
2026腾讯游戏安全竞赛Android决赛
2026腾讯游戏安全竞赛Android决赛 wp
题目与初赛一样,都是godot
题目附件:
1 | 通过网盘分享的文件:2026_end.zip |
题目附件:下载压缩包
ps:一些部分其实写的不太详细,后面有机会再补充吧,赛中使用了codex加速解题,wp中给的顺序非实际做题顺序,做题时没有处理反调试,因为10s的kill时间足够frida输出信息了,反调试是最后去了混淆再处理的,因此下面使用frida分析的动态调代码都会触发反调试,但是信息正常输出,在反调试章节给出了最终处理反调试的frida代码,和一些其它现象。
去混淆部分写的特别乱,主要当时写wp的时候还是有点懵,有空再整理
解包去混淆
这一部分其实跟初赛一样,甚至简化了
找key & 解密gdc
首先找脚本加密 key,与初赛相同,Godot 4.5 用 AES-256 CFB 加密 .gdc 文件,key 存在libgodot_android.so 的 .data段中
沿用初赛脚本做熵扫描,在段中找连续 32 字节高熵区域(前后被零填充包围)。
1 | import math |
key在0x4002f18
1 | CE4DF8753B59A5A39ADE58AC07EF947A3DA39F2AF75E3284D51217C04D49A061 |
与初赛相同,用初赛的解密脚本报错了,检查了一下发现,GEQ = GDSC ^ {0x00, 0x01, 0x02, 0x03},是标准的CFB-128,没有XOR,微调了下初赛的脚本
1 | import os |
运行脚本发现提取出来的
gdre_tools 反编译
1 | ./gdre_tools.x86_64 --headless --decompile=decrypted/token.gdc --bytecode=4.5.0 --output=decrypted/decompiled |
是类似的乱码,猜测是被混淆了,因为之前在华为杯看到过类似的题可能是改了opcode的映射?
通过对比初赛和决赛 .gdc 文件结构发现
初赛Godot 4.5 格式:
- header: GDSC magic + version(101) + plaintext_size + zstd 压缩数据
- 解压后是 4 个 dword 计数 (idents, consts, lines, tokens)
- identifiers: length(4) + 每字符 4 字节 (UTF-32 LE XOR 0xb6b6b6b6)
- constants: 标准 Variant 序列化
- lines: 每条 8 字节 (token_idx + line_num)
- tokens: 每条 4 字节 (低 8 位 type + 高 24 位 data)
决赛:
- 计算每个 .gdc 的 tail 区域剩余字节,拟合不同 token 大小 ,tokens 8字节 + lines 16字节 是 完全拟合(trigger1:
235*8 + 38*16 = 2488) - token 改为 8 字节:4 字节 (type+data) + 4 字节 (line number)
- lines 改为 16 字节:4 dword (token_idx, line, col, ?)
用新格式解析,AI搓一个脚本
1 | import zstandard as zstd |
输出trigger1,示例
1 | # === decrypted/trigger1.gdc === |
有点乱,然后研究了libgodotengine.so发现,不仅改格式,果然重排了 token 类型 ID。完整 token 表从 libgodot_android.so 提取在 0x3ec2548 找到 100 项的 _ZN17GDScriptTokenizer5Token8get_nameEv字符串指针表。
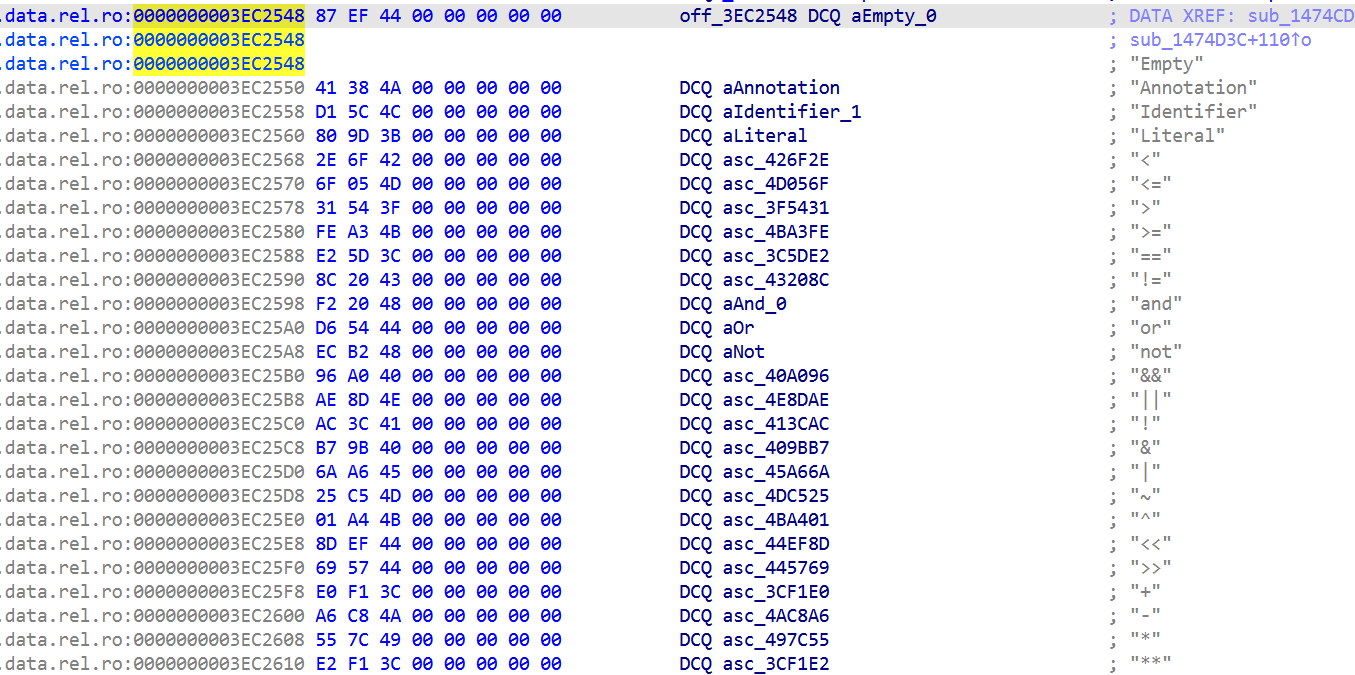
AI解释了下说
| 标准 godot ID | ID | Token 名称 |
|---|---|---|
| 2 | 0x8c | IDENTIFIER |
| 3 | 0x8d | LITERAL |
| 26 | 0xa6 | = |
| 27 | 0xa7 | += |
| 20 | 0xa0 | + |
| 22 | 0xa2 | * |
| 4 | 0x8e | < |
| 75 | 0xd8 | ( |
| 76 | 0xd9 | ) |
| 77 | 0xda | , |
| 79 | 0xdc | . |
| 81 | 0xdf | : |
| 82 | 0xe0 | $ |
| 38 | 0xc6 | extends |
| 58 | 0xc7 | func |
| 64 | 0xcd | signal |
| 68 | 0xd1 | var |
| 42 | 0xb7 | while |
| 41 | 0xb6 | for |
| 59 | 0xc8 | in |
| 19 | 0x9d | ^ (XOR) |
| 33 | 0x9e | << |
| 34 | 0x9f | >> |
| 16 | “and” | & |
| 17 | “or” | | |
| 25 | “**” | % |
- 第一个 token 为 extends,第二个为 IDENTIFIER(父类名)
var X := Y→VAR IDENT COLON EQUAL LITERAL(推出:、=)func _name():→FUNC IDENT ( ) :(推出func、())_a[_j]在 bytecode 中表现为IDENT(_a) IF IDENT(_j) RETURN,说明[]也被映射但形式特别0xa6在赋值上下文为=;同位置0xa7在累加上下文为+=(用_tv += _d * 2.0验证)<0x8e>在_j <0x8e> _n:上下文为<- NEWLINE 数量 = 总行数(统计 0xdf 出现频次跨所有 .gdc 验证)
依旧搓个脚本
1 | import zstandard as zstd |
生成的trigger起码能看了
1 |
|
让AI综合两版进行总结整理下
1 | extends Area3D |
Tick 分析
这其实是最后做的当时
Trigger里的Tick一开始以为是part3 最后发现是反调试扎堆的地方
1 | extends Area3D |
反汇编分析
工作原理博客,不久前才稍微复习了ollvm,用上了刚好,其实原理差不多,虽然混淆每次不一样,如果不理解请先了解ollvm对抗
跟踪到0x9AD68 ,这一块结合codex进行分析
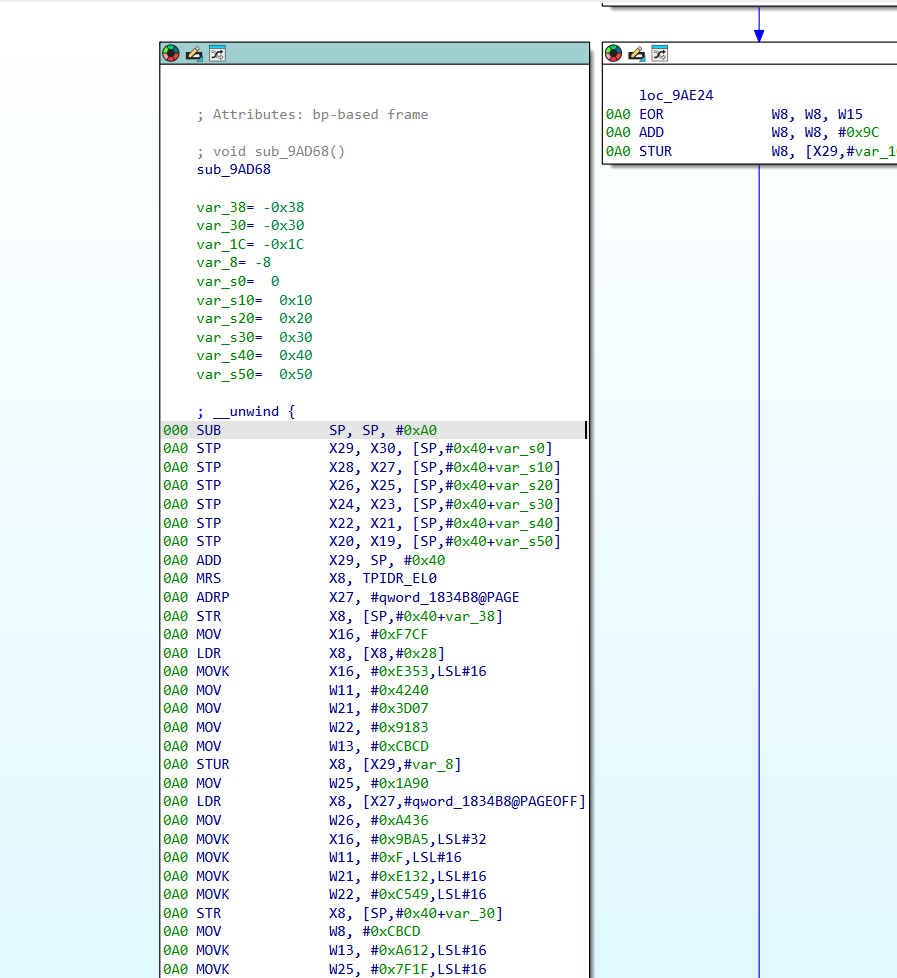
0x9AD68 - 0x9ADB0很明显是个序言
在分配栈空间和初始化魔数
2
3
4
MOVK X16, #0xE353,LSL#16
MOVK X16, #0x9BA5,LSL#32
MOVK X16, #0x20C4,LSL#48比如
2
3
4
5
6
7
8
9
10
11
12
13
while (1) {
switch (state) {
case 0xA612CBCD:
state = 0xC5499183;
break;
case 0xC5499183:
state = 0x7F1F1A90;
break;
}
}
0x9AD94 - 0x9AE10在进行一些常量设置,结合后面分析得出大概是这样的
1 | ; OLLVM 的魔数,12 个 32-bit 常量填到寄存器 |
核心的分发逻辑在0x9AE30 - 0x9AE6C
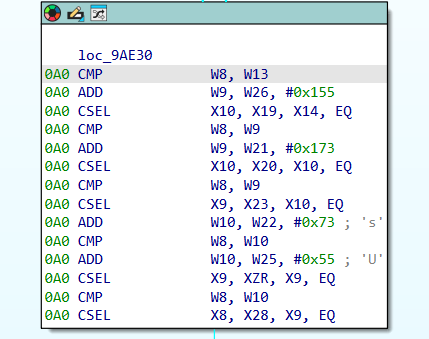
1 | loc_9AE30: ; 状态机分发头 |
0x9AE1C - 0x9AE2C进行状态迁移转换
Entry 0 (0x9AE14) : slow-path
1 | 9AE14 ADD X30, X30, #0x30 ; LR += 0x30 |
把返回地址向后推 0x30 字节,RET 后 CPU 跳到进入 Tick 时 LR 值 + 0x30 的位置。但 Tick 进入时 LR = 0x9AEFC(BLR llabs 的下一条,被保存在寄存器未被改过),推 0x30 , 跳到 0x9AF2C,那是 Tick 自己函数体内部。
LR用来保存函数返回值,跳转到某个寄存器里保存的地址,并把返回地址保存到 LR/X30
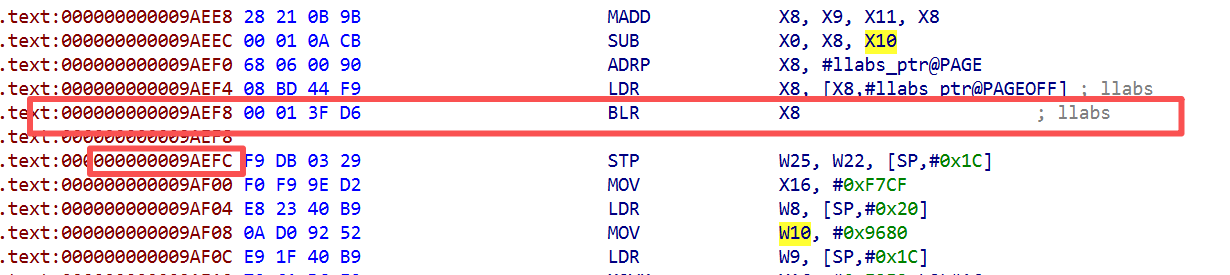
回到 0x9AF2C 后代码继续执行 entry 5 的后半段,再次 B 到 dispatcher,第二次分发时 W8 不再匹配任何 valid state,落到默认 entry 7。
以下分了几个entry,下面要穿起来理解但理解某个entry可能不太好理解
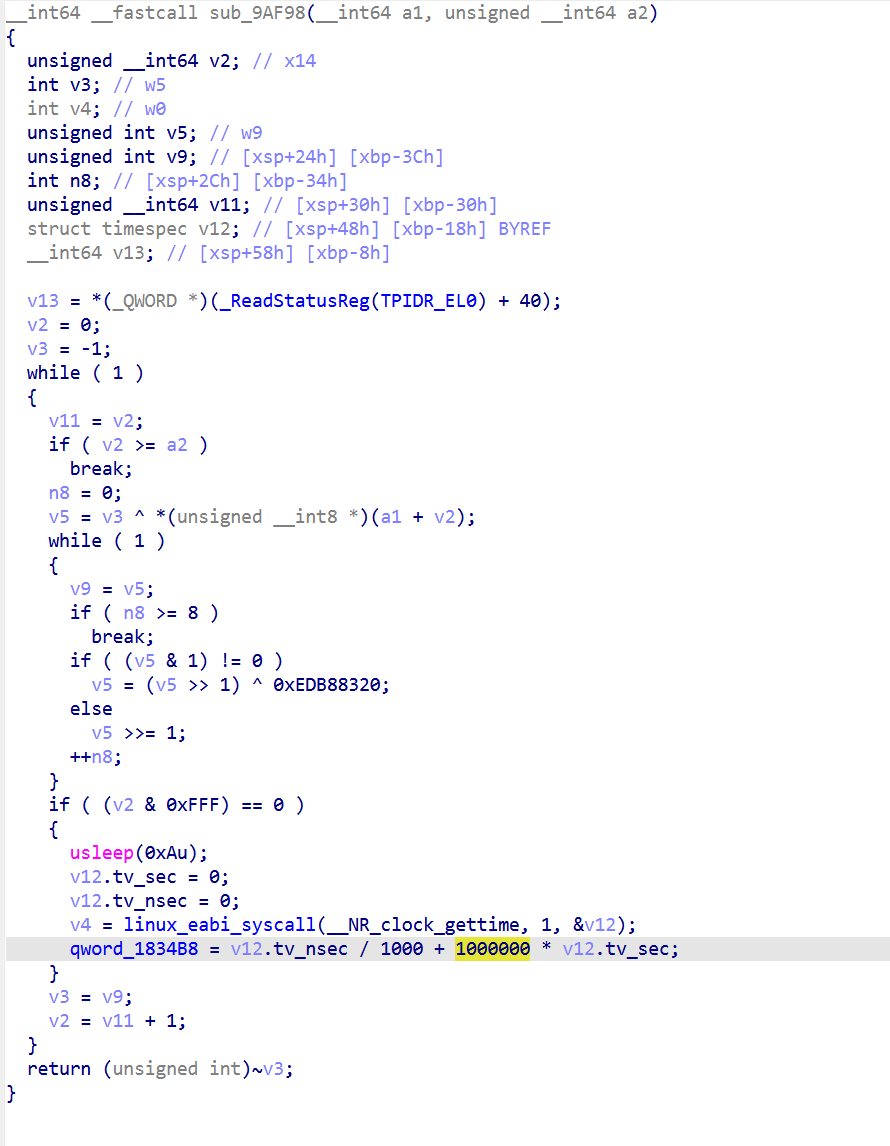
Entry 1 (0x9AF44) : baseline 初始化判定
1 | 9AF44 STP W21, W26, [SP, #0x1C] ; [SP+0x1C] = 0xE1323D07, [SP+0x20] = 0x1B49A436 |
首次 Tick:baseline==0 ,选 entry 2 写 baseline
非首次:baseline!=0,选 entry 5 检查 10 秒
Entry 2 (0x9AE88): 初始化 baseline
1 | 9AE88 STP XZR, XZR, [X29, #-0x18] ; 清空 timespec struct |
这是唯一写 qword_1834B8 的地方(在 Tick 内部)。只在首次调用 Tick 时执行。
这段是 Tick 反调试的初始化 baseline 时间戳分支(首次运行时建立基准时间)
Entry 5 (0x9AEBC) : 10 秒 diff 判定 核心反调试
1 | 9AEBC STP XZR, XZR, [X29, #-0x18] ; 清空 ts |
常量:
- 0x00989680 = 10 秒
- 0xF4240 = 1000000
- 0x20C49BA5E353F7CF = 除 1000 魔数
Entry 4 (0x9AF60) : 正常 epilogue(fast path 出口)
1 | 9AF60 LDR X8, [SP, #8] ; 读 TLS |
标准 epilogue stack canary 验证。fast path 出口是这里(指的是没被调试过)。
Entry 7 (0x9AE70) trap
1 | 9AE70 LDR X1, loc_9AE68 ; X1 = 从 dispatcher 代码字节读取 8 字节 |
loc_9AE68 实际是 dispatcher 最后两条指令的机器码(LDR X8, [X24, X8] + BR X8):
- 0x9AE68: F8 68 6B 08
- 0x9AE6C: 00 01 1F D6
合起来读0xD61F0100F8686B08。
这是 ARM64 指令字节被当成数据地址读取,BLR X1 跳到不存在的内存 , MEM_INVALID 导致 SIGSEGV。OLLVM 的骚操作 , 用自己的指令字节做陷阱指针。
正常运行流程:
1 | sub_9B7D8 线程 → 每 3s → sub_96A00 → sub_9AF98 → 写 qword_1834B8 = now |
本质是一个反向心跳机制: 反调试线程每 3s 证明还活着,如果证明中断 ,Tick 自毁。
内联 SVC 的反 hook 细节
Tick 里 clock_gettime 不走 libc,而是 inline SVC
1 | MOV W0, #1 ; CLOCK_MONOTONIC |
Frida Interceptor.attach(libc.so, “clock_gettime”) 完全拦不到。要拦这个 SVC 必须用 Stalker 级别指令扫描,开销大。
OLLVM去混淆 [Tick部分]
发现了 OLLVM 标准结构,实际工作只在 entry block 里。dispatcher 纯粹是混淆。
先找 dispatcher 边界 + jump table 基址
工作原理博客,不久前才稍微复习了ollvm,用上了刚好
简单学习ollvm混淆&polyre例题解析 | Matriy’s blog
angr符号执行对抗ollvm - Qmeimei’s Blog | 探索一切,攻破一切
既然是OLLVM CFF ,我们需要找dispatcher,OLLVM CFF 把它变成巨型 switch
1 | void f() { |
每个 basic block 变成一个 entry
- CFF 的本质就是间接跳转,,必须有 LDR ; BR 这种查表+跳的模式
- 这模式在普通编译器代码里罕见(普通函数用 B label 直接跳),所以见到就基本是 dispatcher
- 找到 dispatcher 后,再用 CFFSolver(后面写了个通用的)枚举所有 state 到 entry的链接,就把整张state→代码块对应表挖出来,CFF 就解开了
1 | disasm 整个函数, 找: |
例1:
1 | 0x9AE68: LDR X8, [X24, X8] X24 = off_161A58 = jump_table |
例2:
1 | 0x97DD4: LDR X8, [X28, X8] X28 = off_161970 = jump_table |
所以可以得到一个通用流程
- Capstone 扫整个函数找 BR X
<reg>,往前看一条是不是 LDR X<reg>,[Xm, Xn] - 找到后回溯 Xm(base)的赋值,找 ADR / ADRP+ADD
- 收集所有 CMP 的 RHS 常量作为候选 state
- 用每个 state 跑 dispatcher,记录 state → byte_offset → table[byte_offset] = entry_addr
用 Unicorn-style 模拟 dispatcher,建立 state到 entry 映射,拿博客里的改就行
这里手动找了序言,放进去了,后面有自动化的版本这里只为了验证
1 | import idc |
输出:
1 | The initial autoanalysis has been finished. |
魔数对应如上
其中的prologue_static_regs 怎么填?看 prologue 里的 MOV W19, …; MOVK W19, #…, LSL #16 序列,把每个寄存器最终的值算出来。手动算或用:
1 | # 抠 prologue 里的 W19到W28 终值 |
trace cold-start 链
知道 state到entry 后,从 prologue 的 INITIAL_STATE 开始 trace,就是之前的流程
1 | state = INITIAL_STATE # prologue 末尾把 W8 设为这个值 |
XOR_K 和 ADD_K 在 dispatcher 入口,比如 sub_97B6C 是 EOR W8, W8, #0x8D; ADD W8, W8, #0x8F。
遇到 CSEL 的 entry, 它依赖一个全局 byte(如 byte_183518 = 反调试 flag)。Cold start 时这些 byte 全 0,所以总是走false 分支。trace 一遍 cold-path 即可。这个我的博客里也提到怎么处理
Patch dispatcher 短路成线性
每个 entry 末尾的 B 0x97C24/97C28 替换成 B <下一个 entry>。选一边
1 | import ida_bytes |
prologue 末尾的 B → dispatcher 也要改成 B → 第一个 entry 的 work 入口(跳过 dispatcher 整个 CSEL chain)。
最后重建函数边界:
1 | import ida_funcs, ida_auto, ida_hexrays |
完整代码:
1 | import ida_bytes |
初始状态分析:
- prologue 末尾 W8 =
0xC56DA9A6(MOV+MOVK) - state transform = (W8 ^ 0x8D) + 0x8F
用 ollvm_cff_solver 解出的 21 个 (state→entry) 映射:
1 | state 0xc56da9a6 -> entry 0x98040 |
Cold-start 链:
1 | prologue (0xC56DA9A6) |
11 个 patch:
1 | 0x97C08 -> B 0x97F58 prologue → first entry |
执行后 F5 出 伪代码,17 个工作调用可见,揭示了完整的Godot注册逻辑。
效果
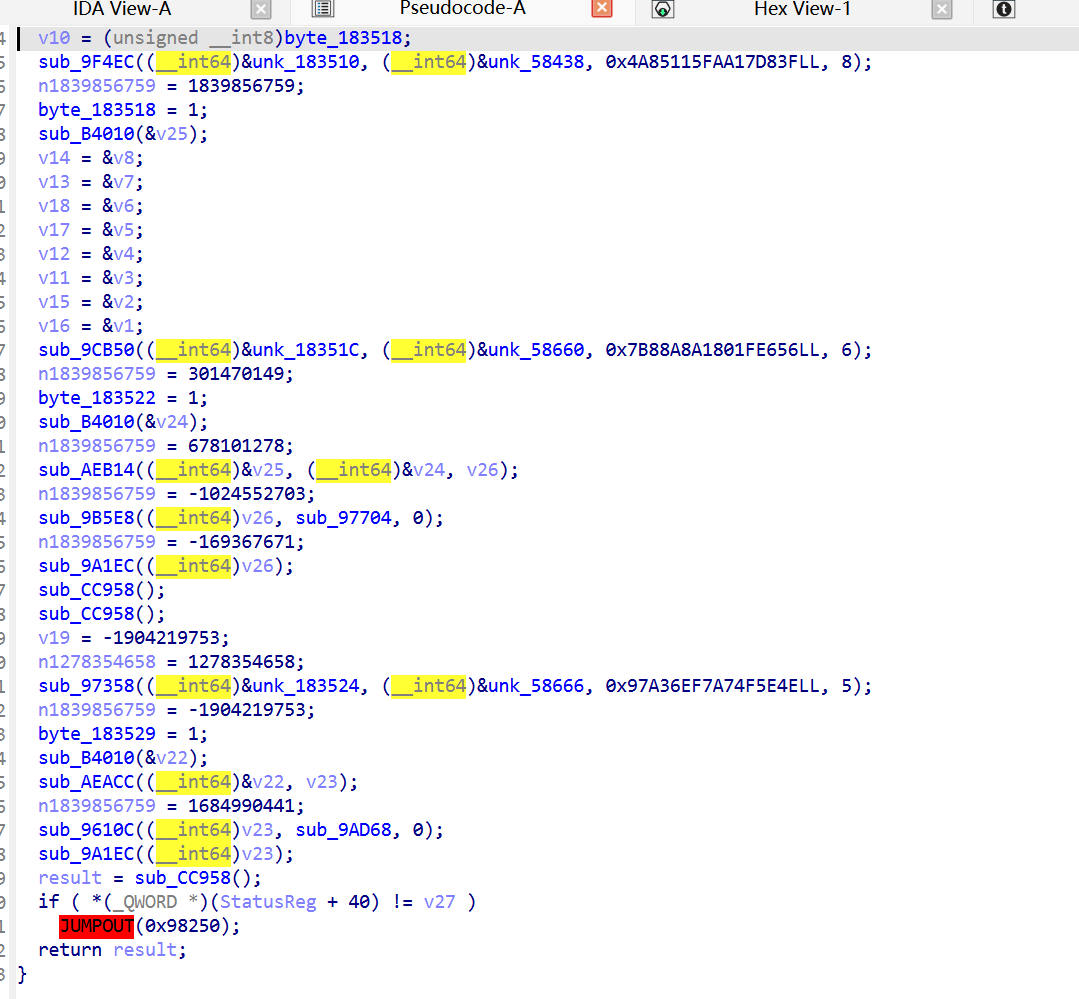
这是用 OLLVM CFF patch 方法对付 Tick 函数 (sub_9AD68) 的脚本。逻辑跟之前的同款,只是针对 Tick
1 | import ida_bytes |
可以看到清晰的代码
OLLVM去混淆 [反调试部分]
ps:最后观察了一波主要分两种混淆这里 一种是写死的跳转 一种是条件跳转,这里只是分析,其实还是手动patch,让AI分析
sub_9B7D8
这个是个更复杂的OLLVM(OLLVM CFF + 运行时状态机),依赖 mprotect sub_9AD3C 返回值+ byte-compare loop
因此思路是用Unicorn 跑出真实 cold-path + 静态 patch 完全线性化
为什么需要 Unicorn?
