
简单学习ollvm混淆&polyre例题解析
简单学习ollvm混淆
转载参考自:[原创]深入浅出 Ollvm 混淆原理及反混淆技术-Android安全-看雪安全社区|专业技术交流与安全研究论坛
OLLVM 的三大核心混淆手段:指令替换、虚假控制流、控制流平坦化
指令替换
通过数学等价变换来增加代码复杂度的混淆技术。它的核心思想是将程序中原本简单的指令(如加法、异或),替换为一段功能等效但逻辑极其晦涩的指令序列。
比如把a+b换成a-b+c-c+b+b
去除手段D810

可以看到,虽然 D-810 成功去除了一部分混淆,但核心逻辑(RC4 的异或操作)依然被更深层次的 MBA 表达式掩盖,未能完全还原。
当 D-810 无法完全还原,或者你需要处理极高强度的 MBA 表达式时,GAMBA 是你的终极武器。
该工具的详细使用方法请移步:[分享]Ollvm 指令替换混淆还原神器:GAMBA 使用指南

虚假控制流
通过向代码中注入永远不会执行的“死代码”块和难以预测的条件跳转,来干扰控制流图(CFG)分析。
不透明谓词:在程序运行时其真假结果是确定的,但对静态分析器而言难以推断其恒真或恒假的条件表达式。
示例:
if (x * (x + 1) % 2 != 0) { ... }。数学上任意整数 x,其 x(x+1) 必然是偶数,因此条件永远为假。但 IDA 在不进行深度代数分析的情况下,会认为这是一条合法的分支。
不可达块:在真实程序执行路径中永远不会被执行的基本块,但它在控制流图中是存在的。
D-810 内置了强大的不透明谓词匹配器,能够自动识别常见的 OLLVM 谓词模式并将其优化掉。
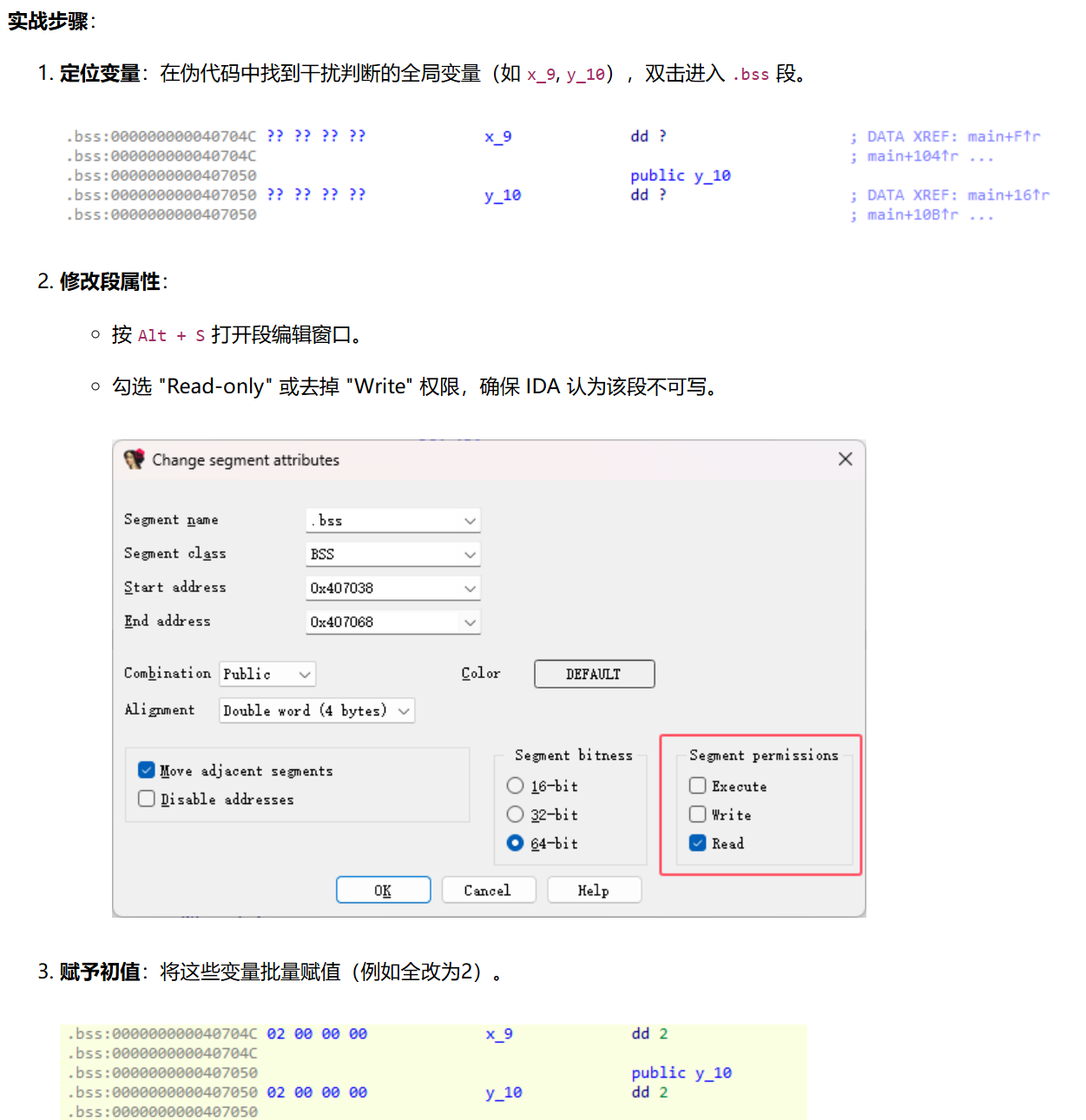
修改数据段属性与初值 (利用编译器优化)也可以一定去除
OLLVM 常使用全局变量(通常未初始化,位于
.bss段)作为不透明谓词的判断条件。
核心思路:既然 IDA 不知道这些变量的值,我们就人为地给它赋予一个定值,并告诉 IDA 这个值是“只读”的。这样 IDA 的反编译器就会触发常量传播(Constant Propagation) 优化,自动剪除死代码分支。
OLLVM 生成类似这种结构:
1 | if (g_flag) { |
其中:
g_flag是一个 全局变量- 位于
.bss段 - 未初始化(默认值 0)
- 但在程序早期某处被设置为固定值
对 CPU 来说运行时它是确定值(例如始终为 1)
但对 IDA 来说,这是一个内存变量,可能被修改,无法确定值,所以反编译器只能保守处理
辅助脚本
1 | import ida_segment |
在 .bss 段对相关变量执行 “Convert to data” (快捷键 D),然后回到反编译界面按 F5 刷新。你会发现大量分支因条件确定而被 IDA 自动优化消失了。
也可以直接修补汇编改成立即数
1 | import ida_xref |
此方法直接从汇编层面切断了不透明谓词的来源,IDA 在重新分析时会发现这些寄存器都是定值
控制流平坦化
旨在摧毁程序结构信息的重度混淆技术,它通过引入一个中央分发器,将原函数中原本层级分明、先后有序的基本块(Basic Blocks)全部“拍扁”,使得它们在控制流图(CFG)上看起来像是在同一个层级上。
- 序言 (Prologue) :函数的入口。它的核心任务是初始化状态变量。
