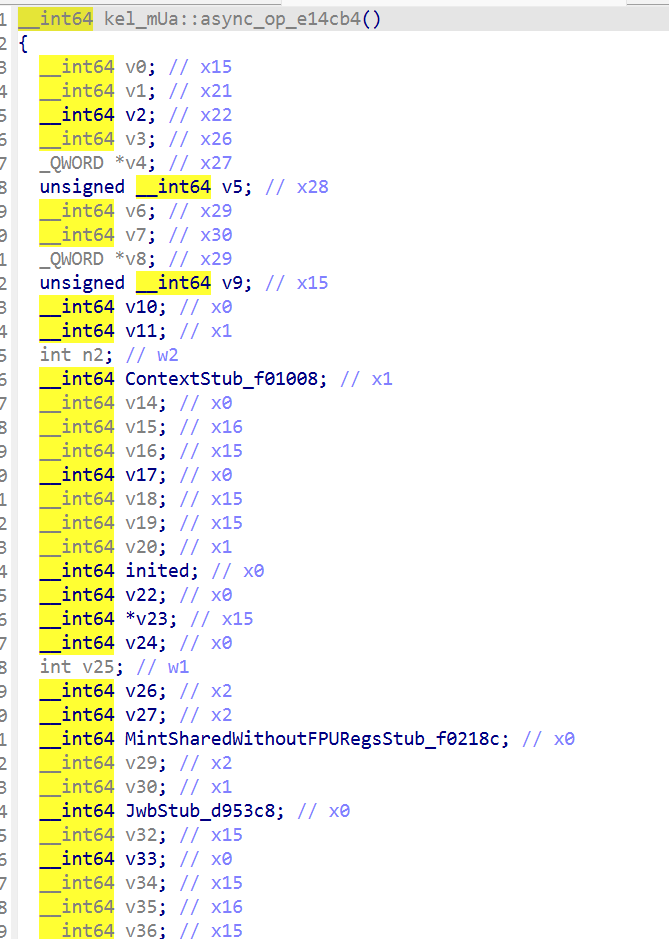
- HMAC is closed
这组字符串全部贴在 [kel] mUa::Xrd (0x74ca14) 和 [kel] mUa::ln (0x74c7e4) 周围,把这两个函数当成签名核心,mUa::Xrd / mUa::ln 非常可疑
真正的判断,是靠代码里对 pp+offset 的实际加载确认的,Flutter AOT 里 x27 通常就是 PP。所以看到这种指令
1 | add x17, x27, #0x3d, lsl #12 |
就等价于load [pp+0x3d958]
定位到kel.dart
kel.dart 空,不代表 [kel] 这条链不存在。这份 blutter 导出对 kel 这个库的正文恢复失败了,只留下了一个库壳和几个类型壳
可以根据0x74c7e4看下native层

kel_mUa::ln_74c7e4() 本身不是真正的签名算法体,它是一个 async 外壳。它在函数内部明确创建并调度了一个闭包,而这个闭包在 pp.txt:44655 里已经标成了:[pp+0x3d930] AnonymousClosure: static (0xe14cb4), in [kel] mUa::ln (0x74c7e4)
1 | 74c88c ADD X1, X27, #0x3D,LSL#12 |
这说明 kel_mUa::ln_74c7e4 从对象池加载了 [pp+0x3d930],然后创建了一个 closure。而 pp.txt:44655 明确[pp+0x3d930] 就是 static (0xe14cb4)。
0x74c7e4主要是:
分配 Context
分配 Future
填 async state
创建 closure
启动 async 调度
0x74c7e4 外壳
0xe14cb4 真正闭包体
伪代码里的 v4[n] 对应对象池 [pp+8*n]。所以例如:
- v4[31527] = [pp+0x3d938] = “nonce”
- v4[31528] = [pp+0x3d940] = “userAgent”
- v4[31529] = [pp+0x3d948] = “kaFtkDJRcchRMTI9”
- v4[31531] = [pp+0x3d958] = “timestamp=”
- v4[31532] = [pp+0x3d960] = “;sign=”
- v4[31533] = [pp+0x3d968] = “;nonce=”
- v4[1148] = [pp+0x23e0] = “path”
- v4[1353] = [pp+0x2a48] = “timestamp”
- v4[15095] = [pp+0x1d7b8] = “token”
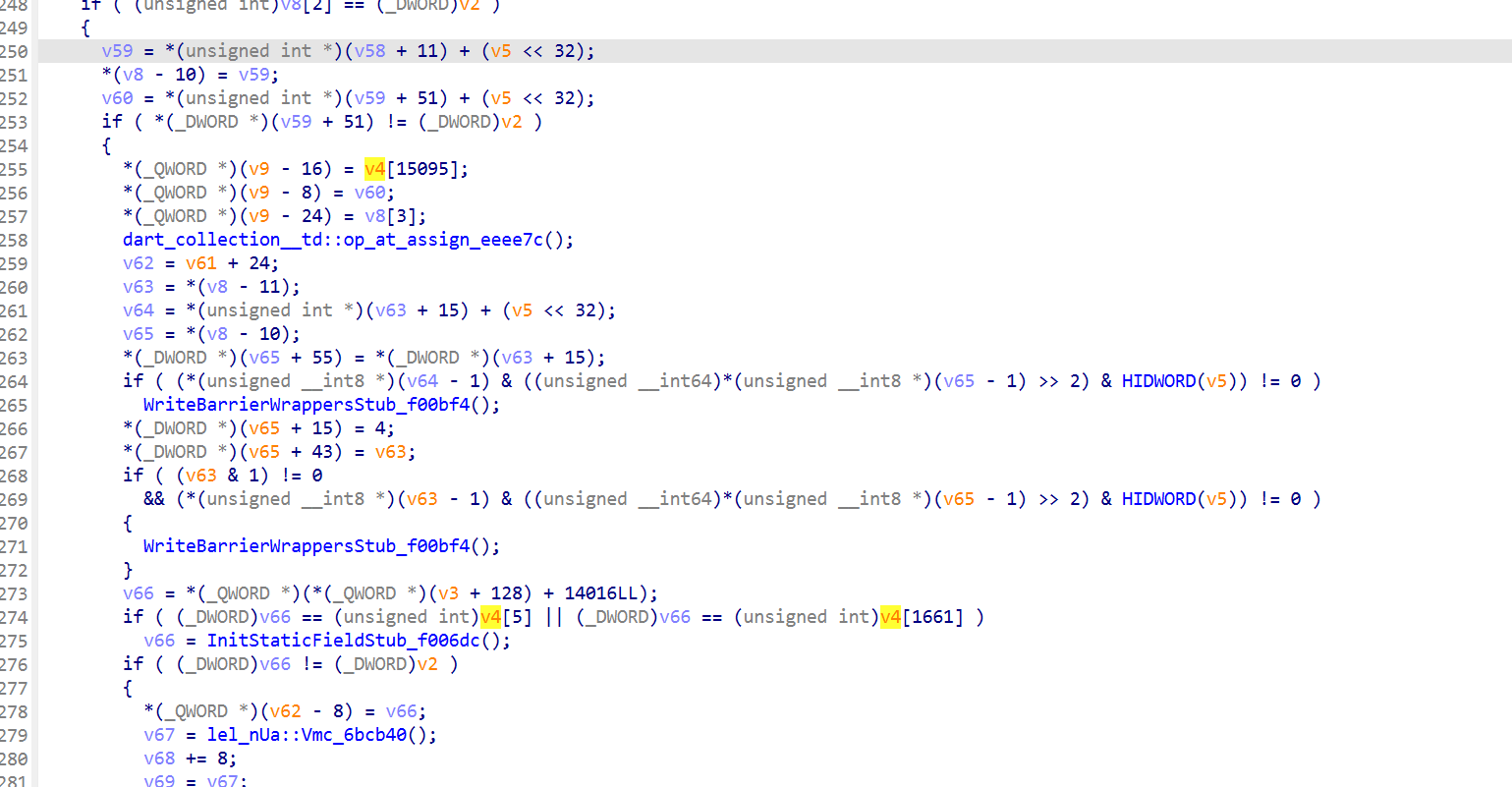
如

可以对应到token,然后看 0xe14cb4 的流程:
1. 0xe14d14 调 `dart_core_Map__factory_ctor__fromLiteral`说明它先建了一个 Map。
2. 0xe14e14 到 0xe14e24,加载 [pp+0x3d938] "nonce",然后把 sub_6BB9B8() 生成的值塞进去。这就是 nonce,uuid生成16 字节随机 -> 版本位/variant 位修正 -> 8-4-4-4-12 格式化。
3. 0xe14e44 到 0xe14e50,加载 [pp+0x23e0] "path",值来自调用上下文。这是请求路径。