前面的OLLVM 的 CFF 是可静态 trace 的:
- 唯一 CSEL 在 baseline==0 上(cold-start = 0,必走 init 分支)
- bind_methods: CSEL 在 byte_18351X(cold-start = 0,必走首次分支)
区别是 state 来源是静态常量还是运行时数据
1 | 9bd00: ADR X8, #0x98564 X8 = sub_98564 地址(OLLVM 用 ADR+BLR 而非 BL) |
ADR+BLR:正常函数调用常写成 BL 目标地址,但 OLLVM/混淆器可能先用ADR 把目标地址算到寄存器里,再用 BLR 寄存器调用。这样会把一个直接调用伪装成间接调用
怎么看出 next_state 来自运行时:
- BLR X8 调外部函数(这里是 sub_98564 内部跑 syscall)
- CMP W0, #0 → W0 = 返回值
- CSEL W8, W9, W8, EQ → W8(状态寄存器)取 W9 或 W8,取决于刚才的 CMP
- B 0x9b93c → 跳回 dispatcher,dispatcher 用 W8 路由
syscall 返回值决定下一个 state
再比如
1 | 9bdd0: LDR W9, [X19, #0xac] 加载候选 state |
这些都是运行时探测,静态没法预测。所以必须 Unicorn 跑,看实际命中哪些 entry。
写个 grep 工具扫整个函数,这种 BLR CMP CSEL B 的三连就是运行时状态转移
用之前的CFFSolver可以初步探测一下
1 | import idc |
1 | sub_9B7D8 |
这 17 条映射告诉我们 dispatcher 能跳到哪些地方,但不告诉你它实际跳了哪条。要拿真实链必须 Unicorn 跑(CSEL 依赖运行时探测结果)。
其实就是:
比如next_state {0xfbe35076, 0x698549b1},取决于 W0W0 取决于 mprotect / openat 的真实返回值, 内核行为/文件系统状态决定,编译期/静态分析无法预测 ,我们无法预测,之前的Tick 我们是手动分析和选择了一个分支,但是这里全是
用 Unicorn trace 实际执行
让AI搓一个脚本,准备好got表,然后模拟执行
这脚本把 sub_9B7D8 的所有 syscall 替换成永远成功的 stub,让 Unicorn 实际跑一遍。CSEL 拿到 stub 返回的 0 永远走 cold-path(无调试), 记录 PC 命中 entry 的顺序 ,得到真实链
1 | from __future__ import annotations |
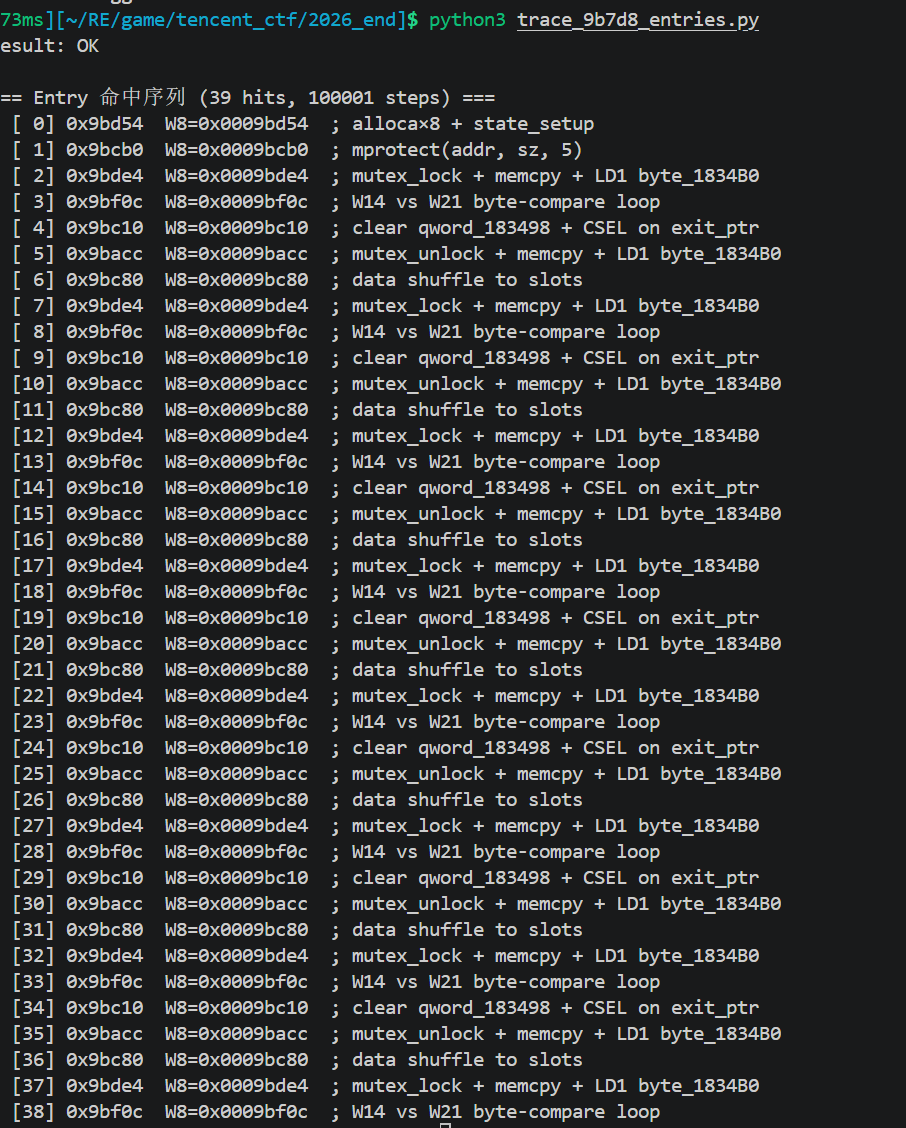
Phase 1: 0x9BD54 → 0x9BCB0
Phase 2 (loop): 0x9BDE4 → 0x9BF0C → 0x9BC10 → 0x9BACC → 0x9BC80 → 回 0x9BDE4
找每个 entry 的 dispatcher 出口
不是所有 entry 都直接跳回 0x9B93C/934/938。有些经过中转:
0x9BCB0末尾跳0x9BDDC(与 0x9BD54 共用 CSEL+B 0x9B93C)0x9BACC末尾跳0x9BEFC(借用 entry 0x9BEF0 中段的 STR + B 0x9B938)0x9BF0Cloop 末尾在0x9C3B0(B 0x9B94C, 直接跳 dispatcher 头)0x9BC80末尾跳0x9C3E4(state 计算后 B 回 dispatcher)
发现多个 entry 共用 dispatcher 尾巴。如果 patch 共用尾巴,会破坏多个 entry。所以必须 patch 每个 entry 自己的汇入点,不要碰共用尾巴。
1 | import ida_bytes |
效果
完整伪代码
1 | void sub_9B7D8() |
去混淆分析 [重新分析]
这里自己想写一个批量去混淆的脚本失败了,想想也对,腾讯在用的混淆怎么可能这么轻松给去了,于是用unicorn和手动分析去找patch列表
重新分析下,因为中间被搞懵了,后面的patch列表都是unicorn+手动分析得到的
原理性部分
来自个人博客
简单学习ollvm混淆&polyre例题解析 | Matriy’s blog和angr符号执行对抗ollvm - Qmeimei’s Blog | 探索一切,攻破一切
把OLLVM处理过的反调试函数还原为 F5 可读的线性 C 代码。之前解完发现还有几处混淆漏了,上面的代码好像不是非常通用,经过分析发现
OLLVM CFF 主要有两种派发器实现,底层目的相同(隐藏控制流),但具体形态不同,去混淆策略也不同。
第一种: jump-table 表驱动(Tick / sub_9B7D8 / sub_9C654 / sub_9AF98 / sub_99418)
1 | dispacther: |
每个 entry 末尾:
1 | STUR W?, [X29, #STATE_SLOT] ; 写新 state |
第二种: chained-conditional 链式条件(sub_9CDC4)
用一堆按大小组织的CMP + 条件跳转来查找当前 state 对应的真实基本块
可以看这篇文章:https://synthesis.to/2021/03/03/flattening_detection.html
1 | dispacther (派发表分散在整个函数): |
2
3
4
5
6
7
8
9
10
CMP W8, #STATE_001
B.EQ entry_001
CMP W8, #STATE_002
B.EQ entry_002
...
CMP W8, #STATE_032
B.EQ entry_032
32 个 state 平均 16 次比较慢。
用 B.LE / B.GT 先粗分再细分 = 二叉搜索树(O(log N),32 个 state 只要 5 次比较):之前的CFF slover解不开这种
每个 entry 末尾:
1 | MOV W8, #NEW_STATE_PRE_MUTATION |
特征是CMP + B.cond 长链(无 BR Xn),通常配二分搜索。
派发器附近找 BR Xn:
- 有 BR Xn 是 jump-table
- 没有 BR Xn,只有大量 B.LE/GT/EQ/NE 是chained
BR Xn 和 B label 的根本区别跳转目标是从寄存器还是指令本身硬编码的,之前讲过
第一种
关于这一种,[原创] 2026腾讯游戏安全技术竞赛-安卓决赛VM分析与还原-Android安全-看雪安全社区|专业技术交流与安全研究论坛,这个师傅有更好的处理方法。
我的是线性化 patch思路这个师傅是修 tab/jpt 表(修 jump_table 使索引连续)
之前实现的是ollvm_cff_solver是第一种,派发器是 state → entry_addr的查表函数,但里面混杂了 OLLVM 制造的死代码。直接 F5 看是一坨 CSEL,看不出到底有几个 entry。解法符号执行派发器,给 state 一个具体值,模拟跑派发器到 BR X8,记下最终的 X8(就是jump table 偏移)。然后从 jump table 拿 entry 地址。
派发器里的 CMP W8, W?中的 W? 都是候选 state 值。扫描派发器,把所有进入 W? 寄存器的常量(MOVZ + MOVK 解算后)当作候选。
找派发器边界:从序言之后第一个 CMP W8, Wn 开始 (dispatcher_start),到 BR X8 之后 (dispatcher_end)。
找 jump table:派发器里
ADR Xn, off_XXXX的 off_XXXX。抄 prologue 的静态寄存器值:所有 MOV/MOVK 串解算成 32-bit。
调 solve_all()
第二种
NZCV 是ARM64 的 4 个条件标志位,每条 B.cond 都靠它决定跳不跳
如NZCV = 0x60000000 二进制 = 0110 0000 … N=0, Z=1, C=1, V=0。
思路是用Unicorn 模拟 CPU 执行函数
二叉树遍历,第二种的派发器是二分搜索树,内部节点是 B.LE/GT 把范围切成两半,叶子是B.EQ跳到 entry。
因此可以BFS / DFS 整棵树,遇到 B.EQ 收集叶子 (state_to_entry),遇到B.LE/GT/NE把目标 push 到工作队列继续走。
下面的可能比较难理解,这里不展开了,有空补充,而且比赛的时候只是分析了,实际上还是让AI分析控制流手动patch的
1 | def walk_dispatcher(start_ea, end_ea): |
目标仍是建立某个 state 值到 对应的真实基本块入口
每遇到一个条件跳转,就把目标地址加入 work,之后继续遍历
2
3
CMP + B.NE #imm : 向叶子,state_to_entry[imm] = fall-through 地址;B.NE_target 是另一棵树(push) CMP + B.LE/GT : 内部节点,把跳转目标 push 到队列(另一半子树要走)
B label : 默认分支,push 到队列、记到 defaults
state mutation
1 | LDR W8, [X19, #STATE_SLOT] |
每次 entry 末尾都把期望 next state 的 pre-mutation 值写进 STATE_SLOT,然后 B 回 mutation 头,让派发器算出真正的 next state。
dispatcher 入口加 XOR+ADD 加工成真 state,是 OLLVM 编译期插的混淆,dispatcher 的门口固定的一小段代码,详细可以看
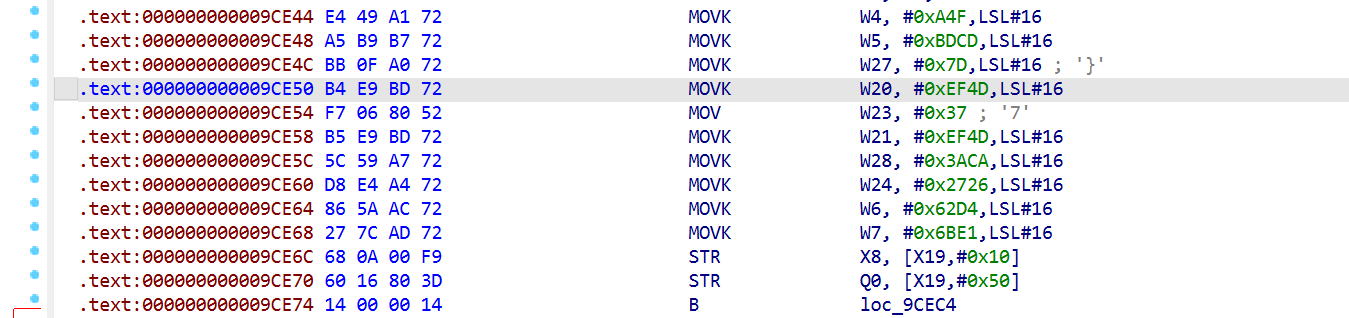
求next_state发现有这样的东西,需要把状态还原回去:
1 | next_state = ((entry_set_value ^ MUTATION_XOR) + MUTATION_ADD) & 0xFFFFFFFF |
生成patch_list [废弃]
尝试写个自动脚本自己去混淆结果,自动找第一种混淆的entries然后填入用unicorn模拟,自动化的得到patch_list,对于第二种需要收找entries
模块 1:auto_extract_entries() :静态找 entries,扫 [func_lo, func_hi) 找 LDR Xt,[Xn,Xm]+BR Xt 配对
模块 2:CFGTracer : Unicorn 动态 trace, 输出转移列表 [(src_entry, branch_pc, target, NZCV, kind), …]
模块 3:gen_patches() :根据traces的输出转 PATCHES
1 | 对每个 src: |
一般很多个转移可能是dispatcher
1 |
|
以sub_9c654为例,python xxx sub9c654
输出
1 | PATCHES = [ |
manual review needed代表需要人工确认,加上这一条的效果如下
相比下面的手动patch识别其实还有差距,因此废弃了这个方案
sub_9AF98
1 | import ida_bytes |
sub_9C654
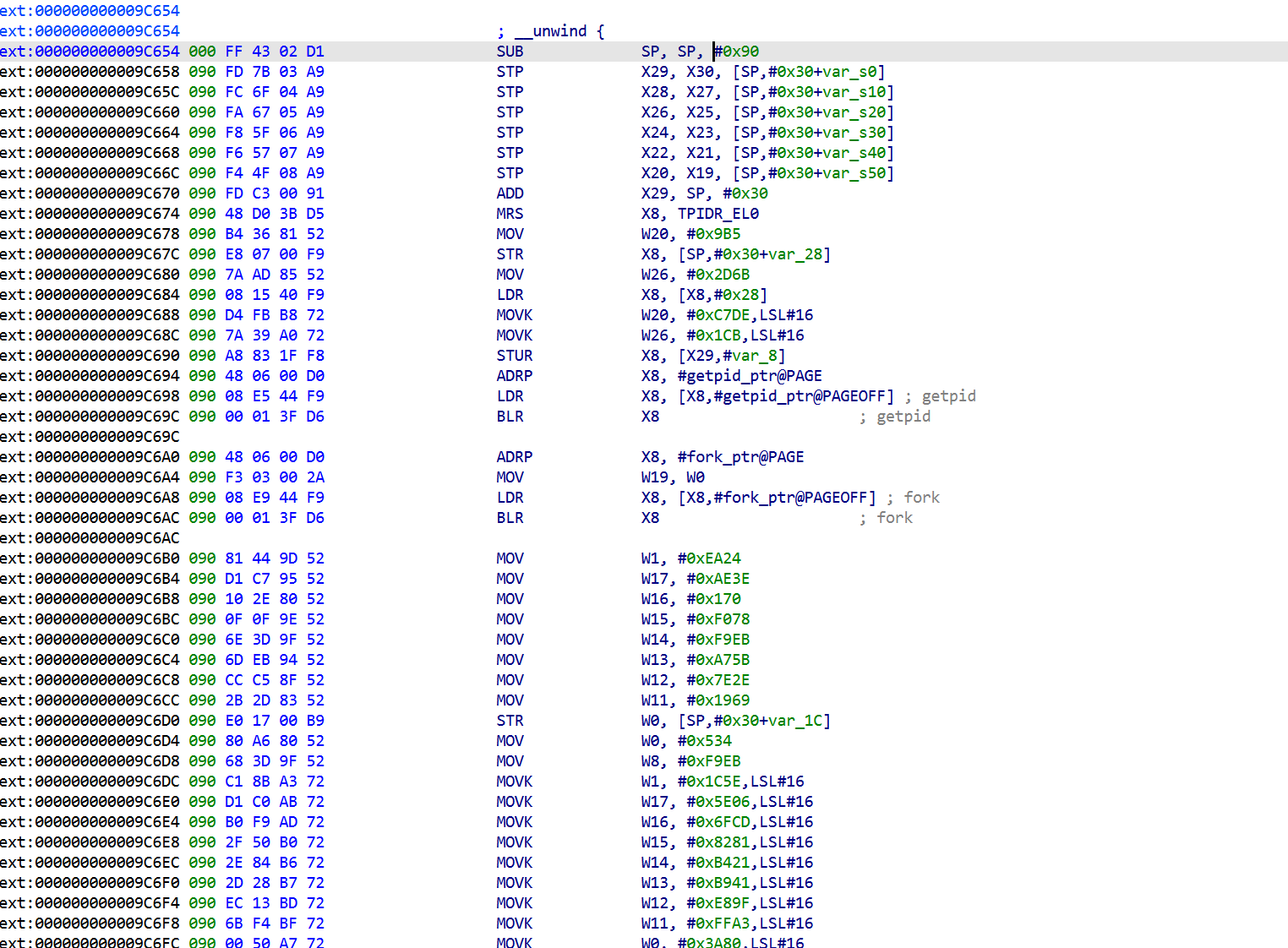
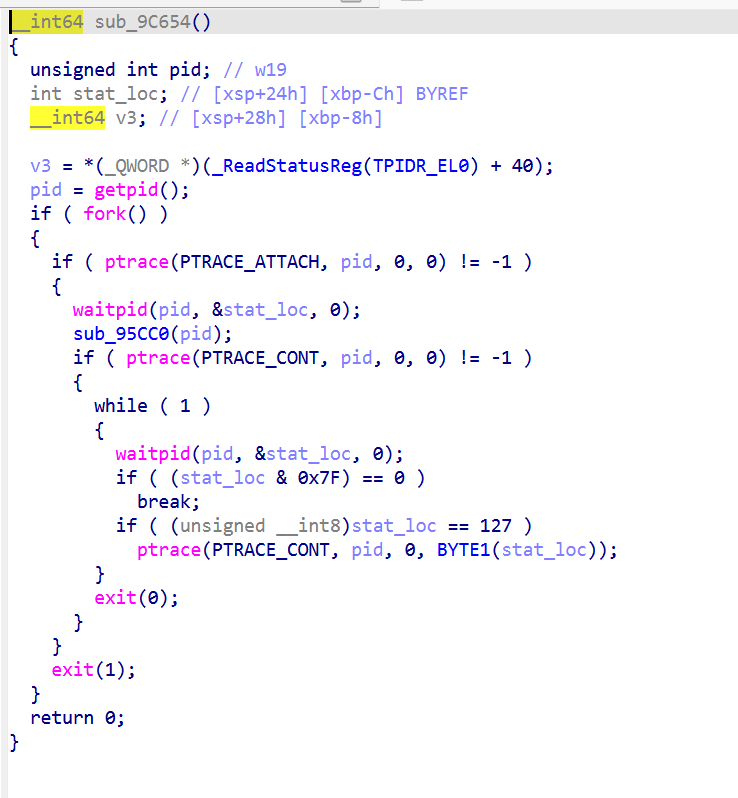
1 | import ida_bytes |
sub_9CDC4


1 | import ida_bytes |
sub_99418
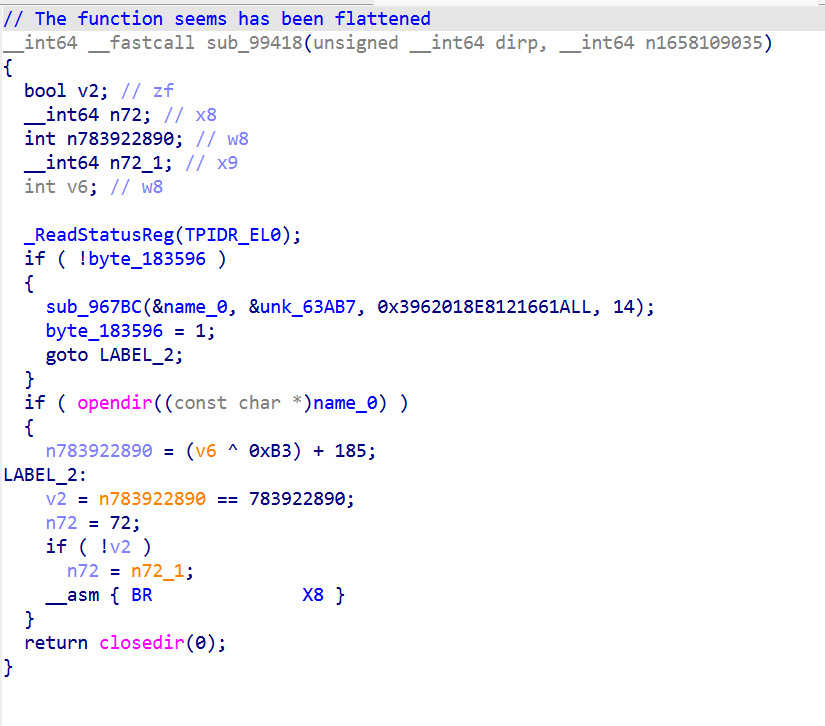
1 | import ida_bytes |
字符串解密
这里应该有个xor解密
1 | src = bytes([0x6f, 0xaa, 0x78, 0xc9, 0x3a, 0x62, 0xf6, 0x4a])) |
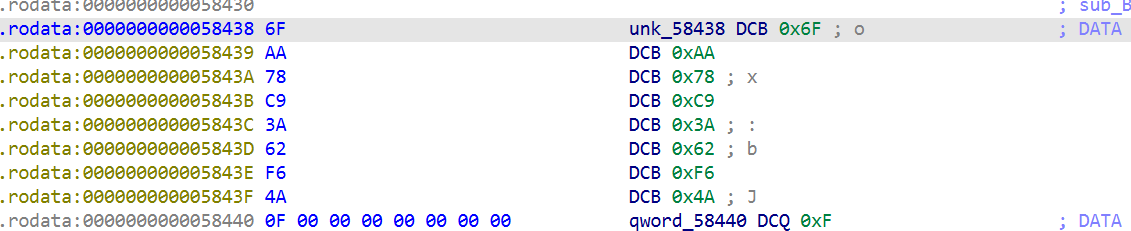
肯定还有其它字符串被混淆了,查看这个混淆的特性
要做这件事得解决 3 个子问题:
1. 怎么找到所有解密函数(不止一个,可能 3 个 10 个 39 个不知道)
2. 怎么知道每个解密函数用的是哪种 XOR 算法(有简单 XOR 和加 index XOR 两种变体)
3. 怎么知道每次调用传的参数是什么(src 地址在哪、key 是多少、len 是几)
想法一:看形状不看字节,可以去看序言的形状对比一下正常业务代码还是有区别的
XOR decoder 干的事是这样:
1 | for i 从 0 到 len: |
寄存器编号、地址表达式、指令顺序细节可以变,但这 3 个动作必须出现,而且必须按 LDRB → EOR → STRB 这个顺序出现。 只要 LDRB → EOR → STRB 这 3 个都出现,就不管编译器怎么调,照样识别
想法二:分辨两种 XOR 变体 。 数 EOR 个数,有一种混淆多了一个xor i,但是忘记在哪看见的…,直接看汇编里 EOR 出现几次
想法三:解析每次调用的参数,写小型 CPU 模拟器
我们要在调到 BLR 时知道 X0/X1/X2/W3 是什么。这就要模拟 CPU 的寄存器。
难点
- key 用 4 条 MOVK 拼出来,得累积
- ADR 是 PC 相对寻址,得算地址
- 寄存器在前面可能被设置过别的值,得记住最后一次赋值,可以写一个小 ARM64 模拟器
1 | class RegTracker: |
跑出来:是
1 | { |
为什么是正向走不是反向找
一开始写的是反向找,从 BLR 往回扫,找最近一次设置 X0/X1/X2 的 MOV 指令。但是
- MOVK 是 4 条拼起来的,反向找只能拿到最后一段,前 3 段拼不上
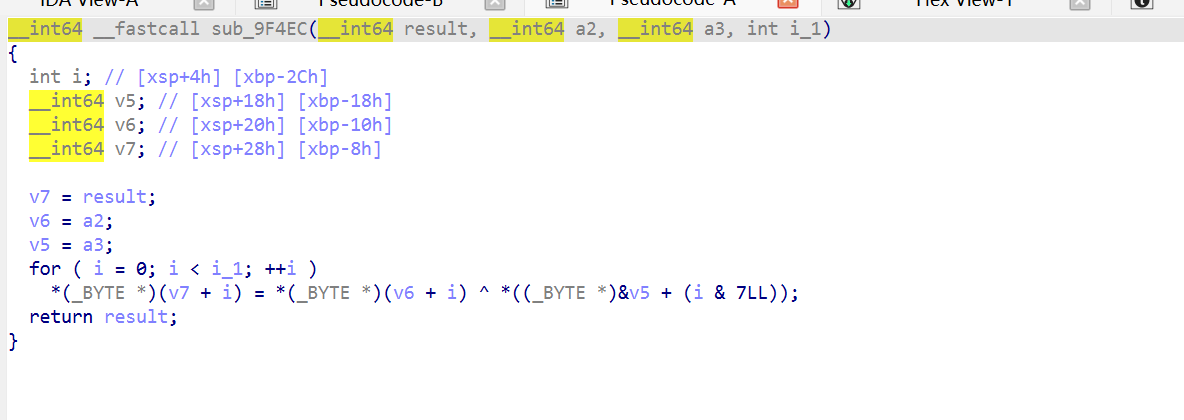
- 寄存器可能被多次重写,反向找容易选错
- 跨基本块时不知道该跟哪条 B 倒回去 ,正向走就没这些问题,从块开头按顺序跑,任何时刻寄存器都是当时的真实值,跟 CPU 一样
1 | import ida_bytes |