- 主分发器 (Main Dispatcher) :混淆的心脏。通常是一个巨大的
while(true) 循环,内部包裹着switch(state)。它不断读取当前状态值,决定下一个要执行哪个块。 - 子分发器 (Sub-Dispatcher) (变种) :更复杂的 FLA 会嵌套多层 switch,或者使用数学公式计算跳转目标,进一步隐藏状态转移关系。
- 真实块 (Relevant Blocks) :包含原始业务逻辑的代码块。它们不再直接跳转到下一个真实块,而是被隔离成了 switch 的一个个 case。
- 预处理块 (Predispatcher) / 状态更新:每个真实块执行完后,不会直接跳转。而是通过更新
state 变量(例如state = NEXT_KEY),然后无条件跳转回主分发器,由分发器在下一轮循环中根据新状态进行调度。 - 返回块 (Return) :函数的出口,当状态变量达到特定值时,跳出循环并返回。
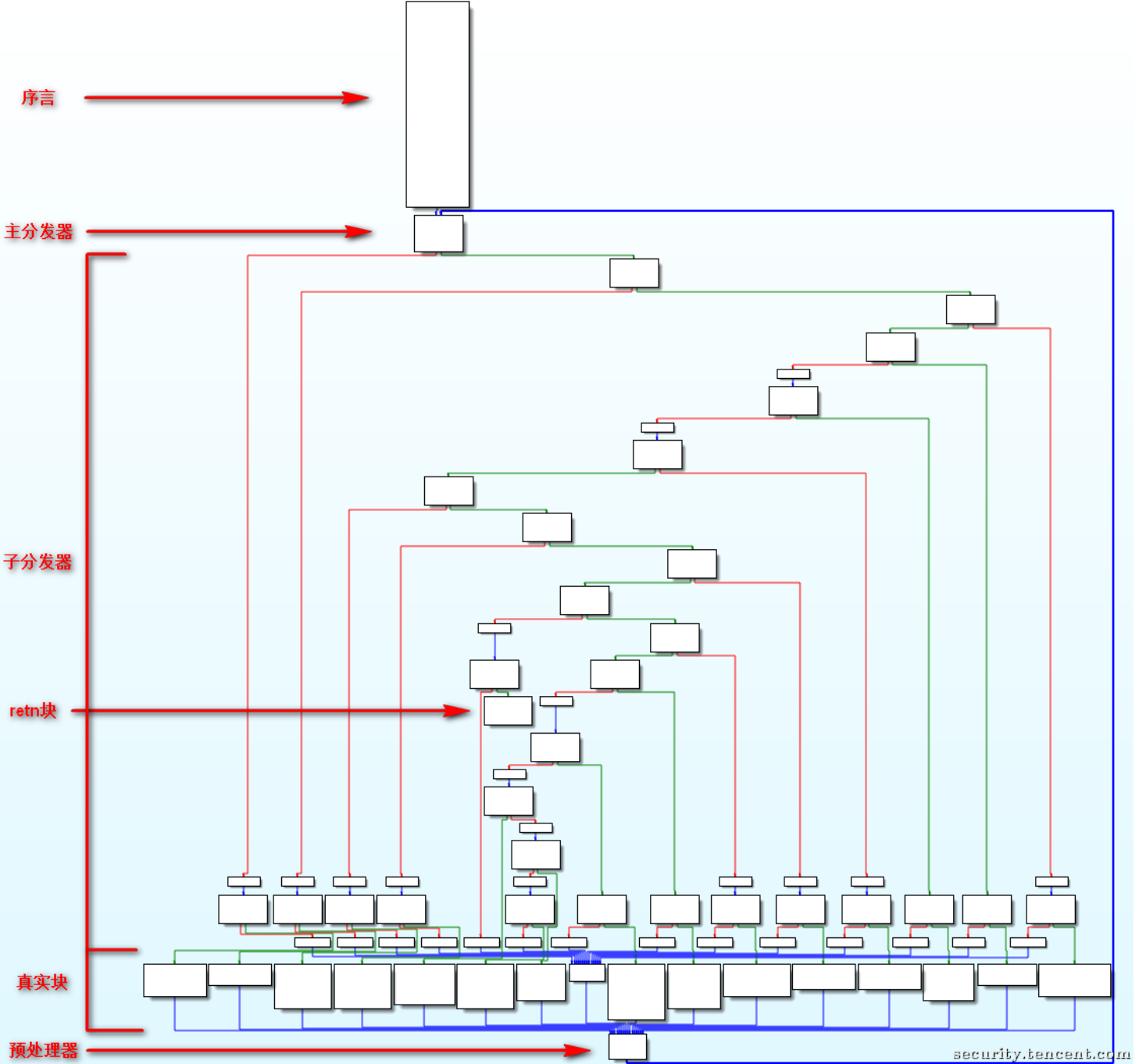
执行流程示例
- 初始化:序言设置
state = 1。 - 分发:主分发器检查
state,跳转到case 1(真实块 A)。 - 执行与更新:真实块 A 执行业务逻辑,并在末尾将
state更新为2。 - 回环:跳转回主分发器。
- 再分发:主分发器检查
state(此时为 2),跳转到case 2(真实块 B)。 - 循环往复… 直到
state变为结束标志。
D810可以一定程度去除
Deflat.py angr脚本(网上有自己写也行)
使用 Unicorn 框架 (动态模拟还原)
通过模拟执行,我们可以记录程序在运行时的真实轨迹 (Trace) ,从而无视复杂的静态混淆逻辑。
核心技术路径:
- 静态提取:利用 IDA 识别并提取所有基本块信息(真实块、虚假块、分发器)。
- 动态模拟:使用 Unicorn 运行程序,记录块与块之间的跳转关系及上下文(ZF 标志位)。
- 静态修复:根据记录的关系,Patch 二进制代码,短路分发器,重建 CFG。
第一步:静态提取 (IDA Python)
我们需要先让 IDA 告诉我们哪些是真实块,哪些是分发器/虚假块。
1 | import idaapi |
第二步:动态模拟 (Unicorn Trace)
有了块列表,我们使用 Unicorn 模拟执行,记录真实的跳转路径。
具体的 Unicorn 框架学习文章:[原创]深入浅出 Unicorn 框架学习
关键点:不仅要记录跳到了哪里,还要记录跳转时的 ZF (Zero Flag) 标志位。因为条件跳转(JZ/JNZ)完全依赖它。
1 | from unicorn import * |
第三步:静态修复 (IDA Python Patch)
拿到 real_flow(真实执行流)后,我们就可以在 IDA 中重建 CFG 了。
修复策略:
- 单后继块:如果块 A 后面永远只跟块 B,直接修改块 A 结尾为
JMP Block_B。 - 双后继块(条件跳转) :如果块 A 后面有时跟 B(ZF=1),有时跟 C(ZF=0),说明它是条件跳转。
- 难题:原始块 A 结尾空间可能不够写
JZ + JMP指令。 - 巧解:利用无用的 虚假块 (Fake Blocks) 作为跳板。
- 操作:
Block_A -> JMP Fake_Block -> [JZ Target_True; JMP Target_False]。