4. 0xe14da0 到 0xe14dc8 先把时间做 /1000/1000,变成秒级时间戳;0xe14ea0 到 0xe14eac 再加载 [pp+0x2a48] "timestamp" 把它写进 Map。这是 timestamp。
5. 0xe14f08 到 0xe14f10 调 lel_nUa::Gmh_6bcdf8.这是 token getter。后面 0xe14f90 到 0xe14fa4 用 [pp+0x1d7b8] "token" 把它写进 Map。
6. 0xe15038 到 0xe15040 调 lel_nUa::Vmc_6bcb40,这是 user-agent getter。前面 0xe150a8 那段会用 [pp+0x3d940] "userAgent" 把它写进 Map。
后半段:
0xe150c8 到 0xe150d4,取 [pp+0x3d948] “kaFtkDJRcchRMTI9”,这是签名 key 常量。
0xe15144 到 0xe1514c 调 sub_74C948,这个函数里有:
分配 Uint8Array,判断 key 长度是否 > 64,超过就先做一次压缩,这是典型的HMAC key预处理。
0xe15158 到 0xe15160,调 sub_B78D3C,这是把消息喂进去拿摘要的那一步。
0xe151a4 到 0xe151ac,调 sub_AF49D0。这一步输出的正是 digest 的 hex 字符串,用它对应到了最后 40 位 hex 的 sign。
0xe1517c 到 0xe15268,分配一个字符串数组,然后按顺序塞:
[pp+0x3d958] “timestamp=”
[pp+0x3d960] “;sign=”
[pp+0x3d968] “;nonce=”
0xe15264 到 0xe15268,调
dart_core__StringBase___interpolate_cd7da0,把上面这些片段拼成最终 header 值,timestamp=<ts>;sign=<hex>;nonce=<uuid>
HMAC(Hash-based Message Authentication Code,基于哈希的消息认证码)是一种结合了哈希函数和密钥的加密算法,用于验证消息的完整性和真实性。它通过将消息和一个秘密密钥作为输入,生成一个唯一的哈希值(认证码)。这种方法广泛应用于安全通信协议(如HTTP、SSL、SSH)以及密码存储和会话管理等场景。
Iel Del Sel里都有User-Agent

Iel中还有Api-version

优先看Iel.dart
发现asm/Iel.dart:474 bl #0x74cb7c
0x74cb7c似乎是统一请求拦截器,发送前处理的流程,发包前的统一补头 + 进入签名链
由此可以写出解密代码
1 | import json |
发包代码:
1 | import time |
data数据解密
逆了很久,流程是:
1. 外层响应先进入 jel_lUa::async_op_db5328
2. 成功码分支里检查 hash
3. hash == true 时,进入 sub_6F6FF0 -> sub_6F695C -> sub_EE0A50
4. sub_6F6FF0 产出固定 secret:vEukA&w15z4VAD3kAY#fkL#rBnU!WDhN
5. sub_6F695C 做真正的通用解密
6. sub_EE0A50 把明文 JSON 字符串转成 Dart Map
7. 后面才是各接口自己的业务 parser,比如 /user/info 的 parseUser