1 | ==================================================================================================== |
也可以看到反调试的一些字符
反调试分析及对抗
使用frida会出现花屏10s退出等现象,这里主要使用静态分析方法,可以使用一些trace方法比如stalker等,以下包括分析及对抗方法
[其它] 花屏分析及解决
游戏画面出现马赛克类似,看起来像 shader 损坏,仅在 Frida 实际 hook 时出现,但是起一个空的frida又是正常使用的,一开始以为是inline svc搞了什么东西,后面分析了一圈实在找不到了搜了一下godot机制
可能是如下的问题(我的设备是小米11pro android11,如有相同现象可以跟我讲,初赛也没碰到)
- Godot 4 渲染管线对每帧 timing 敏感
- Interceptor.attach 每次 hook 调用增加几微秒
- 当某条热路径被 hook,累积延迟让 render 线程错过 vsync window
- GPU 在 submit#(N+1) 时还在用 submit#N 的 uniform 数据
- vertex 数据和 fragment shader uniform 不同步,看起来像shader 损坏
导致后面几个part去发生碰撞验证token和flag同时出现效果图的时候看不出来

解决方法
对frida去调godot会产生这种现象,难以解决,可替代的方法是直接编译一个二进制去执行,用NDK编译的外部二进制注入调试
| Frida agent | 外部二进制 | |
|---|---|---|
| 注入方式 | frida-server ptrace注入 frida-agent.so 进游戏进程 |
完全不注入,独立进程 |
| 代码运行位置 | 游戏地址空间内 | 自己的进程,自己的页表 |
| 函数调用劫持 | 在每个被 hook 函数入口写 trampoline → 走 V8/QuickJS 解释 JS callback | 不动游戏的指令字节,游戏函数完全原速运行 |
| 与渲染线程关系 | 共享同进程 任何线程的卡顿都会推迟下一次 vsync | 跨进程 调度器视角是两个独立任务 |
二进制调试示例代码:
1 |
|
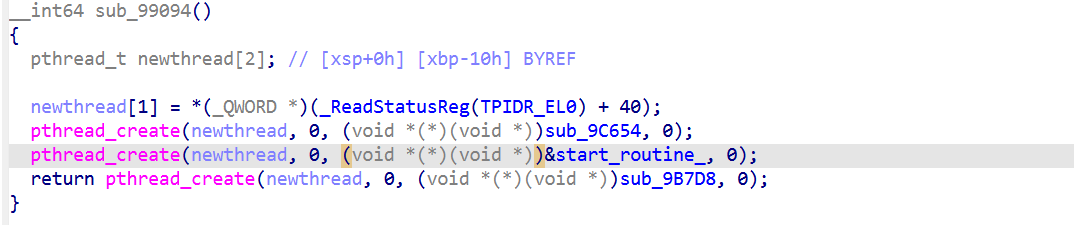
反调1:Tick 10s自毁
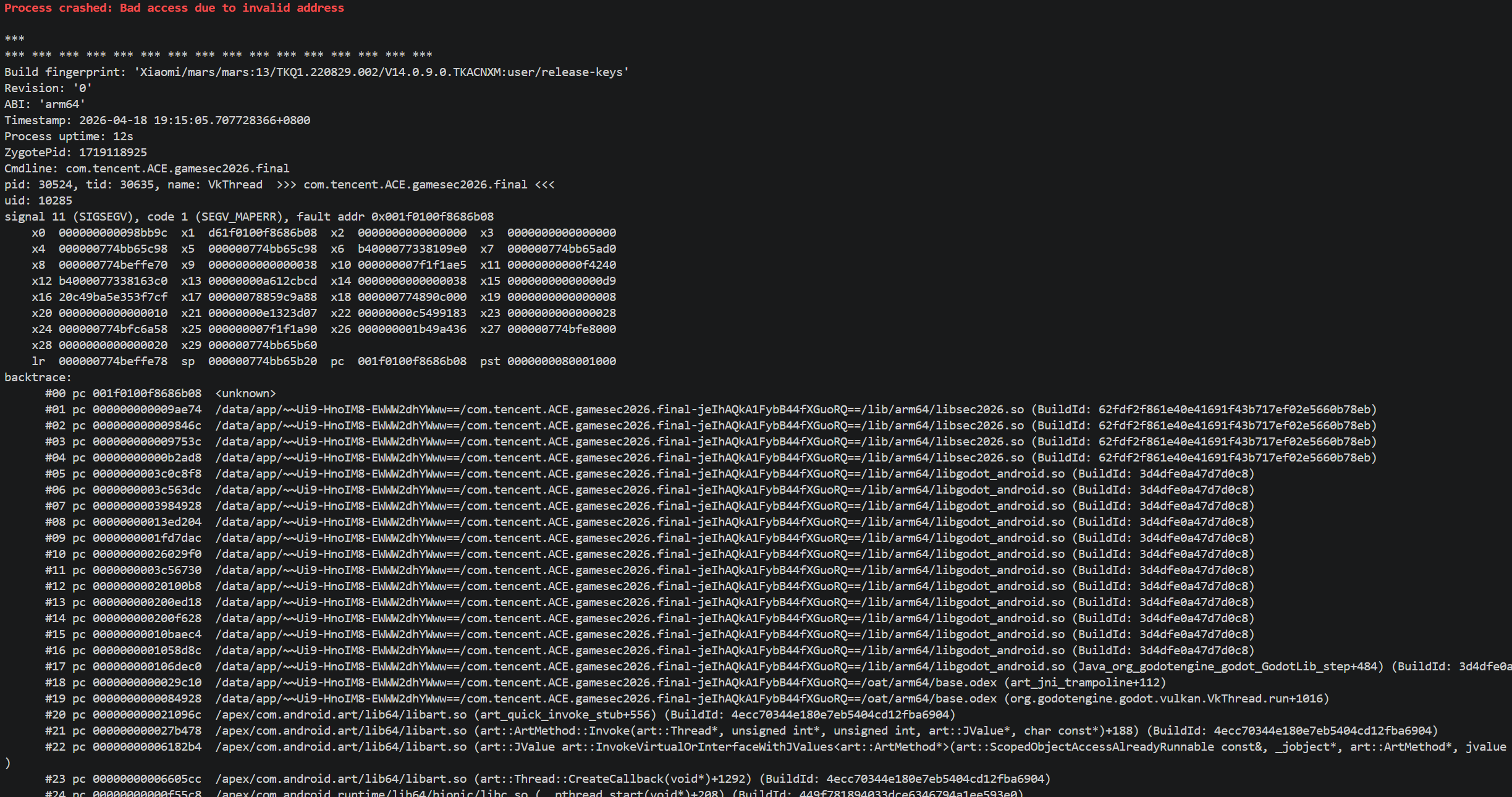
分析
这是唯一写 qword_1834B8 的地方(在 Tick 内部)。只在首次调用 Tick 时执行。
下图为Tick分析章节去混淆后的代码,可以清晰地看到反调试
Entry 5 (0x9AEBC) : 10 秒 diff 判定 核心反调试
1 | 9AEBC STP XZR, XZR, [X29, #-0x18] |
qword_1834B8在第一次 Tick 调用时被初始化为当前时间。
fast path 与 slow path 的差异
1 | fast path (≤10s): CSEL W8 = W25 → W25+0x55 → entry 4 → epilogue RET |
slow path 不是显式 abort(),而是故意构造的 garbage W8 值让二次 dispatch 落到没初始化的 entry 导致跳到 0xD61F0100F8686B08 (BR + invalid) → SIGSEGV。
正常 60fps 游戏每帧应在 16ms 内 tick 一次。两次 tick 间 10 秒 ,两次 tick 间 10 秒 就是大概率有人在干预。
对抗1
最简单的就是pacth,0x9AE14改成普通 RET (c0 03 5f d6),k可以在二进制patch,但是打包不方便,可以使用运行时frida_patch逻辑每 3 秒把 baseline 改成当前时间,diff 永远 = 0 < 10s 永远 fast path,不会被kill(这里还包含了其它模块的代码)
1 | console.log("[bypass] loading"); |

对抗2
当然还有其他方案,比如不用frida,直接编写纯C去调试
patch baseline 入口 ,0x9AE9C 加 LDR X12, [X27, #0x4B8] + 0x9AEB4 CBNZ X12 检查 ,保留 baseline 逻辑,只让 trap 不触发
Frida hook clock_gettime,拦截 __NR_clock_gettime 系统调用,需 Stalker,且开销大。
反调试主循环分析
1 | sleep(3); |
反调2:sub_9B7D8 exit函数页保护检测
分析
sub_9B7D8 里的 mprotect(addr, len, 5)调用0x9BCC4
函数图如上图所示
原理
1 | addr = -PAGESIZE & (uint64_t)&exit; // 把 libc 的 exit 地址按页对齐 |
如果 Frida 等工具用 inline hook 修改了 exit(修改字节码需要先把页设为 PROT_WRITE),那这页可能:
- 被设为 RWX:mprotect 可能成功也可能失败
- 被改了字节但页保护已恢复:mprotect 不会探测到
- 但如果 hook 的页处于已写入但未恢复状态:mprotect 可能返回非 0
对抗1
最简单的方案就是不要去inline hook exit(),一个个函数去hook 对应详细的反调试去分析
对抗2
hook mprotect 强制返回 0,Interceptor.replace(mprotect, () => 0),这里为了演示我们主动去hook exit
1 | console.log("[bypass] loading"); |
方案就是
1 | console.log("[bypass] loading"); |
对抗3
提前在 exit 上 GOT hook,走 PLT 而不是 inline,mprotect 也不会发现
反调3:inline-syscall procfs 扫描 (/proc/self/maps)
分析
这里直接看汇编,看反编译出来的代码有误导性,之前搞错了以为是在做什么签名什么的
1 | ub_9AD3C 实际只有 7 条指令 |
1 | sub_9AD20 同样 7 条指令, 唯一区别是 X3 强制清零 |
这俩是通用 syscall(),把调用解码:
| 调用 | syscall 号 | 解释 |
|---|---|---|
| sub_9AD3C(56, -100, &v73, 0, 0) | __NR_openat = 56 |
openat(AT_FDCWD = -100, &v73, O_RDONLY) |
| sub_9AD20(63, fd, &byte, 1, …) | __NR_read = 63 |
read(fd, &byte, 1) |
这是 inline syscall 的 procfs 扫描 ,用 SVC 直接系统调用,绕开 libc 的 openat,read防 Frida Interceptor.attach('openat'))。
watchdog 把 &v73 当 path 传给 openat,但 &v73 是栈上 16 字节缓冲区,由三层 XOR 解密:
1 | v73 = unk_1682D0 ^ xmmword_58560 ^ broadcast(byte_1834B0) |
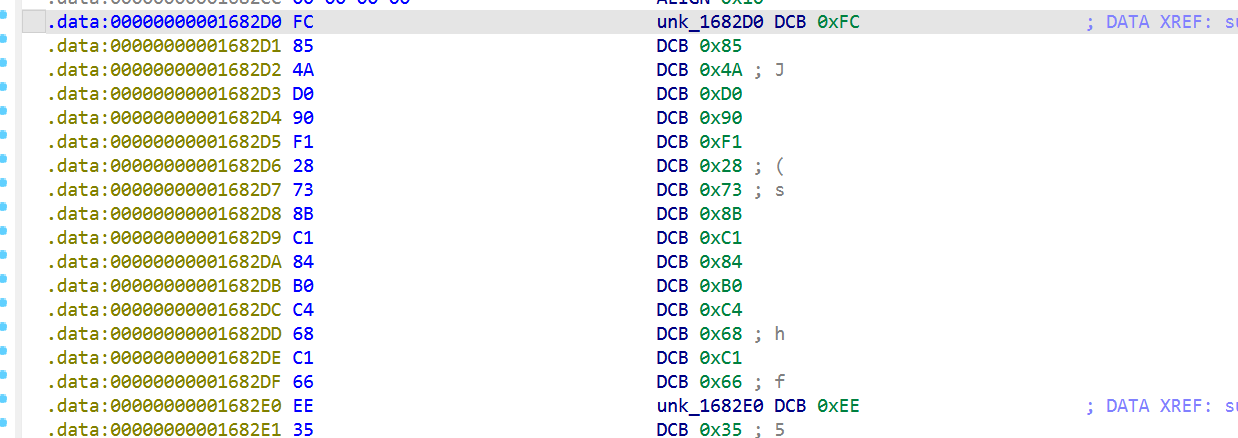

/proc/self/maps,异或出来是这个,那其实逻辑就是
1 | // 1. XOR 解密路径 |
对抗1
block sub_9B7D8 整体不启动
1 | ; |
对抗2
拦截 SVC 指令本身,Stalker 复杂方案
反调4:sub_9C654 (fork + ptrace self-tracer) 和硬件断点
分析
sub_9C654 (fork + ptrace self-tracer)
.init_array在库加载时会启动以下函数
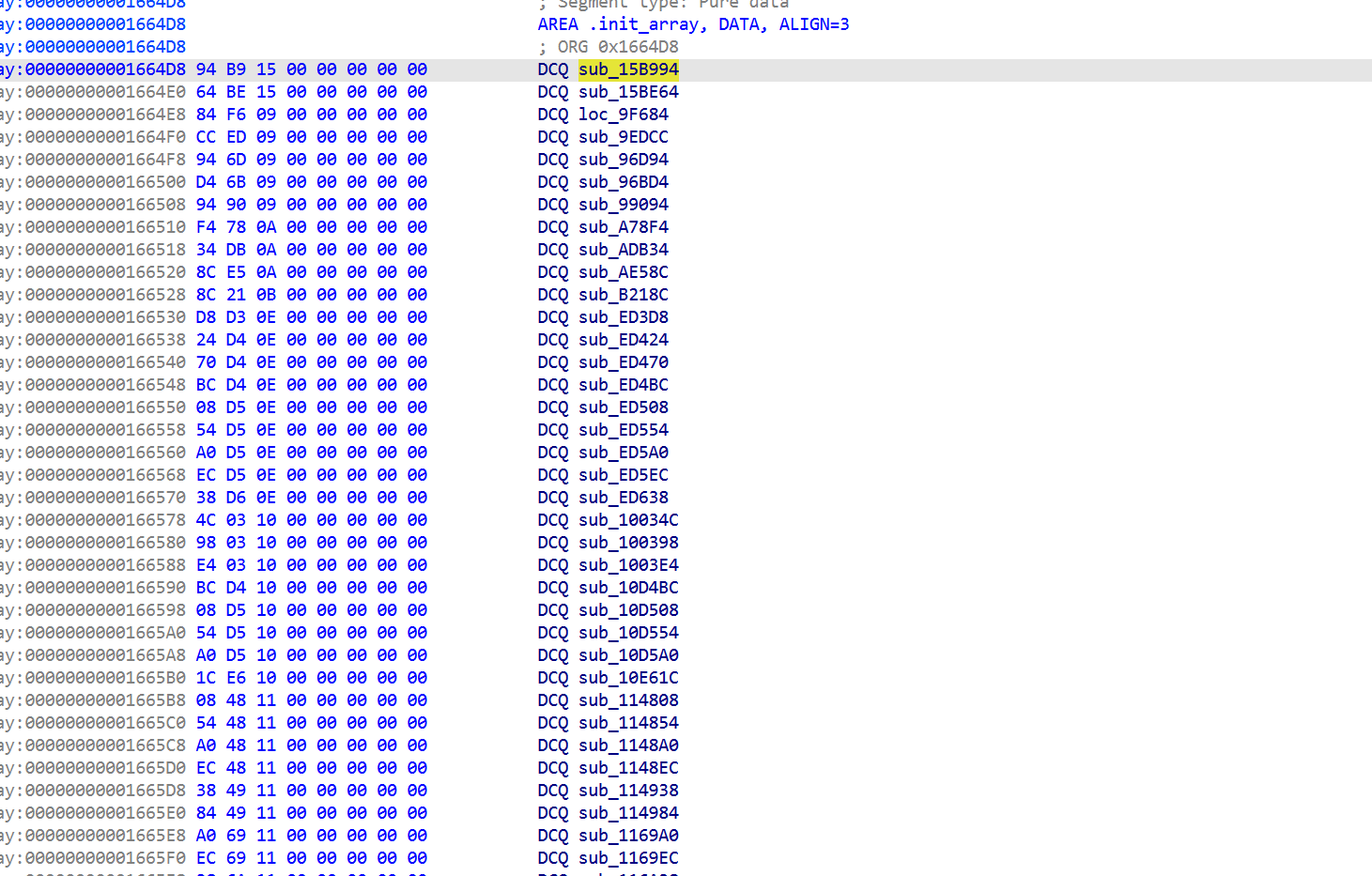
其中
子进程的cmdline仍然是 com.tencent.ACE.gamesec2026.final(fork 后没 exec),所以 ps -A 能看到两个同名进程。
而Linux 一个 task 同一时刻只能有一个tracer。子进程占着 ,外部 Frida工具 attach 都返回 EPERM。
检测:
1 | $ cat /proc/$GAME_PID/status | grep TracerPid |
进程主动 attach 父进程。一旦 attach 成功,Linux 内核把这个父子关系记录到 /proc/31419/status 的 TracerPid 字段里
这也是为什么frida前期调试只能-f启动,不能-n去attach,因为-f时候新建进程,此时 .init_array 还没跑),以下包括两种绕过手段
child 用 exit() 走 _exit_group 终结整个进程组
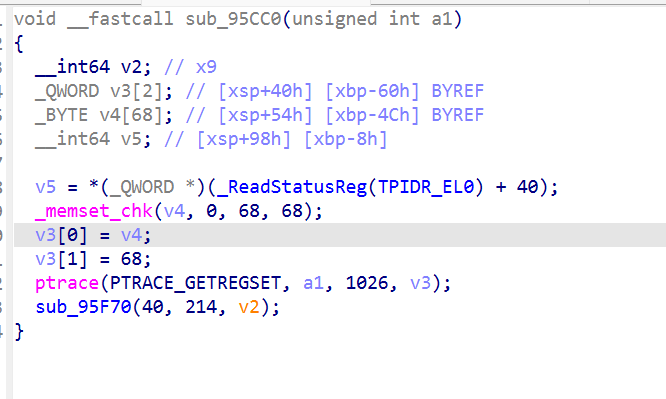
这里还有个硬件断点,1026 = 0x402 = NT_ARM_HW_BREAK,是硬件断点寄存器组(ARM64 的 DBGBVRn_EL1/DBGBCRn_EL1。
把调试器设的硬件断点全擦了,hbreak 失效。
对抗1
Frida:spawn 模式下 hook pthread_create,让 start_routine == sub_9C654 的调用直接 return(不创建子进程) ,Frida 在游戏跑 sub_99094 之前已经注入。我们 hook libc 的 pthread_create,或者直接使用-f
1 | const pthread_create = Module.findExportByName("libc.so", "pthread_create"); |
对抗2
Method D:kill -9 $TRACER_PID,杀完 child 后,父进程不会因为失去 tracer 而自杀(它对自己的 tracer 是单向检测)
1 | // 读 /proc/$pid/status 拿 TracerPid 字段 |
或者
1 | TRACER=$(awk '/^TracerPid:/{print $2}' /proc/$GAME_PID/status); [ "$TRACER" != "0" ] && kill -9 $TRACER |
直接命令行kill
反调5:sub_9CDC4 /proc/self/task 扫描
分析
单独 pthread 线程(由 sub_99094 创建),扫描/proc/self/task
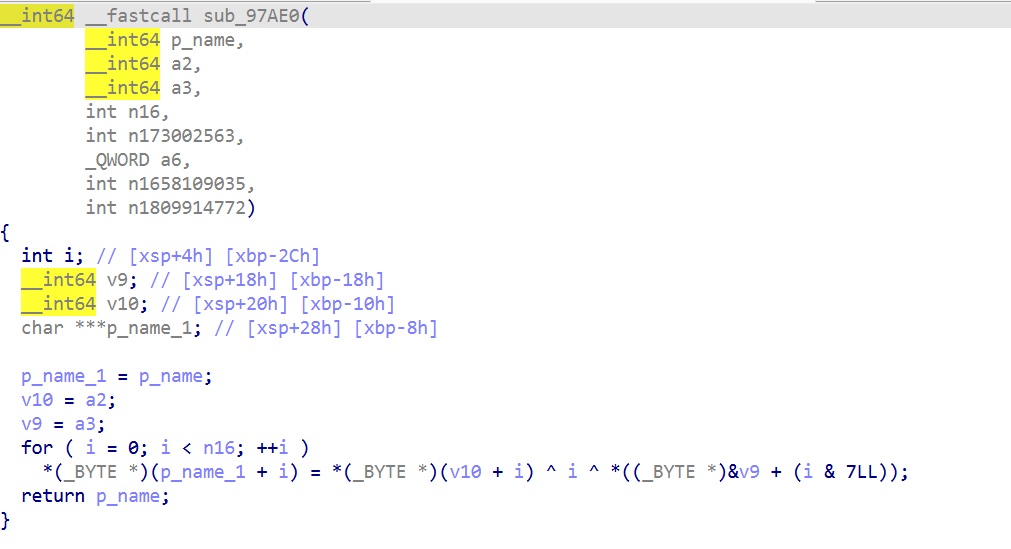
1 | sub_97AE0 另一种 XOR 解密函数 |
后面继续分析下去还有混淆
| Helper | 公式 |
|---|---|
| sub_97AE0 / sub_9A9A8 / sub_96848 | dst[i] = src[i] ^ i ^ key[i & 7] |
| sub_9A224 / sub_984D8 | dst[i] = src[i] ^ key[i & 7](无 ^i) |
| 调用位置 | helper | 源/key/长度 | 解密结果 |
|---|---|---|---|
| 0x9DB9C | sub_97AE0 | unk_58540 / 0x83B3BBD45AD4B5D4 / 16 | "/proc/self/task" |
| 0x9D2EC | sub_9A224 | unk_63A7A / 0xA372088BBE5BB9E2 / 26 | "/proc/self/task/%s/status" |
| 0x9D170 | sub_9A9A8 | unk_63AA0 / 0xB5476C604E8EF907 / 6 | gmain |
| 0x9DA90 | sub_96848 | unk_63A94 / 0x05C11B12D3E63D53 / 12 | gum-js-loop |
1 | // === init (一次性) === |
还有个trap机制
不调 abort/exit/raise,而是把黑名单字符串本身当指针解引用 , SIGSEGV:
1 | ; 0x9DF5C: 匹配 "gmain" 后: |
对抗1
block pthread_create 创建 sub_9CDC4
1 | 'use strict'; |
对抗2
hook opendir 对/proc/self/task返 NULL
1 | ; |
其它
- 改 Frida 线程名
- hook sub_9AD3C (inline openat) 返 -1
- patch 两个 trap 点 (0x9DF70, 0x9E49C) 为 NOP
反调6:sub_99418 /proc/self/fd扫描器
分析
/proc/self/fd 扫描 linjector 特征
被 sub_9CDC4 主循环每轮调用一次。这个其实跟反调试5是同一套线程
3 个新解密字符串(5 个解码器中第 4-6 号):
| 调用 | helper | key | len | 解密结果 |
|---|---|---|---|---|
| 0x99CF8 | sub_967BC (^i ^ key) |
0x3962018E8121661A | 14 | "/proc/self/fd" |
| 0x99E34 | sub_9EB80 (^i ^ key) |
0xA22A7CD9390DA2BD | 17 | "/proc/self/fd/%s" |
| 0x9A048 | sub_97048 (^i ^ key) |
0xEF26CEB5F1E432CD | 10 | "linjector" Frida injector |
sub_99418 完整流程:
1 | qword_183588 = "/proc/self/fd"; |