- 难题:原始块 A 结尾空间可能不够写
1 | import idaapi |
[例题] RoarCTF2019 polyre
ps:现在IDA 9似乎对这类ollvm做了优化 可以正常识别逻辑
angr
这里我跑了两个脚本分别是angr符号执行对抗ollvm - Qmeimei’s Blog | 探索一切,攻破一切和[原创]深入浅出 Ollvm 混淆原理及反混淆技术-Android安全-看雪安全社区|专业技术交流与安全研究论坛两位师傅的
其中第二份脚本就是上面那个(好理解一点,第一份脚本比较全面,能覆盖更多变体),跑出的结果不同,因为其规定了分发器本身归类为虚假块(我觉得有道理,待会都试试)
python1(原理看不懂直接看师傅的博客吧):
1 | import idaapi |
核心思想:先找循环头→再找汇聚块→把汇聚块的前驱当真实块
1 | Propagating type information... |
第二份脚本的输出
1 | [*] Analyzing function at 0x400620... |
获得真实块后,就是确定其执行顺序
在 OLLVM flatten 里,真实块的后继不是靠显式的 jz/jnz分支跳转决定的,而是靠 cmovxx/csel 这类条件选择指令把 state(调度变量)写成不同值,然后统一跳回 dispatcher。所以要恢复真实 CFG(每个真实块会通向哪个下一个真实块),关键是:对每个真实块,把 cmovxx 的两种结果都跑出来,分别对应两条后继边,并把它们存成一个映射表用于后续 patch/重建
Flatten 的函数入口(序言)通常做这些事:
- 建栈/保存寄存器(prologue)
- 初始化 state 变量(dispatcher index)
- 初始化一些全局/局部变量
如果不先跑序言,直接从某个真实块开跑:
- 栈帧(
rbp、局部变量)可能是垃圾 - state/全局变量值不对
- 真实块里的计算会跑飞
- 最后写回 dispatcher 的 state 也会错
先执行序言初始化环境,才能得到可重复、可控的执行结果。
jz/jnz是控制流分支,angr 遇到这种会天然 fork 两个 state。但
cmovxx是数据流选择:
- 控制流还是一条线(顺序执行)
- 只是寄存器值变成
ITE(cond, a, b)这样的表达式(条件表达式)所以 angr 默认会把
ecx表示成:ecx = if cond then eax else ecx_old然后一路带着约束走下去,并不会自动产生两条路径。
在 flatten 里,真实块不会直接
jz loc_A/jnz loc_B那样分叉,因为那样 CFG 很明显。它会这样做:
- 计算一个条件(ZF/CF/SF等标志由
cmp/test设置)- 准备两个候选 state 值(比如
ecx = A,eax = B)- 用条件选择指令把 state 写成其中一个:
- x86:
cmovnz ecx, eax(条件成立则把 eax 写进 ecx,否则 ecx 保持原值)- arm64:
csel x, a, b, cond
- 把这个 state 存到内存(比如
[rbp+var_114]或全局)- 无条件
jmp dispatcher示例块里:
2
3
4
5
6
7
8
9
10
11
setz sil
cmp ecx, 0Ah
setl dil
or sil, dil