sub_6F695C 最终还原出的公式是:
1 | raw = base64.b64decode(data) |
hook脚本用的是blutter_frida.js,这个脚本现在只保留了解密分析相关点位:
因为dart和native层实在太屎了,要配合fridahook验证
- envelope 分支:0xdb5a10 / 0xdb5a90
- 通用解密:0x6f6ff0 / 0x6f695c
- 三次 digest:0xb7881c
- 最终材料:keyReady / cipherSliceReady / ivReady
- JSON 入口:0xee0a50
- 业务 sink:parseUser
一开始用的接口data测试是/user/info,一开始只根据这个接口无法单独验证因此我还去抓了其他接口的包
比较惊讶的是居然连frida都不检测,是对自己的产品太自信了嘛 0.0
下面的data其实很长我只截取了一部分,(想试试的后面frida hook部分会有一部分完整的加密数据可以拿去解一下)
catch1.txt
1 | POST /api/app/user/info HTTP/1.1 |
catch2.txt
1 | POST /api/app/media/play HTTP/1.1 |
catch3.txt
1 | POST /api/app/media/like HTTP/1.1 |
这种高熵数据base64解了下 好像是16的倍数,可能是AES相关的加密,也可以以此为线索去找
我下面讲一下我怎么分析的,我一开始先定了两个锚点:
外层响应入口:jel_lUa::async_op_db5328。这是因为响应envelope里有 code / data / hash / msg / time 这些字段
/user/info -> sub_67D774 -> UTa,这是为了找一个最终一定会消费解密结果的地方,不能只盯着高熵base64
当时我的思路不是先找 AES,而是响应谁先碰到 data,哪个业务函数最终消费了解密后的结果,中间缺失的那段,就是通用层(在这里搞了很久,静态分析不出来因此结合hook去分析验证)
/user/info最后会进 sub_67D774,Map -> UTa parser,一旦能确认 sub_67D774 的入参是 Map,就能证明在它之前一定存在一层通用 decode
所以我先顺着 eel__bUa::async_op_d71120 去确认/user/info的真实路径。
当时得到的链是:
1 | d71120 |
然后这里保险起见我进行hook了,在sub_67D774之前,有一条很明显的线:sub_423264 -> 67CE9C -> 67CD58 -> 421200 -> … -> field_b
先后hook了67CE9C/67CD58这两个,验证在它们前后,data 是不是已经从高熵字符串变成对象Map了
日志中decodeStageA.enter/leave 和 decodeStageB.enter/leave 里,caller分别落在:
- /media/v5/home
- /bulletscreen/list
而且打印出来的是请求配置对象、method、path、header 之类的内容,不是响应data,说明 67CE9C/67CD58 虽然在静态链上看着像通用解密,但动态上它们大量参与的是请求侧包装,不是data解密点。
67CE9C/67CD58 被证伪,可以去hook验证db5328,因为它是:
- 最早拿到hash