Frida agent 注入时,Frida-server 创建 /data/local/tmp/re.frida.server/linjector-helper-32之类的辅助进程并保持 fd 打开。注入完成后,目标进程的
/proc/self/fd/<N>会有 symlink 指向这个 path ,strstr linjector就抓到了。
对抗方案和反调试5一致,同一套线程,最简单的方法就是把这块调用给block掉
反调7:sub_96A00 libgodot_android.so 完整性校验
分析
1 | ; sub_96A00 trap state @ 0x96BB8: |
判断逻辑在 sub_9AF98,后面还有一大片混淆
后面去了混淆如下
1 | sub_96A00(target_name = "libgodot_android.so", count) { |
1 | int sub_9EFB4(struct dl_phdr_info *info, ..., void *data) { |
此外,sub_9AF98 不只有CRC,它还是 Tick baseline 的更新者
1 | ; sub_9AF98 在 0x9B088..0x9B110 包含完整的 clock_gettime + baseline 写入: |
也就是说反调试的设计逻辑如下:
- Tick 单独存在没意义(baseline 永远不更新, 第一次就过 10s)
- sub_9AF98 是唯一合法 heartbeat
- block watchdog 间接触发 Tick ,这就是为啥之前的脚本必须必须
setInterval(refreshBaseline, 3000)手动喂
sub_9AF98是CRC其中
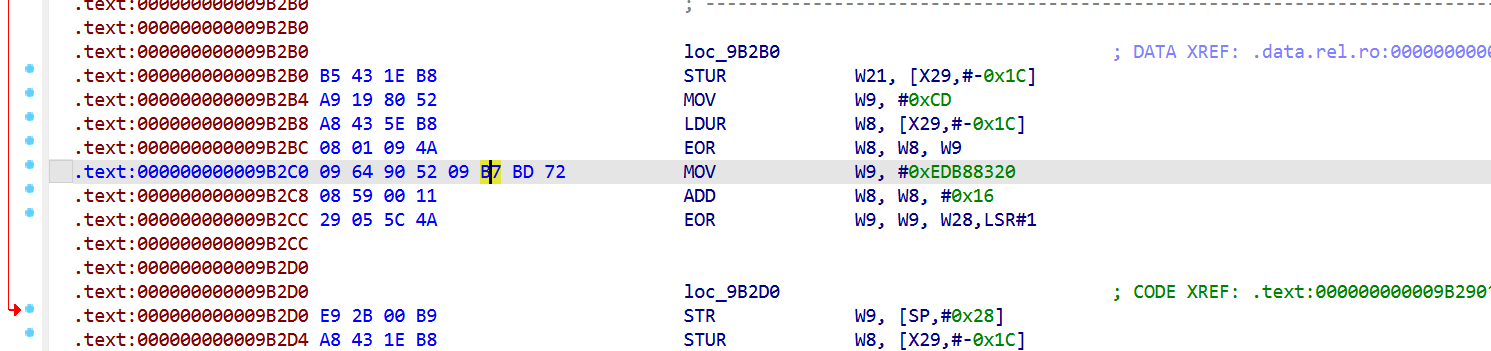
0xEDB88320 = bit_reverse(0x04C11DB7) 标准 CRC32实现逻辑。
加上其他 CRC32 特征:
- entry 0x9B2DC:
LDRB W9, [X8, X9]- byte-by-byte load (CRC 输入) - entry 0x9B33C:
TST X10, #0xFFF- page mask 检查 (验证 phdr 地址对齐) - entry 0x9B35C:
MVN W0, W8-return ~crc(CRC 标准 final XOR with 0xFFFFFFFF) - 用
EOR ...LSR#1模式 (位移 CRC 算法核心)
设计巧思
sub_9AF98 同时做 heartbeat + verify, 形成 :
- libgodot 没改 , CRC 对, 顺便喂了 Tick baseline ,一切正常
- libgodot 改了 (LD_PRELOAD / patch), CRC 错, exit_group
- block watchdog , sub_9AF98 不调 , 既没 verify 也没 heartbeat ,Tick 10s 内 trap
1 | int sub_9AF98(void *data, size_t length) { |
双重防御:
- 改 libgodot 立即被 CRC 抓
- 阻止 verify 间接触发 Tick
对抗
直接 block sub_9B7D8 watchdog,sub_96A00 不被调,整个流程不跑
1 | ; |
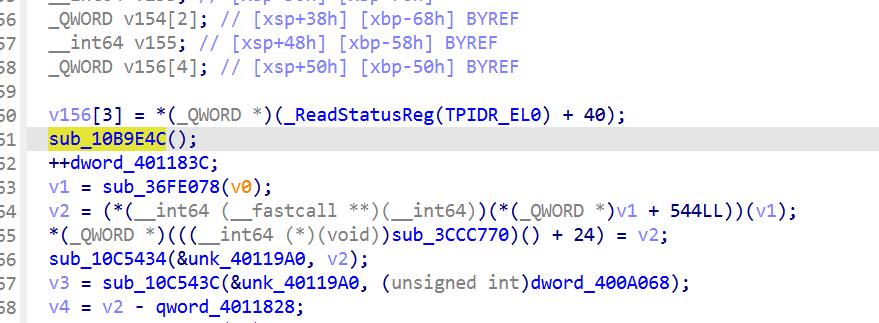
反调8:sub_10B9E4C(libgodot 内存自校验)
分析
sub_10BAB00 = Main::iteration (Godot 标准, 但作者在第一行插入了 sub_10B9E4C() 调用)
在libgodot_android.so中,被 Godot 标准 JNI 函数 Java_org_godotengine_godot_GodotLib_step 间接调用(每帧)。
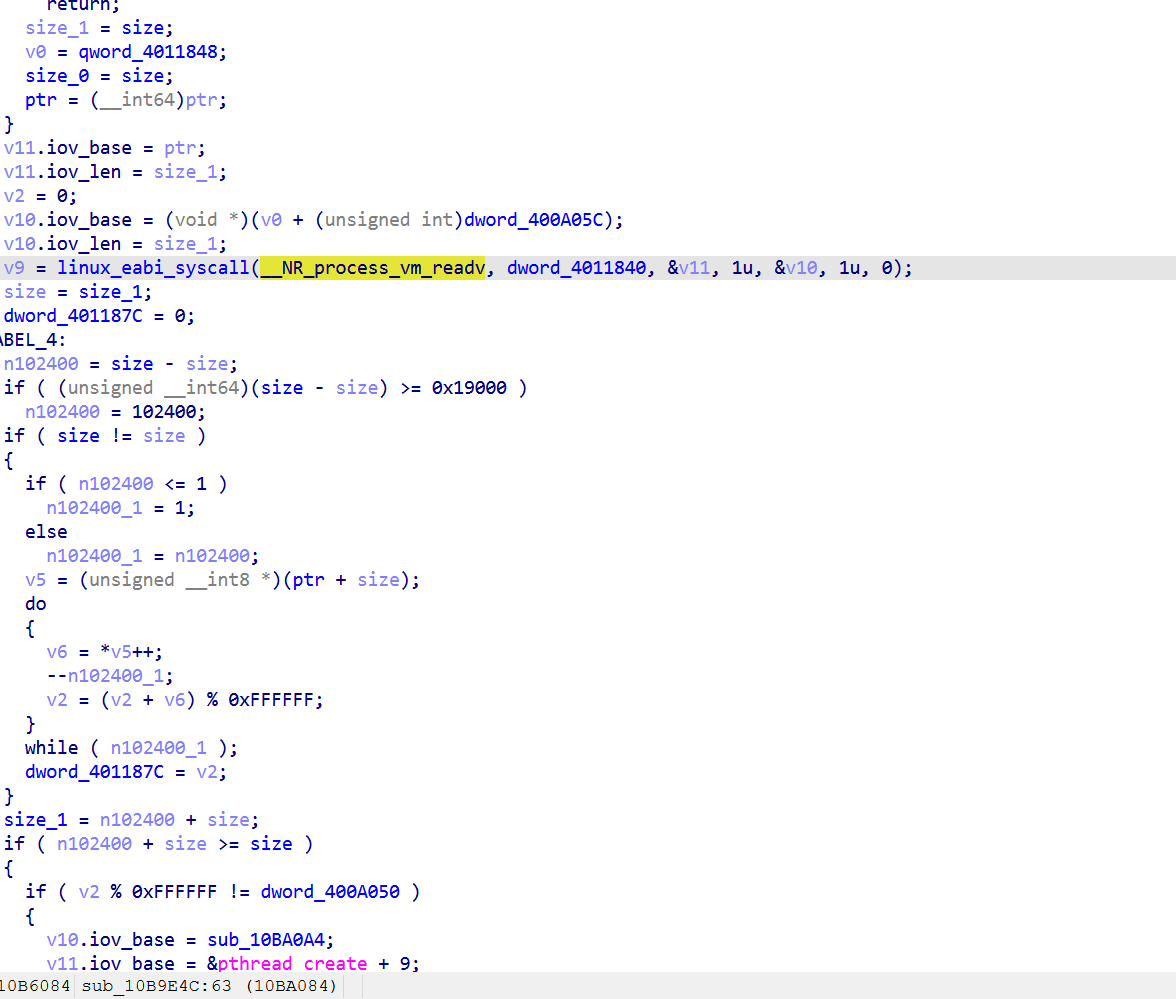
特点:
不依赖 dl_iterate_phdr,直接用 process_vm_readv读 /proc/self/mem
hash 是某种滚动求和
1
2
3
4n102400 = min(remaining, 0x19000);
for (i = 0; i < n102400; i++) {
v2 = (v2 + buf[i]) % 0xFFFFFF;
}结果 mod 0xFFFFFF 跟 dword_400A050比
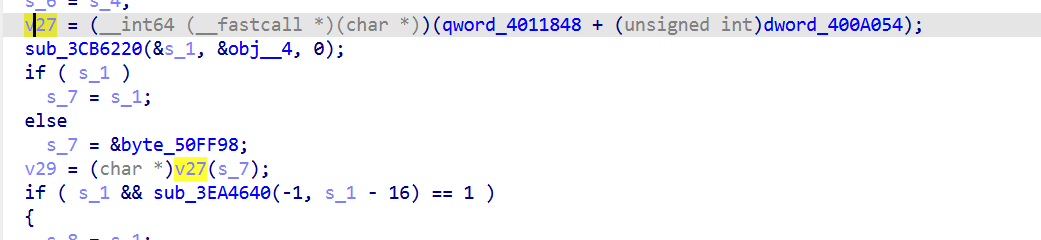
dword_400A050 是硬编码期望值
只在第一次调用 v27(s_7) 时执行(初始化qword_4011848)。之后 qword_4011848 非 0,跳过校验,不通过则会自毁

借 Godot 标准退出流程, logcat 看起来像用户主动关游戏
并且经过测试,貌似只有part3的时候会触发,查看伪代码返现这里的dword_400A054值是0xA9A7C针对的就是part3阶段的入口绝对地址。
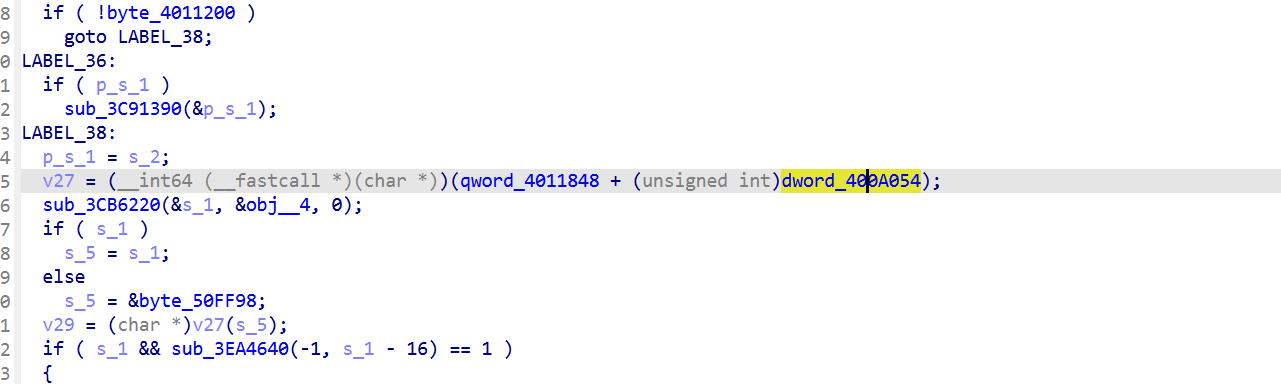
对抗
不要用Memory.patchCode 改 libgodot 字节
不然可以让校验函数立刻 return success,不计算
1 | Interceptor.replace(godotBase.add(0x10B9E4C), |
或者hook process_vm_readv,从干净副本读 ,启动时 dump libsec2026 .text 完整副本到自己 buffer,sub_10B9E4C 调 process_vm_readv 时把请求重定向到副本
下面这份代码是hookpart3时用的发现被kill使用了对应的反反调试,监控到触发了反调试,这里使用的是让校验函数立刻 return success这种方法,成功解决了这个反调试

1 | ; |
[其它] 内联SVC syscall反 hook 加固
sub_9AD3C是个 7 指令通用 SVC wrapper:


类似的还有sub_9CB30。libsec2026 内部所有敏感 syscall(ptrace, mprotect, openat, prctl等)都走这条,不经 libc。
- Interceptor.attach(Module.findExportByName(“libc.so”, “ptrace”), …) 拦不到
- 同理 mprotect、openat、fork ,全拦不到
- 想拦只能用 Frida Stalker 在指令级监控 SVC 0 指令,或者其它比如ebpf
反调试代码汇总
使用方式(不起part3)
1 | frida -U -f com.tencent.ACE.gamesec2026.final -l frida_bypass_complete.js -o /tmp/bypass.log |
可以加part3的trace不崩
1 | ; |
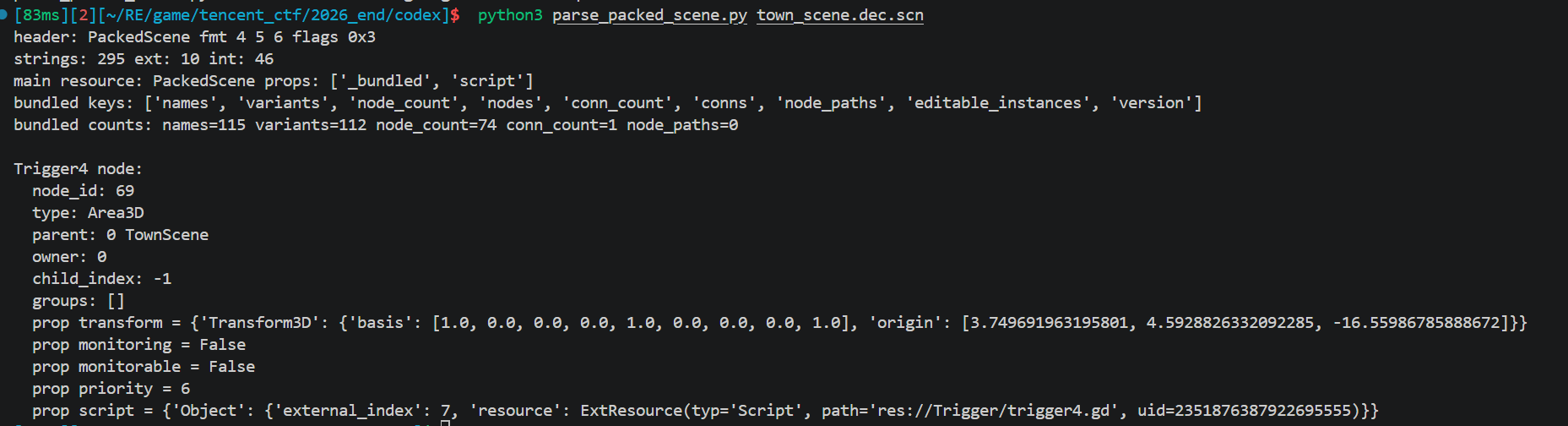
解密场景文件
PackedScene 内部是 Godot 自己的二进制格式:
- nodes 数组:节点表(每个节点有 name、parent_idx、type、property 列表)
- variants 数组:所有节点 property 引用的实际值(Transform3D、StringName、Resource 引用等)
尝试在网上找一些开源工具直接解,但是没找到,解析后能直接拿到每个 Node3D 子类的 transform.origin。
阅读godot源码
godot/core/io/resource_format_binary.cpp at master · godotengine/godot
头格式,编码布局
godot/scene/resources/packed_scene.cpp at master · godotengine/godot
RSRC 头解析
文件起始固定 RSRC magic 后是定长头:
1 | big_endian (1 byte) |
flags 里有几个位特别要注意,否则后面尺寸算错崩盘:
- FORMAT_FLAG_NAMED_SCENE_IDS = 1
- FORMAT_FLAG_UIDS = 2
- FORMAT_FLAG_REAL_T_IS_DOUBLE = 4 — 决定 Vector3和Transform3D 是 float 还是 double
- FORMAT_FLAG_HAS_SCRIPT_CLASS = 8
Variant 类型 ID 常量,parse_variant() 用一个枚举 ID 分发,需要的几个:
1 | VARIANT_NODE_PATH = 22 |
按上面 schema 全部解析完,对每个 Node3D 子类节点:
1 | node = nodes_table[i] |
跑一遍 town_scene 就能把 4 个 Trigger 和 InstancePos 的世界坐标拉出来
需要先解密出来场景文件
然后
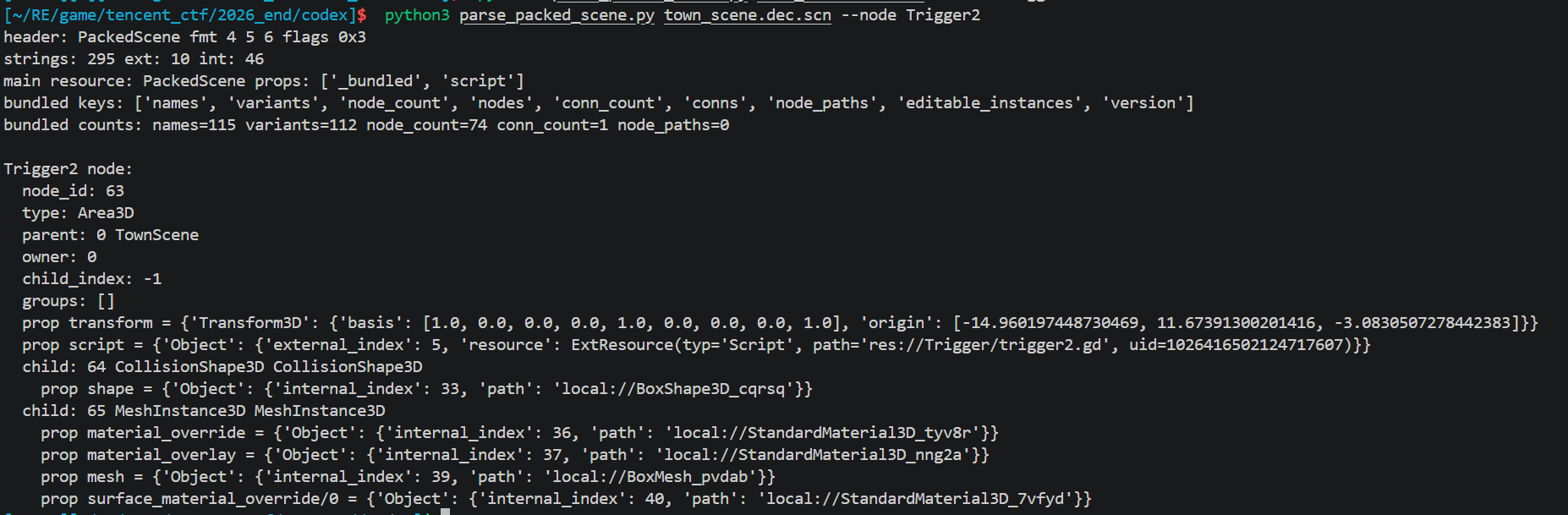
1 | python3 parse_packed_scene.py town_scene.dec.scn |
完整代码:
1 | #!/usr/bin/env python3 |
1 | Trigger1.transform.origin = (-12.845476, 5.822042, -15.349906) |
part1 绿色方块
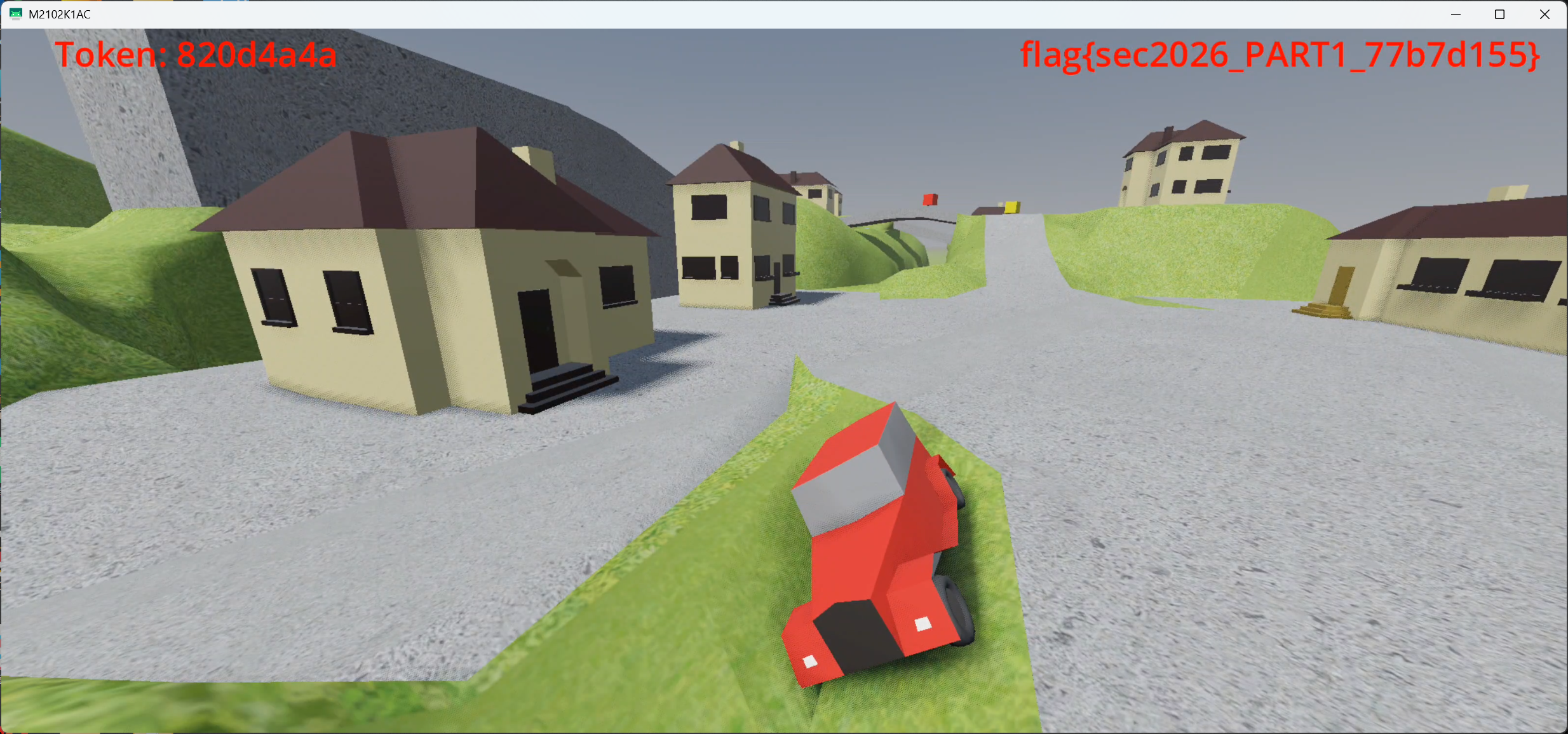
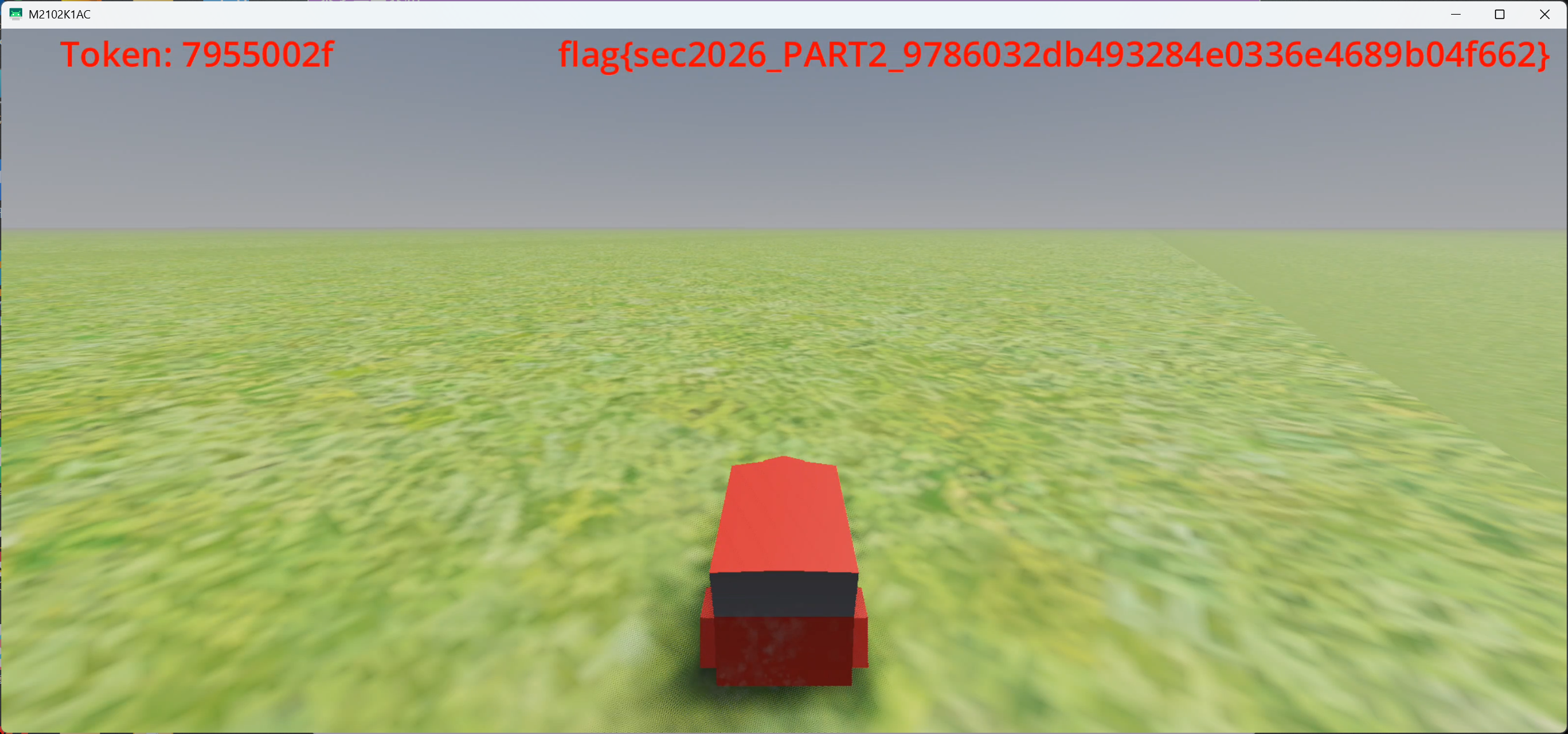
flag 逻辑获取分析
绿色方块,完全在 GDScript 内实现,是一个 8 轮 Feistel 密码:
1 | extends Area3D |
大致为输入 token,拆为 L+ R,然后过 8轮 Feistel,Feistel的内部大概如下:
- F(R, key, rn) = 对每个字节 b:
b' = ((((b ^ key[(j+rn)%13]) * 7 + rn) & 0xff) << 3 | ... >> 5) & 0xff - L’, R’ = R, L XOR F(R)
1 | var _rn := 0 |
密钥用字符串拼接构造
1 | var _kp := ('Sec' + '2026' + '_God' + 'ot').to_utf8_buffer() |
Sec2026_Godot
flag为flag{sec2026_PART1_<8 hex>}
获取flag
过程分析
根初赛类似,trigger都在房顶上,要想获得flag需要主动触发碰撞函数,由于之前用Frida hook会出现花屏,因此我们这使用纯C去进行绕过
有一种比较简单的方法是,其实大同小异:
把 Trigger2 挪到玩家车出生点 (8.0, 3.36405, -16.0)。挪靠 ptrace + 调 Godot setter,跟 trigger4_call.c 的范式一致。
2
3
4
5
6
7
8
9
10
11
12
13
14
玩家车 RigidBody3D 物理位置 挪车
↓
PhysicsServer 步进 + 重叠检测 物理服务器内部缓存
↓
PhysicsServer 通知 Area3D 有 body 进入 调内部通知"
↓
Area3D::_body_inout 派发 body_entered 发信号
↓
Godot Signal 总线分发到所有连接者
↓
trigger2.gd::_w7(body) 直接调脚本回调
↓
读 Label.text → _fe(token) → 写 Label2.text链条上每一段都可以从外部直接 hook,越往下游越接近显示 flag,但对应的函数签名也越复杂(要构造 Godot 内部的数据结构)。trigger2_call 选的是最上游的挪车 ,因为只要传一个 12 字节 Vector3,最简单。
从外部进程用 pwrite(/proc/PID/mem, …) 直接把 Trigger2 对象内存里那 12 字节 transform.origin 改成 (8, 3.36, -16),下一帧物理引擎就该看到 trigger2 在新位置了 ,跟玩家车重叠 ,触发碰撞
不能用纯字节写:Godot 4 PhysicsServer 是 push 模式,光改 Area3D 内 transform 字节不会同步给物理引擎,下一帧 area_overlap 仍按旧位置算。必须真调 setter,让它通过 _propagate_transform_changed → PhysicsServer::area_set_transform 的链路推送。
Godot 4 把 Node 层(场景树里的 Area3D 对象)和 Physics 层(PhysicsServer 内部的物理对象)完全分开存

两边各存一份 transform。PhysicsServer 不会主动去 Node 内存读最新值(pull 模式),而是等 Node 层主动调 PhysicsServer::area_set_transform 把新值推过来(push 模式)。 正常游戏流程是:
- GDScript 写 area.position = …然后 触发 setter
- setter 写 Node 层 local_transform.origin
- setter 调 _propagate_transform_changed(this)
- 它调 PhysicsServer::area_set_transform(rid, new_transform)
- PhysicsServer 内部 areas[rid].transform 被更新
- 下一帧物理 step 用新 transform 算重叠
既然字节写不行,那就让 Godot 自己执行第 2-5 步,通过 ptrace 让游戏进程跳进 Node3D::set_global_position(Vector3) 函数入口,参数填 (8, 3.36, -16)。函数内部会按上面 5 步走完,PhysicsServer 自动同步。
需要确认这个函数的地址, Godot 中函数符号大部分被 strip 掉,所以