test sil, 1
mov eax, 0F37184F0h
mov ecx, 0A105D2C4h
cmovnz ecx, eax
mov [rbp+var_114], ecx
jmp loc_4020CC含义是:
- 前面一堆计算把 ZF(或 nz 条件)决定出来
ecx先放 “默认 state = 0xA105D2C4”eax放 “另一个 state = 0xF37184F0”cmovnz ecx, eax:如果条件成立,就把 state 改成另一个值- 之后写到
[rbp+var_114],跳回 dispatcher- dispatcher 根据
[rbp+var_114]的值跳到不同真实块后继边是由
cmovxx写入的 state 决定的
对每个真实块:从同一初始化快照开始执行,遇到 cmovxx 时不让 angr 把它当 ITE 表达式,而是人为 fork 两个 state(cond 真/假),分别跑到 dispatcher 读取下一跳真实块,从而恢复该块的两条后继边,并按 ZF=1/0 的顺序保存成映射表用于后续 patch。
1 | import logging |
最终输出形态是:
1 | path = { |
capstone_decode_cmovxx(insn):解析 cmov 的两个寄存器
1 | operands = insn.op_str.replace(" ", "").split(",") |
比如 cmovnz ecx, eax 会解析出:
- dst =
"ecx" - src =
"eax"
find_state_succ_cmovxx(...):手动执行/不执行 cmov,然后继续跑到下一个真实块这个函数只在检测到 cmov 时被调用。它做了三件事
取当前指令(假设当前正好在 cmov 上)
1 | ins = local_state.block().capstone.insns[0] |
用 flag 决定是否执行这条 cmov 的 move 语义
你在注释里写的是针对 cmovnz 的逻辑:
flag == True把它解释成 ZF=1 →cmovnz条件不满足 → 不 moveflag == False解释成 ZF=0 →cmovnz条件满足 → 执行 move
所以代码是:
1 | if not flag: # 需要执行 Move |
从 cmov 后继续单步执行,直到命中下一个真实块
1 | sm = proj.factory.simgr(local_state) |
这就是跑到下一个真实块入口就停,并把它记录进 path[当前真实块]
1 | def jump_to_address(state): |
避免每次都跑完整序言/dispatcher
总结:
这段代码在 angr 里对每个真实块做一次小实验,实验结果累积到 path 里,最后把 path 转成 hex_dict
对每个真实块 B = real_block_addr,从同一个初始状态 init_state 出发,运行 angr,直到进入块 B,然后继续跑,看看接下来会进入哪个真实块,把那个下一个真实块写进 path[B]。
实例:
正在外层循环处理
1 | real_block_addr = 0x401eb9 |
此时:
1 | path[0x401eb9] == [] |
Step 1:先从函数入口跑到序言结束点,再跳到目标块