- 最早拿到raw data,又正好是 envelope success 分支的控制点
也就是说,不管解密发生在哪,db5328 都是最早能看到hash和raw data ,所以把 hook 缩到两个点:
- 0xdb5a10,看 hash 和 data
- 0xdb5a90,看最后塞回 wrapper 的东西是什么
日志中:
- 0xdb5a10:x0=true,x4 是高熵 base64
- 0xdb5a90:x4 已经是 Dart Map
后面去hook EE0A50,有了上一步,已经知道db5328 里某处raw base64 -> Map但还不知道中间是直接在 db5328 里解完,还是只是调别的 helper
静态上 db5328 里最可疑的三段就是sub_6F6FF0,sub_6F695C,sub_EE0A50
其中 EE0A50 很像字符串解析入口,所以去 hook EE0A50 的目的很明确,如果 EE0A50 的入参是明文 JSON 字符串,那它就是 json.loads,那么真正解密就一定发生在它前面的 6F695C
后面jsonParseFromDBh日志显示,x0 已经是完整明文 JSON。
- 6F6FF0:产 secret
- 6F695C:真解密
- EE0A50:JSON parse
接下来去 hook 6F695C 内部,因为到这个阶段,问题已经从链在哪里收缩成:
- key/iv 怎么来的
- 真正密文是哪一段
- 算法是 AES-CBC/PKCS7 还是别的
所以我在沿着 6F695C 内部结构专门打了这些点:
- preDecode
- digestHelper
- keyReady
- cipherSliceReady
- ivReady
- cipherProcess
顺序
- 先拿固定 secret
- 再拿三次 digest
- 再拿最终 key
- 再拿最终 iv
- 再拿送进 cipher 的真实 bytes
后面给回的日志证明了:
- preDecode.leave 固定返回 secret
- keyReady 是 32 字节
- ivReady 是 16 字节
- cipherSliceReady 才是真正 AES 输入
中间注意dart的Smi 比如数据32,其实是16,忘记了绕了一大圈原理可以自己搜索或者在WMCTF2025里面看看
但在 Dart AOT 里,这些很多是 Smi,不是裸整数。24 实际是 12
这个修正一做,很多东西突然全部对上:
- prefix 不是 24,而是 12
- ciphertext 不是 raw[24:-4],而是 raw[12:]
三份包立刻都 block对齐了:
- 4204 - 12 = 4192
- 1628 - 12 = 1616
- 31372 - 12 = 31360
然后我做的是:
- 用 live 日志里 data 的前几个base64字符,先还原出前12字节 prefix
- 用静态汇编推测digest输入结构
- 本地试算,看能不能命中hook出来的 key/iv
第一次试的时候,出现了一个很关键的现象:
- h3 相关部分全对
- h2 相关部分不对
这说明:
- seed = secret + prefix
- mid = h1[8:24]
- h3 = sha256(seed[22:] + mid)
这些已经是对的,错的是第二次 digest 的输入。重新回到 6a80 附近看栈传参,才发现之前又少看了一步:
- 不是直接 sha256(firstHalf(seed))
- 而是先把 mid 加进 growable