- 在 binary 里找字符串 “set_global_position”
- 反查谁引用这个字符串 , 那段引用代码就是 ClassDB 注册调用
- 注册调用的格式固定是 ClassDB::bind_method(D_METHOD(“set_global_position”, “position”), &Node3D::set_global_position) , 编译后会有一个 ADR X0, 真实函数地址 紧挨在加载字符串地址的前几条指令
- 找出那个 ADR 加载的地址,就是 Node3D::set_global_position 的真实偏移
1 | strings -t x final/lib/arm64-v8a/libgodot_android.so | awk ' |
第一个 PT_LOAD 的 p_offset == p_vaddr == 0,所以 file offset == 库内 vaddr。set_global_position 字符串地址 = 0x4178ba
用Capstone 扫 ClassDB::bind_method 注册
Godot 4 的 Node3D::_bind_methods() 内每条 bind_method 编译为 8 条指令 pattern:
1 | ADR X0, <method_ptr> 真正的 setter 函数地址 |
BL 的目标是按签名共享的工厂,真正的 method ptr 是它前 4 条指令的 ADR X0 加载值。
1 | import struct, capstone |
输出
1 | set_global_position fn=0x254583c |
Node3D::set_global_position 这个函数机器码,在 libgodot_android.so 里相对文件起始 0x254583c 字节的位置。
验证签名
把 set_global_position 函数前几条机器指令打印出来看,通过 prologue 用了哪些寄存器反推它的参数怎么传
从 ClassDB 注册点找到了 Node3D::set_global_position 0x254583c,但只知道地址,不知道调用约定
1 | md = capstone.Cs(capstone.CS_ARCH_ARM64, capstone.CS_MODE_ARM) |
读 .so 文件 0x254583c 处的 128 字节,让 capstone 按 ARM64 反汇编,逐条打印直到第一个 RET。
1 | 0x02545854 mov x20, x1 ; 把 X1 备份到 X20 |
ARM64 AAPCS 调用约定:函数被调用时 X0 是第 1 个参数,X1 是第 2 个,依此类推。X19/X20 是 callee-saved 寄存器。
函数一进来就把 X0 和 X1 备份到 X19/X20,说明 X0 和 X1 都是参数,且要在函数体里反复用到。
1 | 0x0254586c ldr x8, [x20] ; 从 [X20] 读 8 字节 |
X20 是备份的 X1。函数把 X1 当指针用(ldr x8, [x20] = X20 指向的内存读 8 字节):
- [X1+0] 8 字节 = Vector3 的 x (4) + y (4)
- [X1+8] 4 字节 = Vector3 的 z
加起来正好 12 字节 = 3 个 float = 完整 Vector3。
1 | void Node3D::set_global_position(this, &Vector3); |
拿到这些接下来就是去替换位置,我们在上一节已经知道几个坐标,我们需要先处理Trigger2的
1 | (-14.960197, 11.673913, -3.083051) |
观察内存发现4 个 Area3D 在堆上连续分配(间距 0xc00 字节)。每个 Area3D dump 时窗口要 < 0xc00 否则越界扫到下一个 area 的 transform,把它误判成自己的。用 0x800 窗口刚好
1 | static int find_trigger2(int mem_fd, uint64_t *area_objs, int n_area, |
多次尝试发现 Trigger2 的 origin 字段在对象 +0x3a4。
ptrace-call 传 Vector3 引用(vs trigger4 的整数参数)
传整数 set_monitoring(area, 1),传 Vector3 引用需要先把 12 字节数据写到目标进程能读到的内存,再让 X1 指向它。
1 | static int remote_call_set_global_position(pid_t tid, int mem_fd, |
代码总流程大致是
1 | 1. find_game_pid 扫 /proc/*/cmdline 找游戏 PID |
后面两个都是类似的思路
1 |
|
编译:
1 | $NDK/bin/aarch64-linux-android24-clang -O2 -pie trigger2_call.c -o trigger2_call |
使用方法直接push到手机上给权限执行即可
peek可以查看从外部读运行中游戏进程的指定内存地址,dump 字节出来
1 | int main(int argc, char **argv) { |
flag截图
后面可以直接拿去验证算法真实性
flag生成算法及逆算法 C
编译:
1 | gcc -O2 -Wall -o part1_solver part1_solver.c |
1 |
|

part2 红色方块
获取flag
过程分析
原理和之前trigger2一样
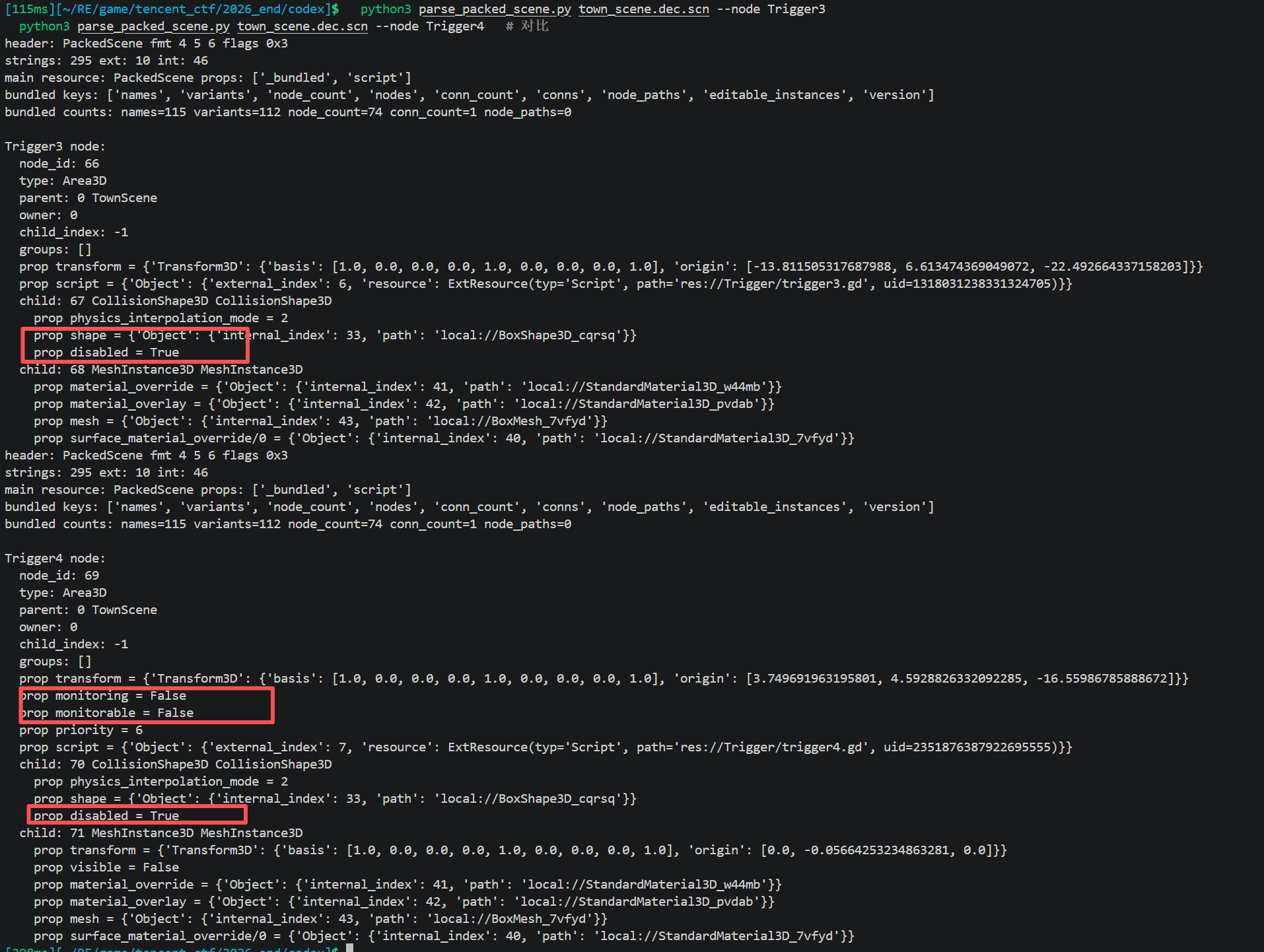
trigger2.gd 默认 monitoring=1 , collision enabled , visible,只是位置高车开不到
trigger3 的 GDScript 结构相同,但初始可能 monitoring=0 disabled=1 visible=0(红色方块可能未开启碰撞属性)
对比一下就知道了
可以试一下强制碰撞
1 | 1. find_game_pid 找游戏进程号 |
其中set_monitoring(trigger3, true) , 让 area 监听碰撞
ptrace_call libgodot+0x25F94A4 (Area3D::set_monitoring), X0=trigger3, X1=1
Area3D 有两个开关:
- monitoring(监听):area 是否检测有 body 进入 , 离开
- monitorable(被监听):area 是否对其他 area 可见
monitoring=false 时 PhysicsServer 不会发 body_entered 信号,车进入 area 也没反应。这步把它打开。
注意 set_monitoring(true) 不只是改字段值,会调 PhysicsServer::area_set_monitor_callback 注册物理回调。
还有提携setter代码的定位
之前定位的一些关键逻辑 再libgodotengine.so里
| 函数 | libgodot 偏移 |
| ——————————– | ————- - |
| Node::get_child | 0x1FD9BD0 |
| Area3D::set_monitoring | 0x25F94A4 |
| Area3D::set_monitorable | 0x25FAA0C |
| CollisionShape3D::set_disabled | 0x2624AB4 |
| Node3D::set_visible | 0x12424A8 |
| Node3D::set_global_position | 0x254583C |
完整代码:
1 | $NDK/bin/aarch64-linux-android24-clang -O2 -pie trigger3_call.c -o trigger3_call |
1 |
|
flag截图
后面可以直接拿去验证算法真实性
flag 逻辑获取分析
trigger3.gd 红色方块,可以看到调用 native Process(buf) 方法
1 | extends Area3D |
- 调用
_gx.Process(_buf),buf 是 token 字符串的 UTF-8(8 字节,例如 b”12345678”) - 输入是 8 字节,不是 4 字节解码后的 hex bytes
- GDScript 中定义的
_h2b/_b2h/_xb/_rf似乎没被调用,可能算法在 C++ 中重新实现 - 密钥应仍是 “Sec2026_Godot”
两种解法,但是本质都是获取中间信息推动解密,算法识别
Frida调试 解法一
因为一开始先分析的process所以没绕过反调试,但是10s的空间足够我们进行一些调试,获取一些信息
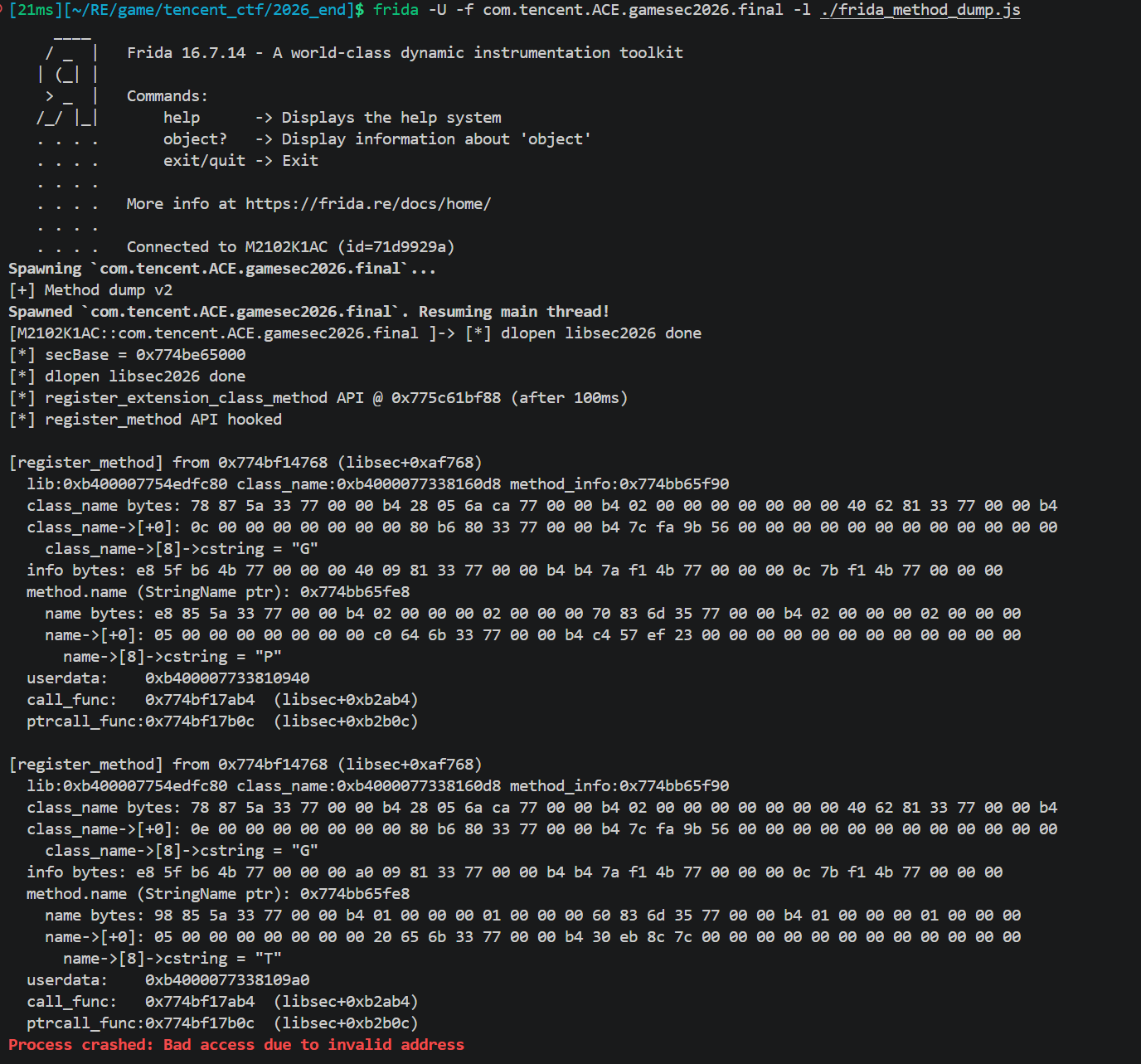
libsec2026.so 在 entry_funcs注册 GDExtension,通过 classdb_register_extension_class_method把 Process 字符串绑定到某个 native 函数。
用 IDA 查找字符串 Process的引用,找到注册调用点。注册结构体第二个字段指向一个 MethodBindCustom vtable,vtable 里含
call回调。用 Frida hook classdb_register_extension_class_method打印参数,来找process对应的native函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130console.log("[+] Method dump v2");
let secBase = null;
let installed = false;
['android_dlopen_ext', 'dlopen', '__loader_dlopen', '__loader_android_dlopen_ext'].forEach(name => {
const fn = Module.findExportByName(null, name);
if (!fn) return;
Interceptor.attach(fn, {
onEnter(args) { this.path = args[0] ? args[0].readCString() : null; },
onLeave(retval) {
if (this.path && this.path.indexOf("libsec2026") >= 0) {
console.log(`[*] dlopen libsec2026 done`);
secBase = Module.findBaseAddress("libsec2026.so");
if (secBase && !installed) { installed = true; install(); }
}
}
});
});
secBase = Module.findBaseAddress("libsec2026.so");
if (secBase && !installed) { installed = true; install(); }
function hex(buf, len) {
if (!buf) return "(null)";
return Array.from(new Uint8Array(buf)).slice(0, len||32).map(b=>b.toString(16).padStart(2,'0')).join(' ');
}
function install() {
console.log("[*] secBase =", secBase);
// Anti-debug bypass
const ANTIDEBUG = [0x9C654, 0x9CDC4, 0x9B7D8].map(o => secBase.add(o).toString());
const ptrace = Module.findExportByName("libc.so", "ptrace");
if (ptrace) Interceptor.replace(ptrace, new NativeCallback(()=>0,'long',['int','int','pointer','pointer']));
const pthread_create = Module.findExportByName("libc.so", "pthread_create");
if (pthread_create) {
Interceptor.attach(pthread_create, {
onEnter(args) {
if (ANTIDEBUG.indexOf(args[2].toString()) >= 0) {
console.log(`[BLOCK antidebug] ${args[2]}`);
args[2] = ptr(0);
}
}
});
}
// Poll for the API function pointer to be loaded
let pollCount = 0;
const poller = setInterval(() => {
pollCount++;
const off_183DF8 = secBase.add(0x183DF8);
const apiFn = off_183DF8.readPointer();
if (!apiFn.isNull()) {
clearInterval(poller);
console.log(`[*] register_extension_class_method API @ ${apiFn} (after ${pollCount*100}ms)`);
hookRegister(apiFn);
} else if (pollCount > 200) {
clearInterval(poller);
console.log("[!] Gave up waiting for API ptr");
}
}, 100);
}