Step 2:find_block_succ() 的外层循环:找到块入口
在 msm.step(num_inst=1) 不断单步里,某一刻:
1 | active_state.addr == 0x401eb9 |
命中这一段:
1 | if offset == real_block_addr: |
现在开始用 msm2 在块内继续跑,找后继。
Step 3:块内继续执行,遇到 cmov(关键点)
在块内每一步都会取当前指令:
1 | ins = mactive_state.block().capstone.insns[0] |
假设在 0x401eb9 这个真实块里,最终遇到类似:
1 | 0x401ed0: mov ecx, 0xAAAAAAA1 ; 默认state |
那么当 msm2 跑到 0x401eda,就触发:
1 | if ins.mnemonic == 'cmovnz': |
Step 4:第一次分裂(flag=True)——“不执行 move”
进入:
1 | find_state_succ_cmovxx(... local_state=state_true, flag=True ...) |
它会做:
- 解析 cmov:
- dst =
"ecx" - src =
"eax"
- 因为
flag=True,你的语义是:ZF=1 → cmovnz 不满足 → 不 move
所以这一句不会执行:
1 | if not flag: |
此时 ecx 仍然保持原值 0xAAAAAAA1。
手动跳过 cmov 指令:local_state.regs.ip += ins.size
不然下一步
sm.step()时 angr 还会再把这条 cmov 执行一遍继续单步执行(sm.step),走到 dispatcher 再分发,最终 angr 的 RIP 落到某个真实块入口。
假设这个路径最后到达:
1 | active_state.addr == 0x401ed6 |
则命中:
1 | if ins_offset in real_blocks: |
此时:
1 | path[0x401eb9] == [0x401ed6] |
state 并不是由 cmov 这条指令凭空产生的。cmov 只是从两个已经准备好的候选值里选一个
Step 5:第二次分裂(flag=False)——“执行 move”
同理进入:
1 | find_state_succ_cmovxx(... local_state=state_false, flag=False ...) |
这次 not flag 成立,于是:
1 | src_val = state.regs.eax # = 0xBBBBBBB2 |
跳过 cmov 后继续跑,最终到达另一个真实块入口,比如:
1 | active_state.addr == 0x401f09 |
于是:
1 | path[0x401eb9].append(0x401f09) |
现在:
1 | path[0x401eb9] == [0x401ed6, 0x401f09] |
外层 angr_main() 最后把 path 转成 hex 字典:
1 | hex_dict["0x401eb9"] = ["0x401ed6", "0x401f09"] |
最后patch:
1 | from collections import deque |
generate_jmp_code(src, dst)