- 再把 firstHalf(seed) 加进去
所以正确的是h2 = sha256(mid + seed[:22])
hook代码,后面的不用动
1 | const ShowNullField = false; |
告诉AI让它搓一份解密代码
1 | from __future__ import annotations |

frida vip hook
这块比较困难,当时没给data解密(以为搞不出来了),先做的hook,发现单纯hook对象或者实际逻辑加大了逆向的难度,能去看响应体能够更好的辅助逆向
因为有了userinfo解密后的对象,这样hook起来就比较方便了,我起先是hook了vipright,viplevel,viptype,vipexpiretime等用户模型字段,但是发现hook这些虽然改变了用户等级(能够访问vip界面),但是vip视频仍旧无法观看
然后分析了下接口

研究了下大概是这样的,当用户从大厅列表进入视频页后,会发一个post请求给服务端,然后我们这会去GET得到一个视频列表,流媒体格式,感兴趣的话可以去看看推特怎么传输视频的,以m3u8的形式返回一个视频列表,当然这里跟twitter的不同点是这里还进行了加密,虽然很简单
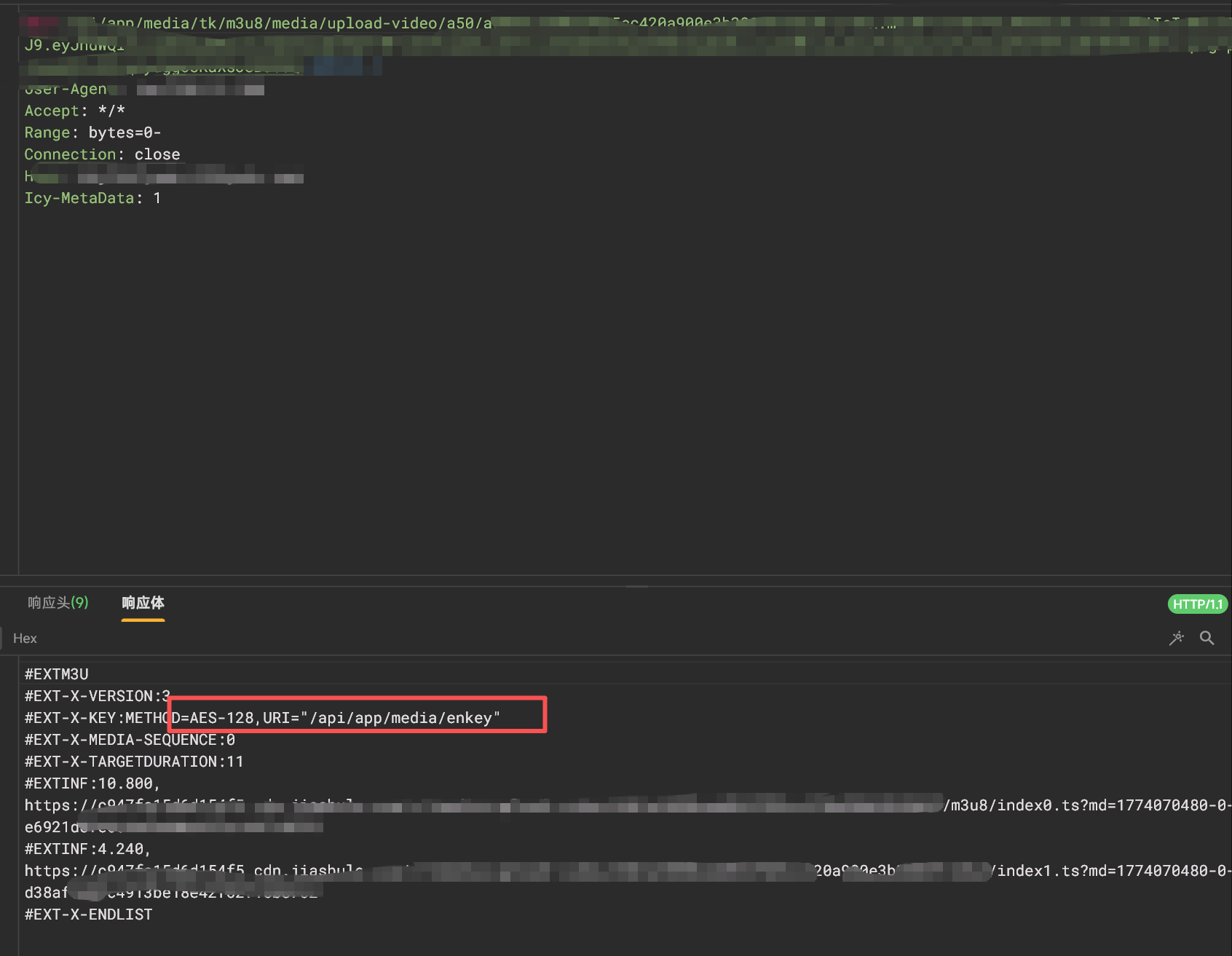
key很简单也是明文的
这里没必要去搞它,如果感兴趣的话也可以研究一下
上面m3u8对应的视频列表会发过来
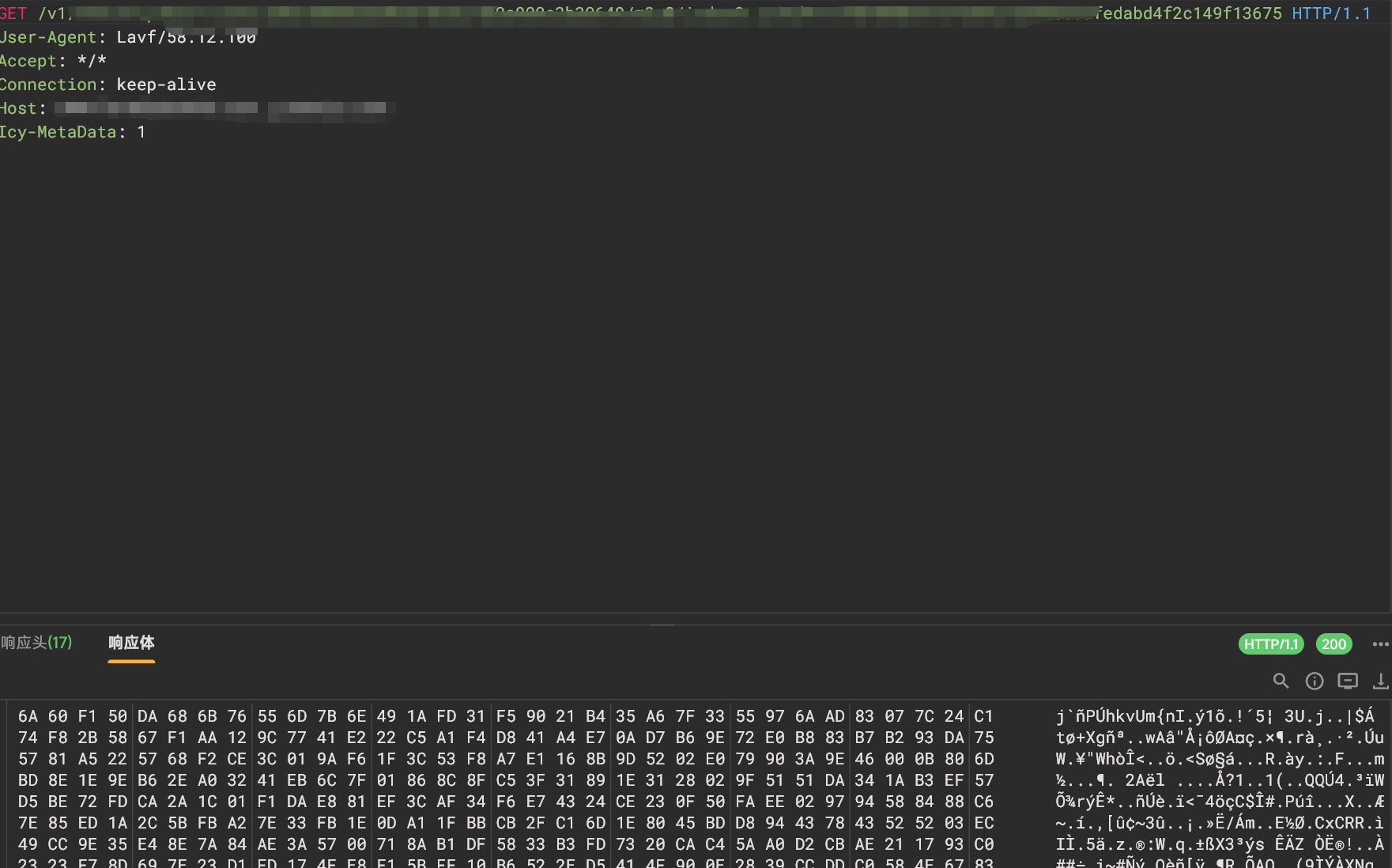
弄清楚这点后我重点关注之前的/media/play的post请求,到底post了啥,导致发回来这玩意,(这里我没有截断字节,想试试的朋友们)
1 | { |
解出来后是这样的(我手动改了下,想看完整版的自己解用之前的脚本)
1 | {"mediaInfo":{"id":xxx,"channelId":xxx,"channelName":"xxx","channelAvatar":"xxx.png","channelFans":31702,"channelWorks":6220,"title":"牛逼","videoType":1,"videoTypeV2":6,"videoUrl":"xxxb4d2782xxx0.m3u8","preVideoUrl":"xxx33cf24b4d2782d7e679ed4521xxx1.m3u8","tags":[""],"tagList":[{"id":,"name":""},{"id":,"name":""},{"id":,"name":""},{"id":,"name":""},{"id":,"name":""}],"coverImg":"v3/image/2rj/72/2wv/1m1/xxx.jpg","coverImgV2":"","desc":"","actors":null,"payType":1,"playTime":1274,"preTime":3,"height":1280,"width":720,"price":0,"likes":94,"watchTimes":1463,"comments":38,"sells":0,"scores":20,"score":7.5,"myScore":0,"isLike":false,"isBuy":false,"isNew":false,"isChannel":false,"bango":"","addedTime":"2026-03-05T03:48:47Z","presale":false,"movieDiscount":100,"subscribeId":0,"isSubscribe":false,"vipLevel":0,"discountDesc":"","publishId":0,"publishName":"","publishAvatar":"","publishCared":false,"createdAt":"2026-02-19T04:01:54.356Z","canDownload":false,"timeNode":null},"jointGroup":null,"watchCount":0,"movieTickets":0,"playable":false,"preSale":false,"preSaleBuy":false,"preSalePrice":0,"preSaleDiscount":0,"code":6032,"msg":""} |
有个重大发现”videoUrl”:”xxxb4d2782xxx0.m3u8”,”preVideoUrl”:”xxx33cf24b4d2782d7e679ed4521xxx1.m3u8”
如果我们能把preVideoUrl替换为videoUrl的链接不久发回来的是完整视频而不是预览视频了嘛
这里需要这样做是因为可能实际上改Vip不够(可能有服务端校验)
此思路是我逆向之前一个普通app来的,大家感兴趣也可以去看看
Android实战-逆向某li某li视频APP | Matriy’s blog
但是还是踩坑了我对其数据对象进行了注入却忽略了一个问题,注入时机不对,这个App比如说我注入了,但是注入太晚,这个preVideoUrl已经分配到很多地方了,导致又纠正了,因此我一开始的想法是顺着这个接口找到,刚收到响应,解密完的时机去进行hook,直接改,后来审计代码的时候无意间发现这个code和playable有点可疑,直接摸到解密完的时机去进行hook这两个字段成功了
把解密后的 /media/play 响应从不可播放 + 6032改成了可播放 + 200,url 那层只做兜底
然后成功hook了
frida代码(blutter_frida那些重复部分没加,也是hook了非常多的地方,有些地方其实是无效的,懒得改了)
1 | const ShowNullField = false; |
如果有持久化的需求可以用算法助手注入frida代码,亲测可行
Xposed模块构建
但是由于需要hook native层,需要使用LSPosed + native hook,具体构建xposed项目按下面之前的文章所示
某节拍APP逆向+XPosed模块编写 | Matriy’s blog
此外native hook需要额外参考LSPosed-Native层Hook 夏洛魂的个人博客
添加如下属性
1 | <application |
额外在assets下创建一个native_init,写入so库的名称,自己的
MainHook.java,负责作为 LSPosed Java 入口,在目标进程加载时System.loadLibrary(“madou”)调用 native 入口
hook_entry.cpp负责处理
native_init,监听libapp.so,计算libapp.so基址,安装 native hook,维护 Dart AOT 运行时对象读写 helperjson_parse_bridge.S负责桥接jsonParse,在不破坏 Dart 运行时寄存器现场的前提下,调用 C helper 做响应明文 patch