function hookRegister(apiFn) {
Interceptor.attach(apiFn, {
onEnter(args) {
// Only log if caller is in libsec2026
const ret = this.returnAddress;
const inSec = secBase && ret.compare(secBase) >= 0 && ret.sub(secBase).compare(ptr(0x200000)) < 0;
if (!inSec) return;
console.log(`\n[register_method] from ${ret} (libsec+0x${ret.sub(secBase).toString(16)})`);
console.log(` lib:${args[0]} class_name:${args[1]} method_info:${args[2]}`);
try {
// Try to read class name (StringName, points to data structure)
const sn = args[1];
console.log(` class_name bytes: ${hex(sn.readByteArray(40))}`);
// StringName layout: pointer to refcounted string
const inner = sn.readPointer();
if (!inner.isNull()) {
console.log(` class_name->[+0]: ${hex(inner.readByteArray(40))}`);
// Look for cstring
for (const off of [0,4,8,12,16,20,24]) {
try {
const p = inner.add(off).readPointer();
const s = p.readCString();
if (s && /^[A-Za-z_][A-Za-z0-9_]*$/.test(s)) {
console.log(` class_name->[${off}]->cstring = "${s}"`);
}
} catch(e){}
}
}
} catch(e) {}
try {
const info = args[2];
console.log(` info bytes: ${hex(info.readByteArray(80))}`);
const namePtr = info.readPointer();
console.log(` method.name (StringName ptr): ${namePtr}`);
if (!namePtr.isNull()) {
console.log(` name bytes: ${hex(namePtr.readByteArray(40))}`);
try {
const nameInner = namePtr.readPointer();
if (!nameInner.isNull()) {
console.log(` name->[+0]: ${hex(nameInner.readByteArray(40))}`);
for (const off of [0,4,8,12,16,20,24]) {
try {
const p = nameInner.add(off).readPointer();
const s = p.readCString();
if (s && /^[A-Za-z_][A-Za-z0-9_]*$/.test(s)) {
console.log(` name->[${off}]->cstring = "${s}"`);
}
} catch(e){}
}
}
} catch(e) {}
}
const userdata = info.add(8).readPointer();
const callFn = info.add(16).readPointer();
const ptrcallFn = info.add(24).readPointer();
console.log(` userdata: ${userdata}`);
console.log(` call_func: ${callFn} (libsec+0x${callFn.sub(secBase).toString(16)})`);
console.log(` ptrcall_func:${ptrcallFn} (libsec+0x${ptrcallFn.sub(secBase).toString(16)})`);
} catch(e) { console.log(` parse err: ${e}`); }
}
});
console.log("[*] register_method API hooked");
}
最主要的信息是
1
2call_func: 0x774bf17ab4 (libsec+0xb2ab4)
ptrcall_func: 0x774bf17b0c (libsec+0xb2b0c)这意味着 Process 和 Tick 共用同一个分发函数 libsec+0xb2ab4
sub_97704内部只做 userdata 解包,真正算法在其调用的Sub_A936C,sub_A936C 又调用sub_A7900(key schedule) 和sub_A7194(cipher)。
同时也发现反调试的端倪
后续定位到sub_97704
sub_A7194这里一F5就会崩溃
尽量从汇编分析
sub_A7194被 OLLVM 打散,IDA decompile 直接失败,disasm 看到 38 条 dispatcher 指令 + BR X9 间接跳。
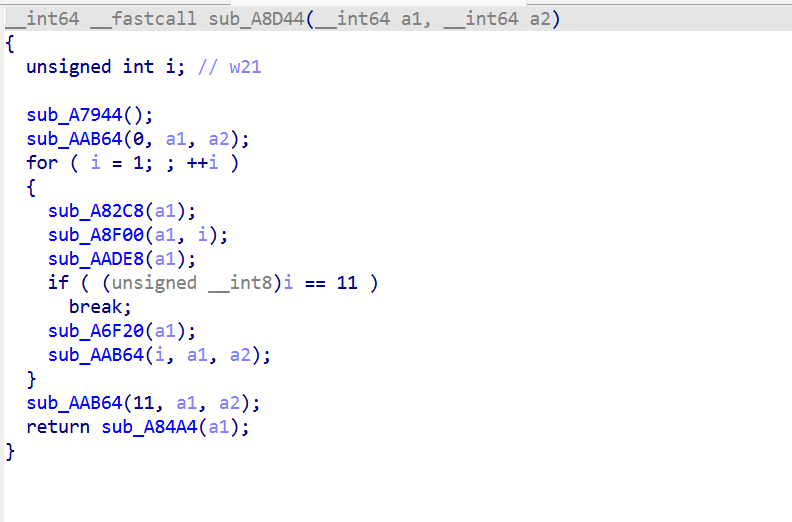
做法:
数 subfunction:在 IDA 里把sub_A7194全部直接 callees 列出来,发现几个反复被调用的函数:sub_A82C8, sub_A8F00, sub_AADE8, sub_A6F20, sub_AAB64, sub_AA9B0, sub_A7944, sub_A8D44。这有点像AES。
Frida Stalker call summary 统计实际调用次数。得到:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92console.log("[+] Stalker call trace post-AAB64(11)");
let secBase = null, installed = false;
['android_dlopen_ext','dlopen','__loader_dlopen','__loader_android_dlopen_ext'].forEach(name => {
const fn = Module.findExportByName(null, name);
if (!fn) return;
Interceptor.attach(fn, {
onEnter(args) { this.path = args[0] ? args[0].readCString() : null; },
onLeave(retval) {
if (this.path && this.path.indexOf("libsec2026") >= 0 && !installed) {
installed = true;
secBase = Module.findBaseAddress("libsec2026.so");
setTimeout(doit, 3000);
}
}
});
});
secBase = Module.findBaseAddress("libsec2026.so");
if (secBase && !installed) { installed = true; setTimeout(doit, 2000); }
function hex(b) { return Array.from(new Uint8Array(b)).map(x=>x.toString(16).padStart(2,'0')).join(''); }
function doit() {
console.log("[*] secBase=" + secBase);
const ptrace = Module.findExportByName("libc.so", "ptrace");
if (ptrace) Interceptor.replace(ptrace, new NativeCallback(()=>0,'long',['int','int','pointer','pointer']));
const secEnd = secBase.add(0x400000);
let trackBlock = null;
let trackState = null;
let aab64_11_done = false;
let post_calls = [];
Interceptor.attach(secBase.add(0xaab64), {
onEnter(args) { this.round = args[0].toInt32(); },
onLeave(retval) {
if (this.round === 0xb) {
aab64_11_done = true;
console.log(`[AAB64(11) returned]`);
}
}
});
Interceptor.attach(secBase.add(0xa7194), {
onEnter(args) {
trackState = args[0];
trackBlock = args[1];
aab64_11_done = false;
post_calls = [];
console.log(`[A7194] state=${args[0]} block=${args[1]}`);
const tid = this.threadId;
Stalker.follow(tid, {
events: { call: true },
onCallSummary(summary) {
if (!aab64_11_done) return;
for (const [target, count] of Object.entries(summary)) {
const addr = ptr(target);
if (addr.compare(secBase) >= 0 && addr.compare(secEnd) < 0) {
const off = addr.sub(secBase).toString(16);
post_calls.push(`+${off} x${count}`);
}
}
}
});
},
onLeave(retval) {
try { Stalker.unfollow(this.threadId); } catch(e) {}
Stalker.flush();
console.log(`[A7194 EXIT] block=${hex(this.block ? this.block.readByteArray(16) : trackBlock.readByteArray(16))}`);
console.log(`[POST-AAB64(11) calls in libsec2026]:`);
for (const c of post_calls) console.log(" " + c);
}
});
// Run cipher
const sub_A7900 = new NativeFunction(secBase.add(0xa7900), 'pointer', ['pointer','pointer','pointer']);
const sub_A7194 = new NativeFunction(secBase.add(0xa7194), 'pointer', ['pointer','pointer','int']);
const state = Memory.alloc(512);
const k1 = Memory.alloc(16), k2 = Memory.alloc(16), block = Memory.alloc(64);
const k1B = "2c7e151618aec2a1abf7158809cf4f3c".match(/.{2}/g).map(x=>parseInt(x,16));
for (let i = 0; i < 16; i++) k1.add(i).writeU8(k1B[i]);
for (let i = 0; i < 16; i++) k2.add(i).writeU8(0);
for (let i = 0; i < 512; i++) state.add(i).writeU8(0);
const pt = "31323334353637383132333435363738".match(/.{2}/g).map(x=>parseInt(x,16));
for (let i = 0; i < 16; i++) block.add(i).writeU8(pt[i]);
sub_A7900(state, k1, k2);
console.log("\n[*] Calling A7194...");
sub_A7194(state, block, 16);
console.log(`\n[*] Final block: ${hex(block.readByteArray(16))}`);
}
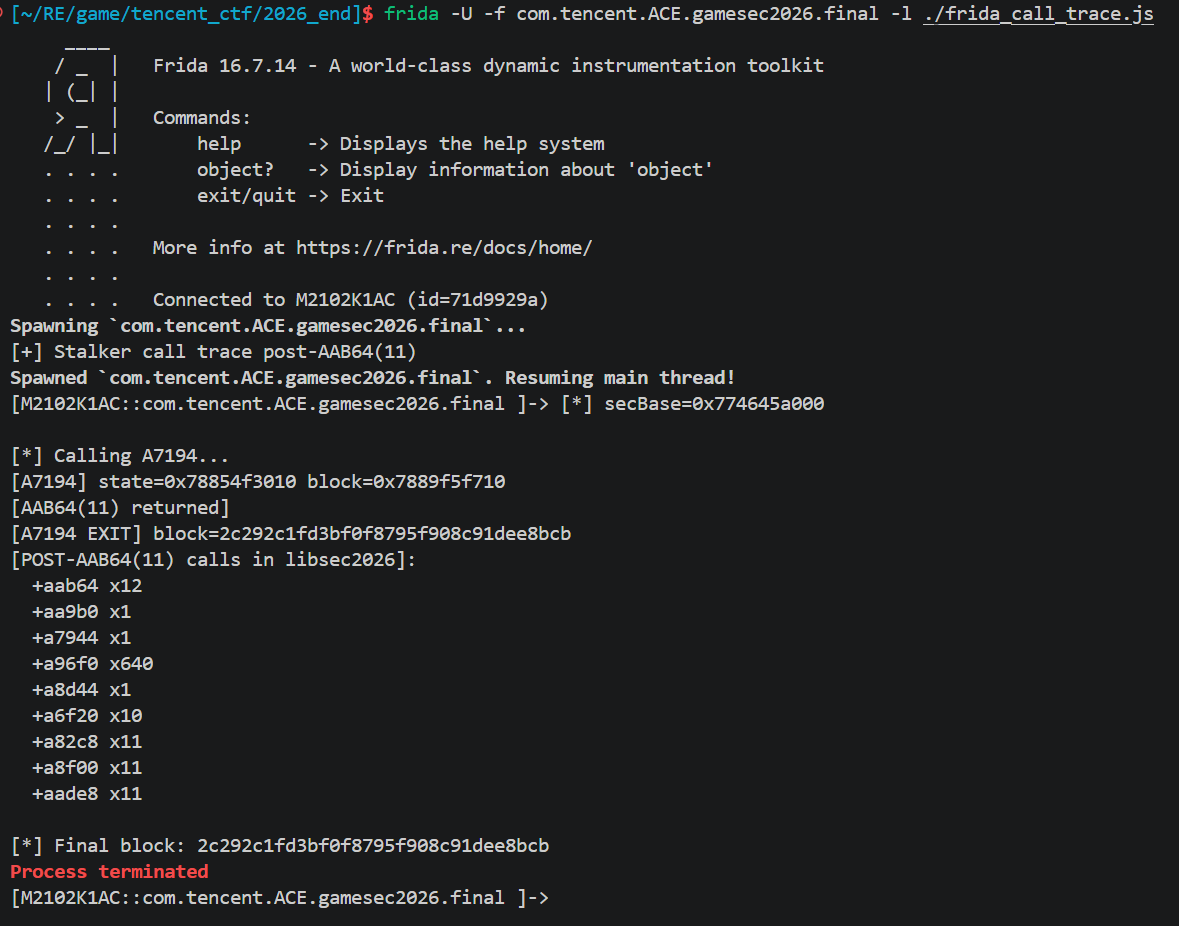
a96f0 x64 = 10 × 16 × 4,看着 a96f0 是 GF(2^8) 乘法(MixColumns 的 inner mul),a6f20是 MixColumns。11 轮 + 初始 round key + 最终轮无 MC,这就是 AES-128 的骨架(10 或 11 round,根据 Nk 变形)。
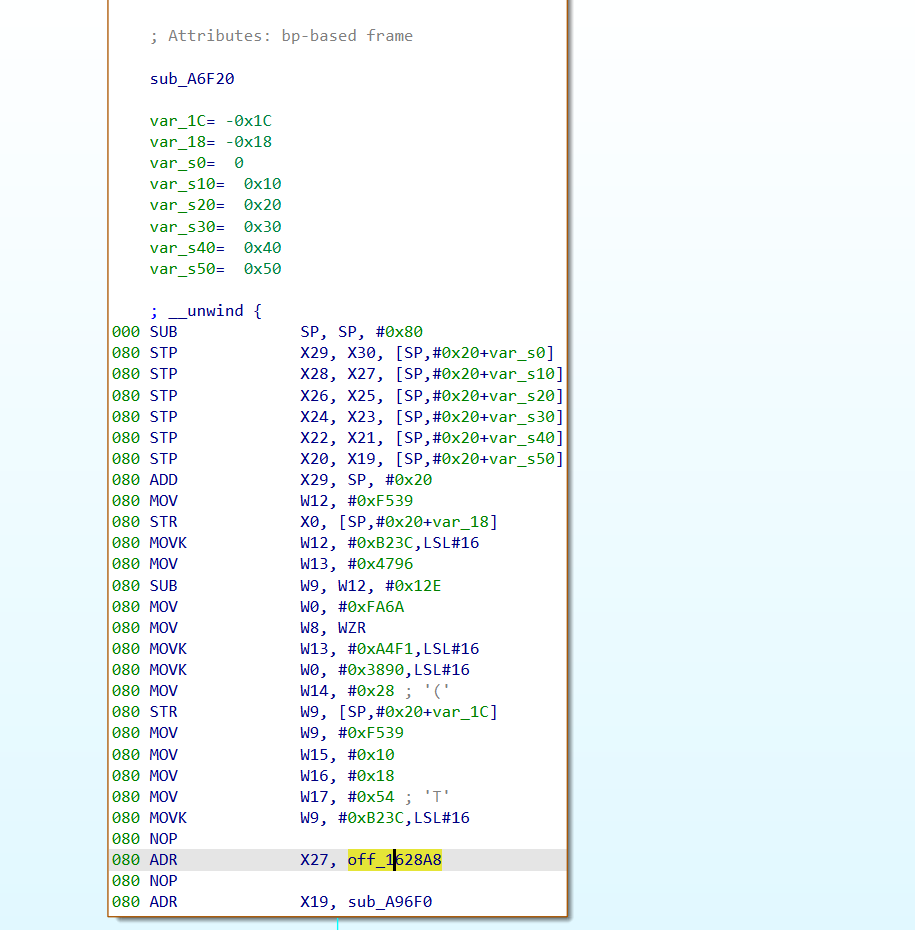
获取常量
首先有这么多的块,如何定位块的逻辑?