生成 5 字节近跳 E9 rel32:rel32 = dst - (src + 5)
返回 b'\xE9' + rel32
generate_jz_code(src, dst)
生成 6 字节 0F 84 rel32(JZ near):rel32 = dst - (src + 6)
返回 b'\x0F\x84' + rel32
思想是:用固定长度的 near jump/jz 来替换原本 flatten 中的 cmov+dispatcher 逻辑。
patch_dict 的结构是用 angr 得到的后继表:
- key:真实块起始地址(字符串 hex)
- value:
- 长度 1:无条件后继
[succ] - 长度 2:条件后继
[succ_when_zf1, succ_when_zf0] - 空:return 块
- 长度 1:无条件后继
如果后继有两个:在块内找 cmov,把它改成 jz + jmp
1 | if len(values) == 2: |
unicorn
angr:为了恢复 CFG,需要枚举所有可能后继,所以你手动分裂 cmov 两种情况。
Unicorn:是具体执行,只会走一条真实路径。它做的是:把程序跑一遍,记录它实际走过哪些真实块(以及每个块末尾 ZF),得到一条 real_flow 执行轨迹。
利用上面的输出依次放进脚本运行就行了
原来的代码会出现报错
2
3
4
[*] Starting Emulation...
[MEM READ] 0x603054, size=4
[Error] Invalid memory read (UC_ERR_READ_UNMAPPED)现在的加载方式是“把整个文件 raw bytes 写到 0x400000”:
2
uc.mem_write(0x400000, file_bytes)这不是 ELF 的正确加载方式。ELF 在内存里会按 Program Header 把不同段映射到不同虚拟地址
在 hook_mem_invalid 里按需补页
让模拟器遇到 unmapped 自动补一页内存继续跑,而不是直接停:
2
3
4
5
6
7
8
9
10
11
12
def hook_mem_invalid(uc, access, address, size, value, user_data):
page = address & ~(PAGE - 1)
try:
uc.mem_map(page, PAGE, UC_PROT_ALL)
# 可选:写 0 初始化不用写,默认就是 0
print(f"[MAP] mapped page at 0x{page:x} for access 0x{address:x}")
return True # 告诉 unicorn:我处理了,继续执行
except UcError as e:
print(f"[MEM] map failed at 0x{page:x}: {e}")
return False关键点:返回 True,表示你处理了这个异常,Unicorn 会重试这次访问
1 | from unicorn import * |
ida_patch
1 | import idaapi |
后面就是简单的算法不赘述了
1 | flag = [ |
flag{6ff29390-6c20-4c56-ba70-a95758e3d1f8}
 wechat
wechat- alipay