user_hook_bridges.S负责桥接 parseUser,桥接 getUse,桥接 IsVip,把用户对象层 patch从不安全的裸C++ hook,改成与jsonParse一样的安全桥接方式。
实际持久化还是建议算法助手,我改native的时候崩了好几次
Frida 版之所以稳定,是因为它使用的是:
- Interceptor.attach
- onEnter
- onLeave
也就是说,Frida 只是挂观察点,读取当前函数的寄存器上下文,再在合适时机改参数或返回值。而 native 模块里一开始采用的是:
- 用 hook_func直接把目标函数入口替换成一个 C++ 函数
- 在 C++ 函数里调用 backup trampoline
- 然后继续写 Dart 对象
这两种方式看起来都叫hook,但对 Flutter AOT / Dart runtime 来说差别非常大。而Dart AOT 对寄存器使用非常敏感,从 jsonParse、parseUser、getUser、isVip 的反汇编能看到,x15 不是普通临时寄存器,而是 Dart 的栈 / frame 相关寄存器,x26/x27/x28也都承载了 runtime 上下文,x22 还参与 Null/true/false 常量对象定位,如果直接把函数入口替换成普通 C++ 函数,编译器会按 AArch64 C ABI 自己用寄存器,Dart 运行时依赖的现场可能在进入 backup trampoline 之前就被破坏,这也是为什么Frida 版稳定
解决方案
为了解决寄存器现场污染问题,最终采用了与 Frida 思路更接近的结构
汇编桥负责保存现场 -> 调 helper -> 恢复现场 -> 跳回原 trampoline,C helper 只负责高层逻辑判断和对象 patch。也就是把危险的寄存器现场处理与业务 patch 逻辑拆开。如jsonParse桥接方案最终加入了json_parse_bridge.S,madou_on_json_parse_enter(…)
桥接逻辑大致是:
保存关键寄存器:
x0-x4,x15,x26-x28,x30调用 madou_on_json_parse_enter(json_tagged, return_address, x28)
在 helper 中:
用 x28 << 32恢复 heap base,用返回地址计算 caller offset,只允许0xdb5a70和0xdb5c50,识别是否是 /media/play 的解密明文 JSON。若命中,则在 jsonParse 前对字符串做等长原地 patch
恢复寄存器现场
br 到 backup trampoline
这样就实现了行为上接近 Frida onEnter,但部署形式是原生 so hook
其实就是Frida帮你隐式做了这层上下文保护,native inline hook 没做,所以我们自己用汇编桥把这层补上了,更准确地说,不是Xposed hook 不保存现场,而是,现在用的是 LSPosed native hook_func这类inline hook,我最开始写的是用普通 C/C++ 函数直接替换目标函数入口,这种写法会按标准 AArch64 C ABI 运行
AArch64 C ABI 是 ARM 64 位架构下,C 语言函数调用的规则标准
但 Flutter/Dart AOT 的这些函数,额外依赖 x15/x22/x26/x27/x28 这类 runtime 寄存器,所以一旦直接进普通 C++,编译器就可能把这些寄存器现场弄脏,而 Frida 的 Interceptor.attach 更像是在函数前后挂观察点,框架保留上下文,读 this.context、改参数/返回值,但不会把整个 Dart 函数改造成一个普通 C++ 函数