可以用Stalker去追踪
也就是之前的
提取所有 S-box 和常量
SBOX_ENC
1 | console.log("[+] Dump runtime tables"); |
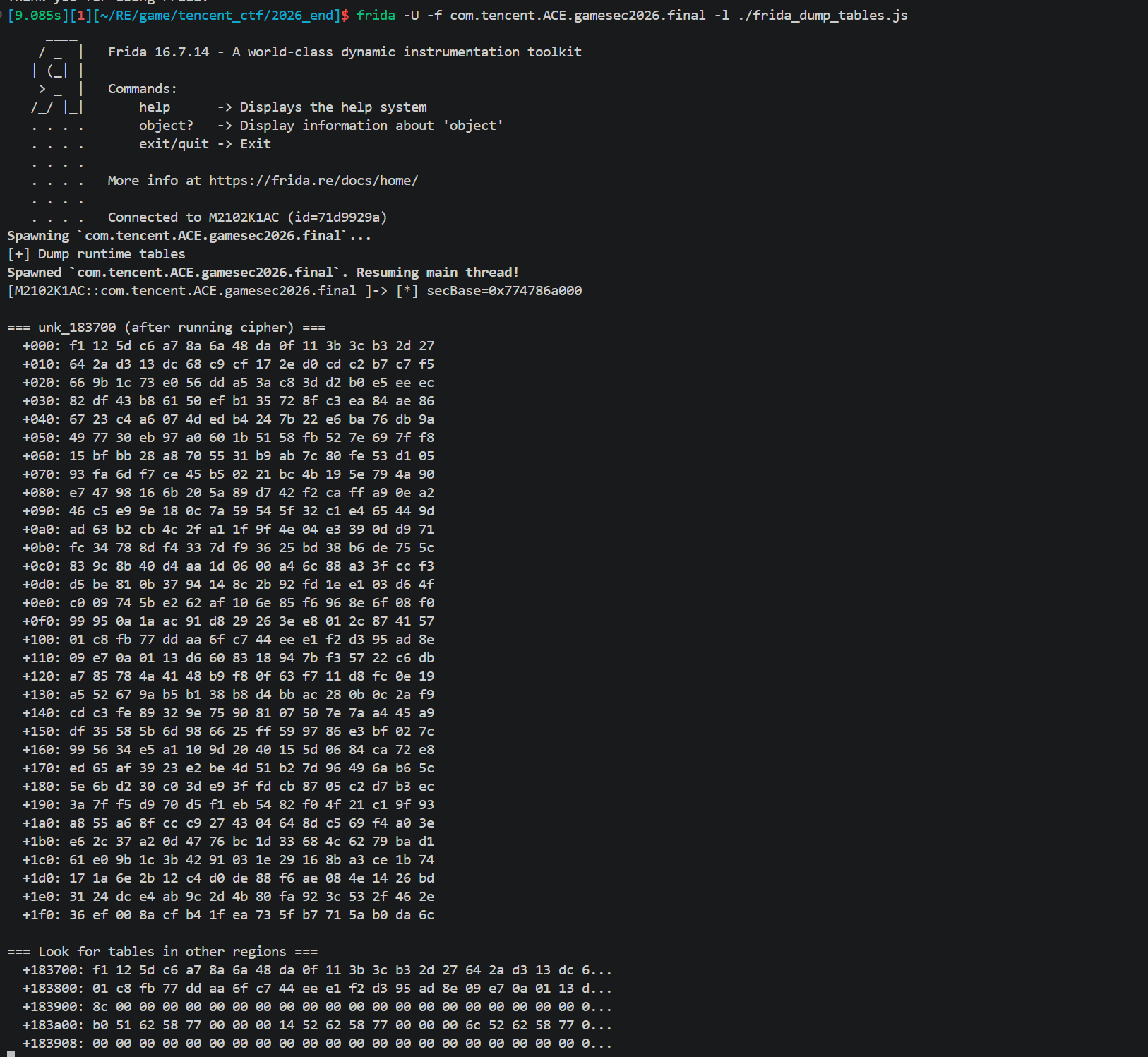
得到 256 字节的完整表。AES 标准是 0x63 … 看出来非标准了。
SBOX_KS和RCON也是类似做法
做法类似,但 SBOX_KS 与 SBOX_ENC是两张不同的表。通过跟踪 sub_A7DE8(key schedule 的 SubWord 子程)的内存读取定位表地址,dump 出 256 字节。
1 | console.log("[+] Full S-box sweep"); |
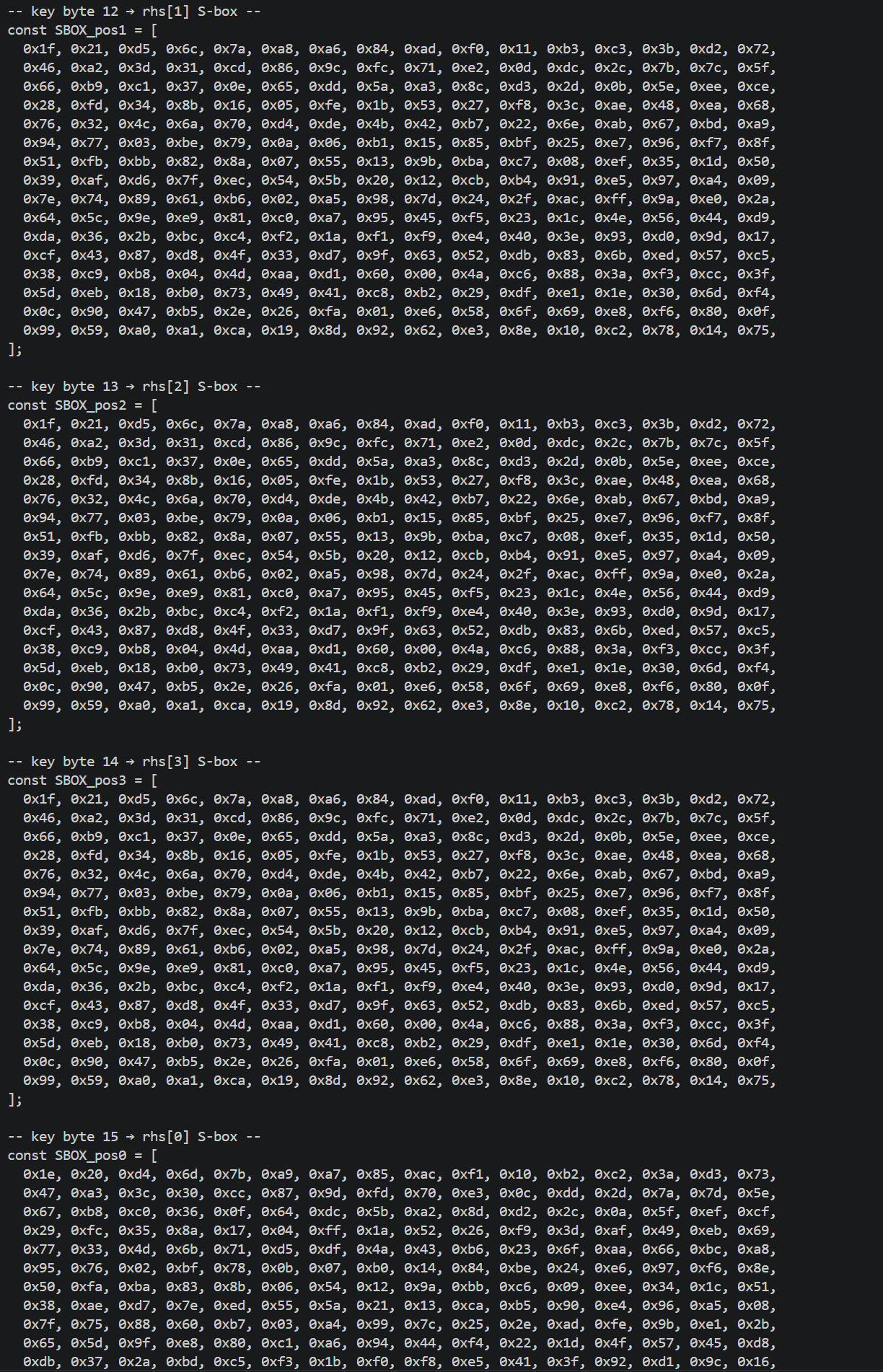
1 | console.log("[+] Extract A8F00 constants per round"); |
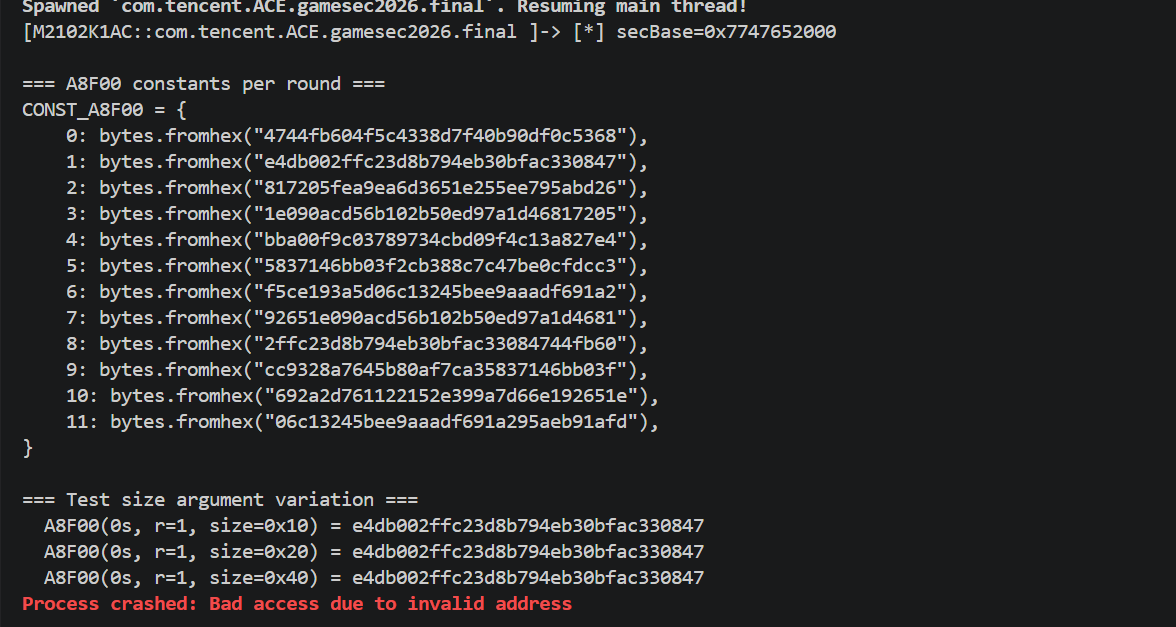
提取K_INIT
1 | console.log("[+] Sweep A7944"); |
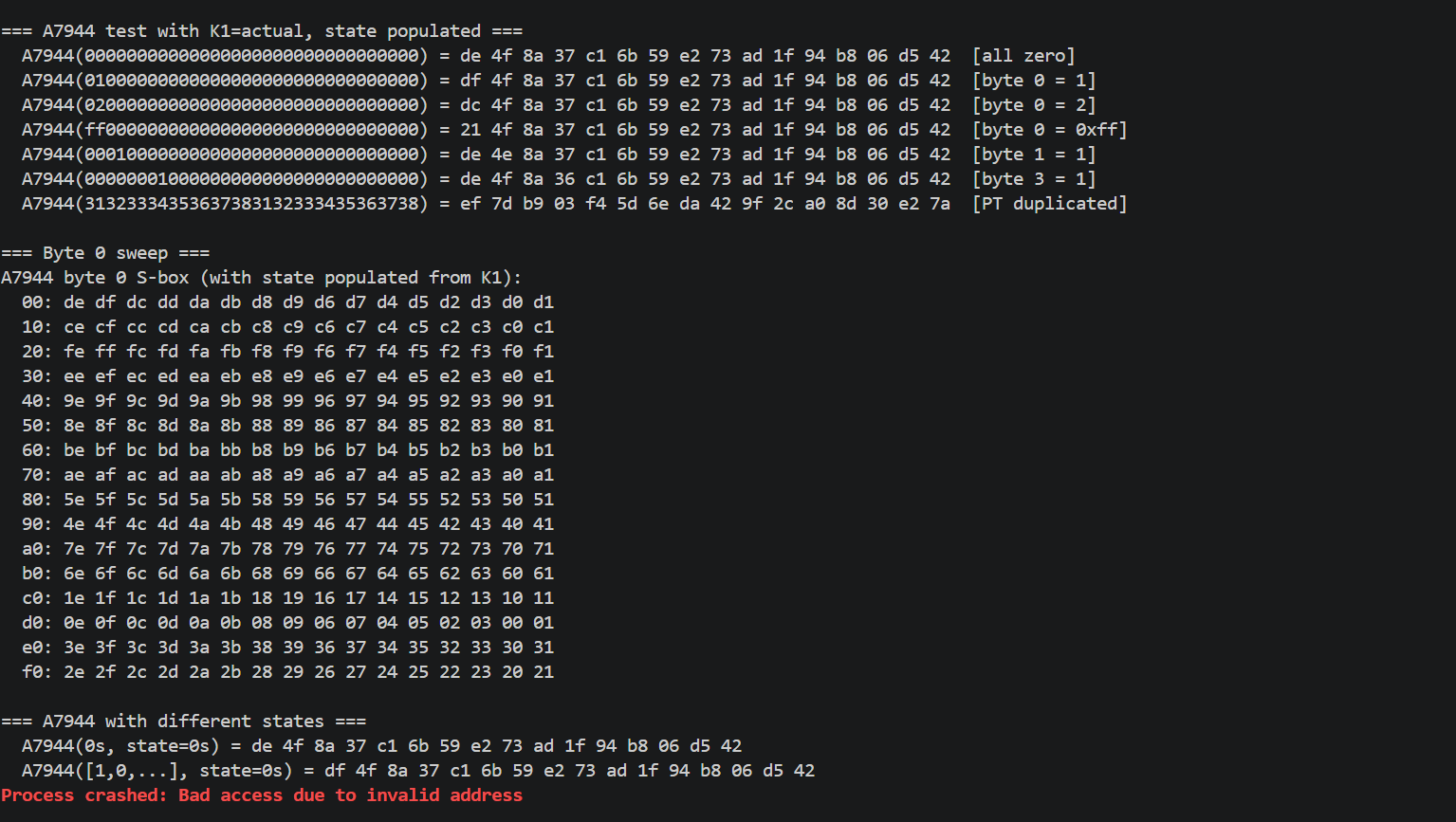
提取K1 K2
1 | // Probe how K2 is used in sub_A7194 |
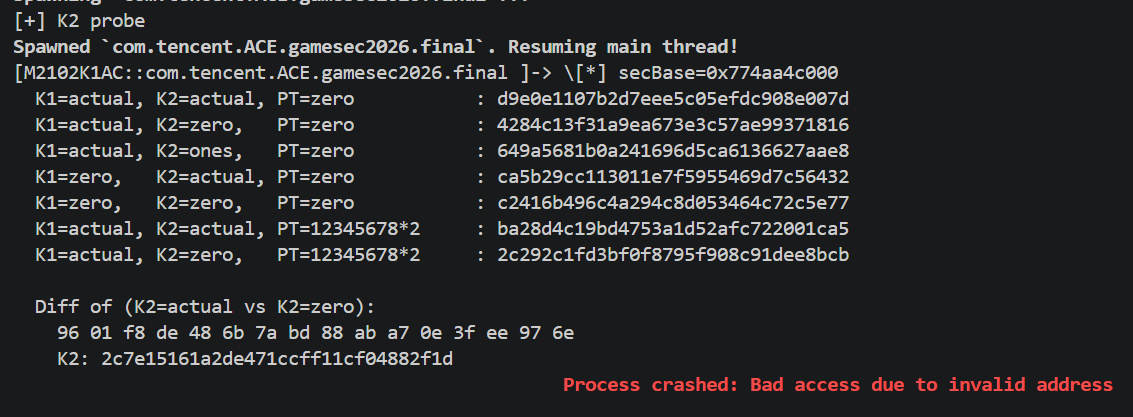
1 | // Dump AES round keys from sub_A7900 (key schedule) |
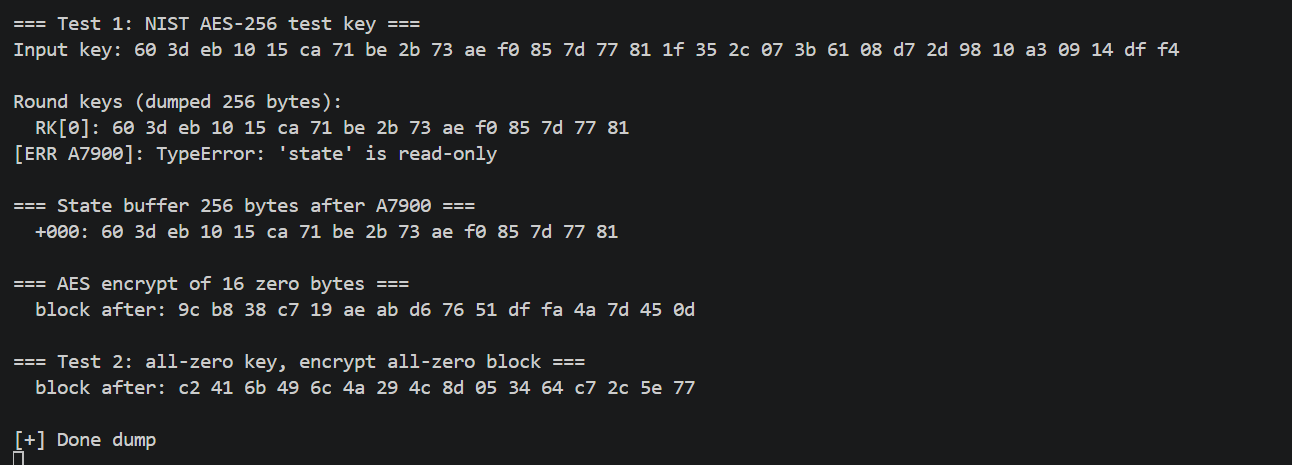
做了非常多的hook,有些没列出来,篇幅过长
1 | SBOX_ENC |
识别每个算法原语
AAB64 = AddRoundKey + pattern(round)
hook sub_AAB64(round, block, state):
- 读
before = block[0..16] - 读
rk = state[round*16 .. round*16+16] - 读
after = block[0..16] - 计算
eff_xor = before ^ after - 观察
eff_xor ^ rk是什么
实测每轮:eff_xor ^ rk = [base, base+1, base+2, base+3, base, ...],其中 base = (round * 0x5b) & 0xff。即:
1 | def aab64(state, rk, r): |
这个 (r*0x5b + i%4) 的 pattern 是我手动试探得来的,先检查 eff_xor ^ rk 是否为 0(不是),再看是否只和 round 有关(是),最后拟合出 base 和 stride 都是简单线性函数。
A82C8 = SubBytes(直接 SBOX 查表)
跟之前的脚本类似做法:喂不同 block 观察 after。对 block = 0,1,2,...,255 喂进去看输出,直接得到 S-box 映射。验证 = SBOX_ENC(同一张表)。
A8F00 = rot90 + const XOR
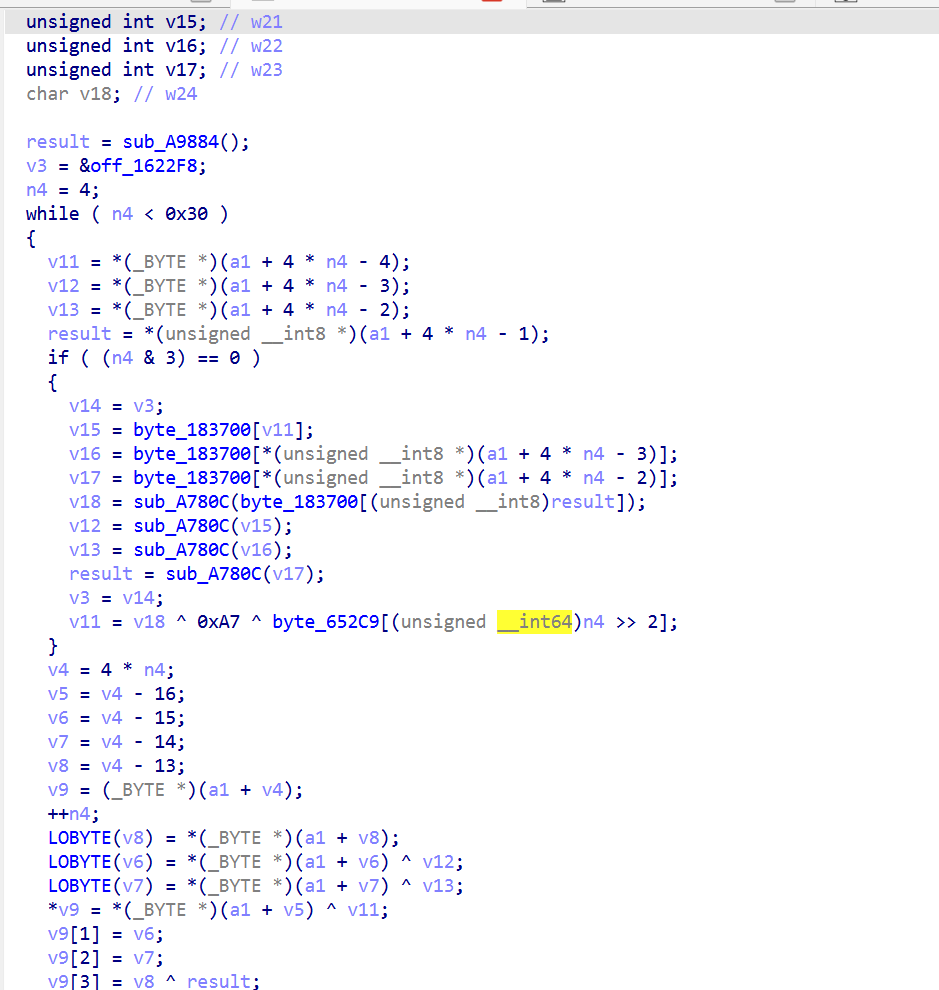
通过基矢测试:喂 block = [1,0,0,0,...]、[0,1,0,0,...]、…,看每一位 → 输出的映射。发现是纯字节置换(线性,不混 bit)。进一步验证置换就是 4×4 矩阵按列主序的 90 度旋转:
1 | dst[row*4 + (3-c)] = src[c*4 + row] |
再加一个 round 相关的 XOR 常量,就是 CONST_A8F00[r]。
AADE8 = ShiftRows
类似基矢测试得到字节置换。拟合出每行的 shift 量为 (0, 3, 1, 2)——row 0 不动,row 1 左移 3,row 2 左移 1,row 3 左移 2。不是标准 AES 的 (0,1,2,3)。
A6F20 = MixColumns(带非标准 poly)
通过基矢测试得到线性响应后,每列的 4 个输入对 4 个输出都有贡献(区分于 permute 的纯字节移动)。这意味着存在 GF 乘法。
拟合矩阵系数时,标准 GF(2^8) poly 0x1b 下解不出整系数。脚本暴力尝试 256 个 poly:对每个 poly,用矩阵反解看能否得到 0..255 范围内的小系数。最终 poly = 0x71 才给出干净的矩阵:
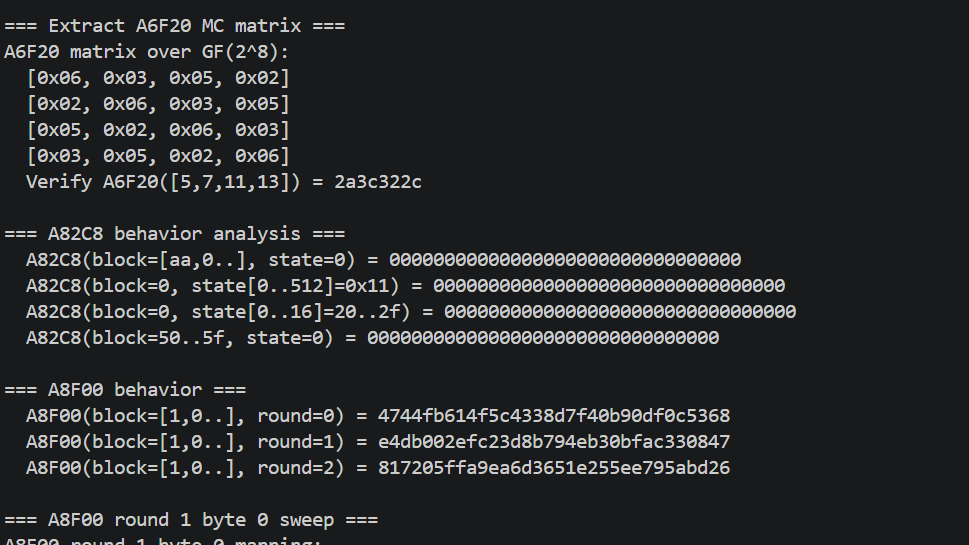
这与 Rcon 后 3 项用 0x71 翻倍的发现吻合,整套密码使用 poly 0x71。
AA9B0 = XOR permute_k2(K2)
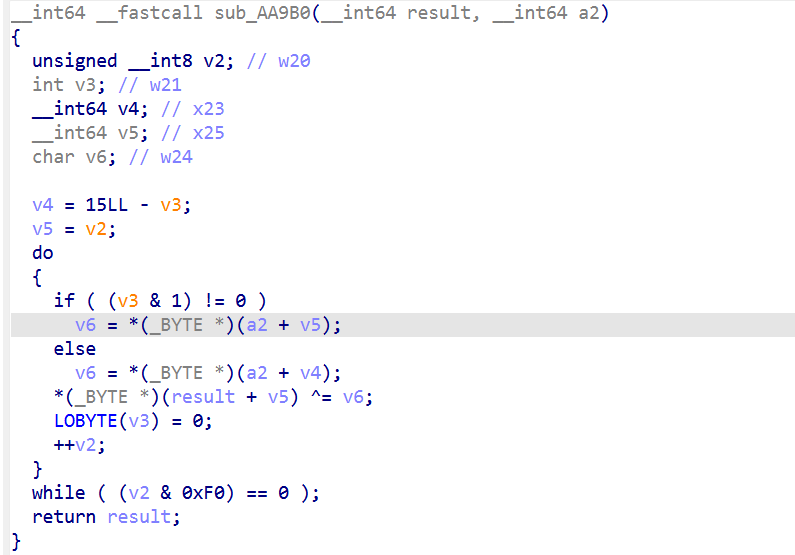
类似 AAB64 的做法,hook sub_AA9B0(block, k2, size),观察不同 K2 值对 block 的影响。测试 K2=0、K2=单点 1,发现输出是 block XOR 一个置换过的 K2。置换规则:
1 | permute_k2(K2)[i] = K2[i] if i是奇数 else K2[15-i] |
密钥扩展 sub_A7900 (Key Schedule)
类似标准 AES-128 key schedule,但 SubWord 用 SBOX_KS,RotWord 方向反转(右旋 1 而非左旋 1),Rcon 用 [01,02,04,08,10,20,40,80,71,e2,5b]。
但是按照 Frida Stalker 观察到的调用顺序拼出完整算法。
第一次验证失败:用 token 12345678,K2=0:
- Python 输出:
50ca048e75e2ff932e900f1157db674b - Frida 实际输出:
2c292c1fd3bf0f8795f908c91dee8bcb
中间步骤到 AAB64(11) 为止逐步完全匹配,但 sub_A7194 返回后 block 又被改了,可能还有其它逻辑
抓最终隐藏 XOR
确认修改发生的位置
脚本 hook AAB64(11) 的 onLeave、hook memcpy/__memcpy_chk/memmove