所以差异核心是Frida attach更接近旁路观察/前后插桩。最初的 native hook更接近整个函数入口被一个普通 ABI 的替身函数接管。这对 Dart AOT 就很危险bridges.S 做的事,本质上是手动保存关键寄存器现场调一个普通 C helper 去做高层逻辑再把现场恢复最后跳回原 trampoline 或返回结果,把 Dart 运行时依赖的寄存器环境恢复回去,这样原函数和运行时会觉得现场没有被普通 C++ 污染过。
下面会议json的那个桥为例解释
完整代码:
java层
1 | package com.xx.madouviphook; |
CmakeList.txt
1 | cmake_minimum_required(VERSION 3.22.1) |
LSPlant.h
1 | typedef int (*HookFunType)(void *func, void *replace, void **backup); |
user_hook_bridges.S
1 | .text |
json_parse_bridges.S
第一段:保存现场
1 | sub sp, sp, #0x50 #在 原生栈 sp 上开 0x50 字节空间 |
stp 是一次存两个寄存器
这里保存的是:
- x0-x4:原函数参数
- x30:返回地址
- x15:Dart 很敏感的栈/frame 寄存器
- x26-x28:Dart runtime 上下文寄存器
这里的关键点是: 我们不用 Dart 的 x15 做栈,而是临时借用原生 sp 保存现场,避免碰坏 Dart 自己的栈语义。
第二段:调用 helper
1 | mov x1, x30 |
这里没有动 x0,所以 helper 收到的参数其实是:
- x0:原来的 json_tagged
- x1:当前返回地址 x30
- x2:当前 x28
也就是对应hook_entry.cpp:644 里的:
1 | madou_on_json_parse_enter(uintptr_t json_tagged, |
helper 里做的事是:
- 用 x28 还原 heap base
- 用 return_address 判断 caller 是否是那两条解密链
- 读取 json_tagged 指向的 Dart String
- 如果像 /media/play 响应,就原地改字符串内容
注意:helper 改的是字符串对象指向的内存,不是改 x0 这个寄存器本身。
第三段:恢复现场
1 | ldp x0, x1, [sp, #0x00] |
这就是把刚才保存的值全部恢复回去。恢复完之后,对原始 jsonParse 来说,寄存器现场和没被我们插过 helper几乎一样。
第四段:跳回原 trampoline
1 | adrp x16, g_backup_json_parse_entry |
意思是:
- 从全局变量里取出 backup trampoline 地址
- 如果为空,就走兜底返回 0
- 否则 br x16 直接跳过去
这里特意用的是 br,不是 blr,因为:
- br 是直接跳转,不额外改写返回链
- 我们希望后面的原始 jsonParse -> 原始 caller这条返回路径保持正常
- 这更像 Frida 的 onEnter 语义:先插一脚,再让原函数照常跑
1 | .text |
hook_entry.cpp
1 |
|
 wechat
wechat- alipay