1 | console.log("[+] Post-AAB64(11) tracking"); |
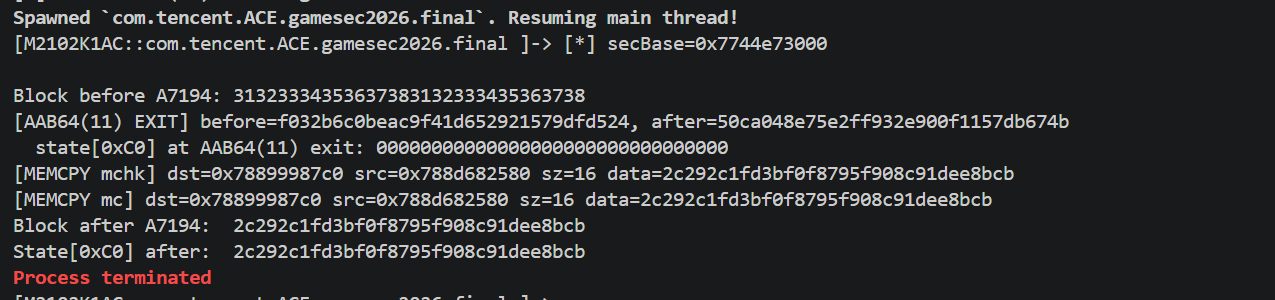
发现AAB64(11) 返回时 block = 50ca04…,但最后 memcpy 从 block 到 state+0xC0 的数据已经是 2c29.。说明在 AAB64(11) 返回到 memcpy 之间,block 被代码改写了。
验证 DIFF 是常量,4 个不同 token × 2 种 K2 值测试:
| token | K2 | my output | real output | diff |
|---|---|---|---|---|
| 12345678 | 0 | 50ca04… | 2c292c… | 7ce32891…ec80 |
| 00000000 | 0 | 6301e6… | 1fe2ce… | 7ce32891…ec80 |
| 10453fc3 | actual | 3ee4c5… | 4207ed… | 7ce32891…ec80 |
| 12345678 | actual | c6cbfc… | ba28d4… | 7ce32891…ec80 |
DIFF 恒为 7ce32891a65df014bb6907d84a35ec80
没有在代码里发现哪里做了手脚,但是通过diff得到是个定值
可能是通过运行时派生。
把这个diff作为最后的xor进去就得到了完整的算法
Unicorn 解法二
思想跟frida一样
定位到sub_97704后,有 一堆 flattening,题目做了很多懒初始化和跳表,可以写个unicorn
1 | from __future__ import annotations |
能看到执行了哪些函数统计执行次数

1 | A7944 1 次 |
说明:
- 有 round 0 whitening
- 有 10 个完整 round
- 有 1 个 final round
- final round 没有A6F20
- 最后还有单独尾处理 A84A4
然后再抓AA9B0,A8D44,A7194,各 round 的中间状态
1 | #!/usr/bin/env python3 |
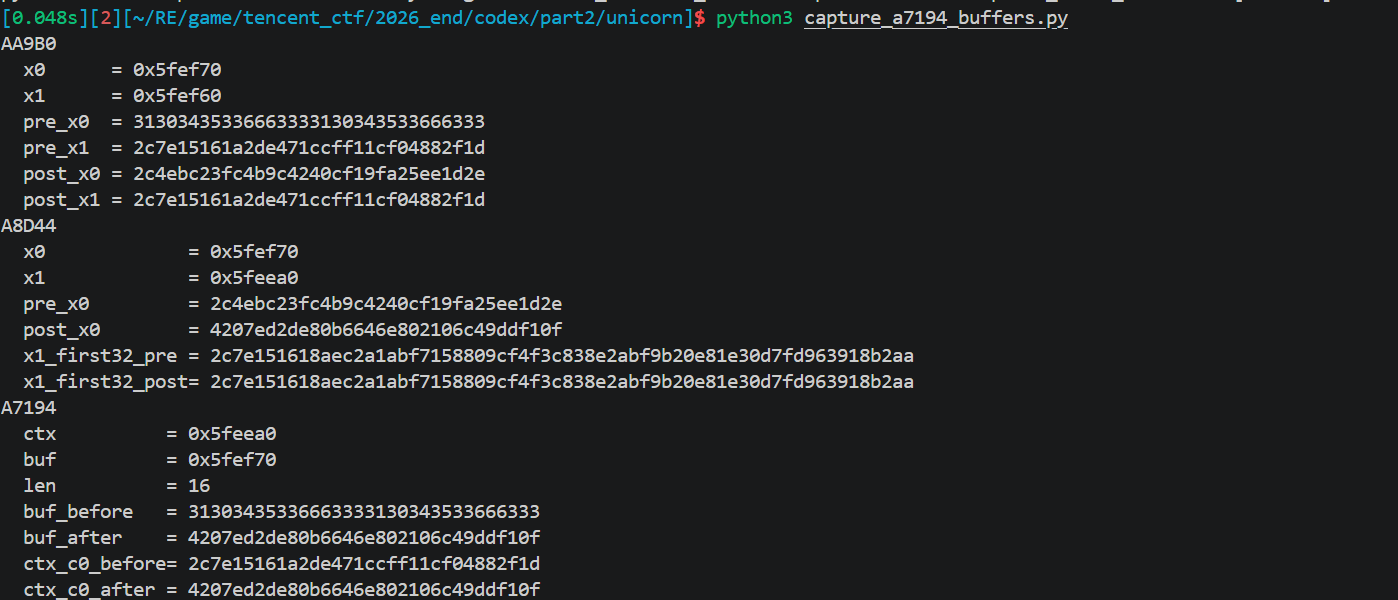
1 | #!/usr/bin/env python3 |
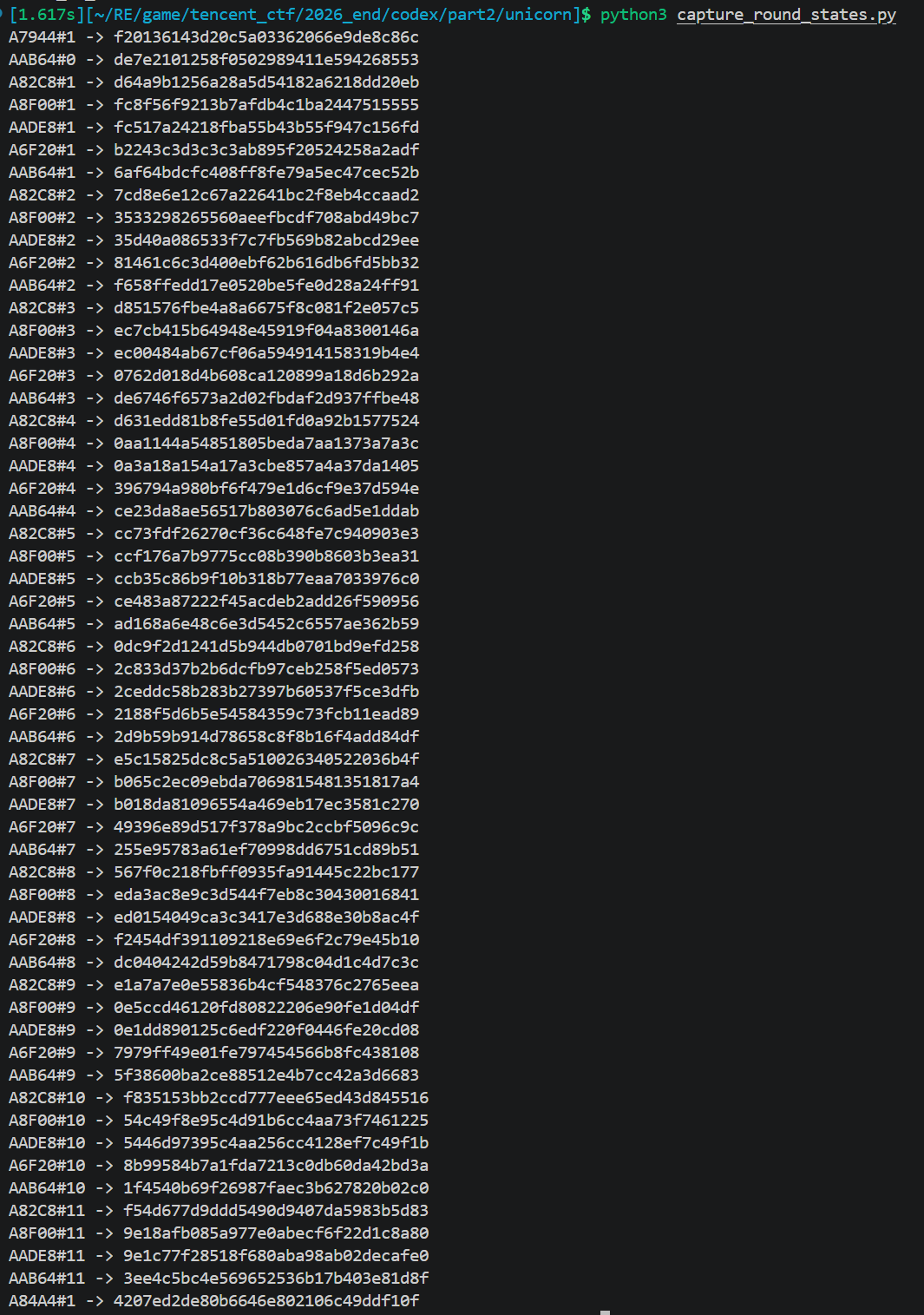
确认:
- AA9B0只是 duplicated token 的逐字节 xor
- A8D44是原地改写 16-byte state
- A7194只是调度器,不是实际轮函数
接着针对每一层分别识别:
A82C8
- 通过读 0x183700
- 确认是 256-byte 自定义 S-box
A8F00
- 通过 basis test
- 确认为纯字节置换
Perm1,加一组 round 常量
AADE8通过输入 00..0f,确认为固定字节置换Perm2
A6F20,起初最难,先看它自身只像个 flattened dispatcher,再继续追它内部 helper A96F0,识别A96F0是 GF 乘法
1 | #!/usr/bin/env python3 |
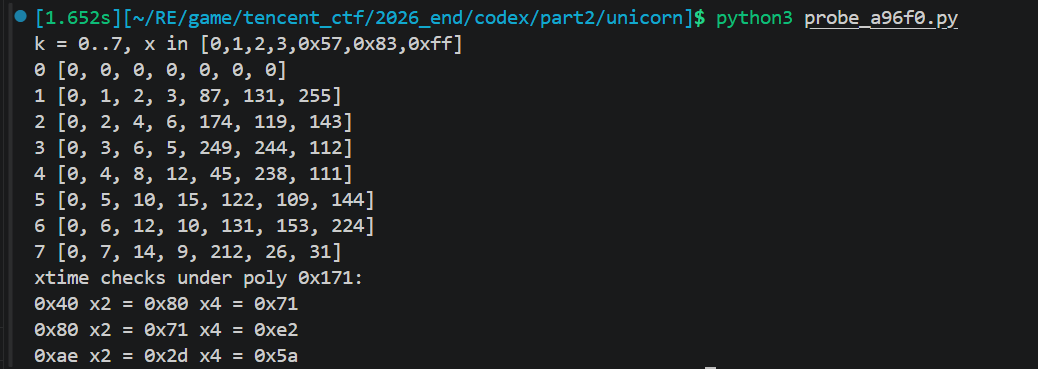
A96F0(x, k)的行为表明k=1是恒等,k=2/3/4/5/6/7 是 GF 上的常数乘法,约简多项式不是 AES 的 0x11b,而是 0x171
于是 A6F20 最终可以写成:
- 连续 4-byte 列混合
- GF(0x171)
- 4x4 矩阵
1 | [6 3 5 2] |
最后再抓:
- S-box
- round constants
- round keys
- A7944_CONST
- A84A4_CONST
1 | #!/usr/bin/env python3 |
自此所有材料已经具备
Part2的最终 pure forward 已经可以写成:
1 | state = (token_ascii || token_ascii) XOR C_init |
其中:
- C_init = ef4e153416e96631a9a425d0a740e660
- Perm1 = [12,8,4,0,13,9,5,1,14,10,6,2,15,11,7,3]
- Perm2 = [0,13,6,11,4,1,10,15,8,5,14,3,12,9,2,7]
- Mix_GF17 的域多项式是 0x171
中间还测了一些样例如
- 10453fc3 -> 4207ed2de80b6646e802106c49ddf10f
- deadbeef -> 6ae003283e97f2606f3e668bb5a6be0
- 00000000 -> be75f176a587d29af20b445dc2c0f3a8
- aaaaaaaa -> 3b7030bf9fbeb26c4313a51ed9bfa88e
去混淆 解法三
打印出一些patch必要信息,流程跟之前一样, 通用 OLLVM CFF 求解器:
1 | import struct, sys |
经过多次调试写出去混淆脚本,主循环patch(相当于手动patch)
1 | import ida_bytes, ida_funcs, ida_auto, ida_ua, idaapi |
1 | import ida_bytes, ida_funcs, ida_auto, ida_ua, idaapi |
sbox处
1 | import ida_bytes, ida_funcs, ida_auto, ida_ua, idaapi |
1 | import ida_bytes, ida_funcs, ida_auto, ida_ua, idaapi |
自此全部逻辑已获取
Python复现算法脚本
再三核实,三种方法的结果都对应下面的脚本
1 | #!/usr/bin/env python3 |

flag生成算法及逆算法 C
编译
1 | gcc -O2 -Wall -o part1_solver part1_solver.c |
1 |
|

part3 隐形方块
获取flag
过程分析
跟之前一样思路,在前面我们已经可以看到了,下面那个visiable为false
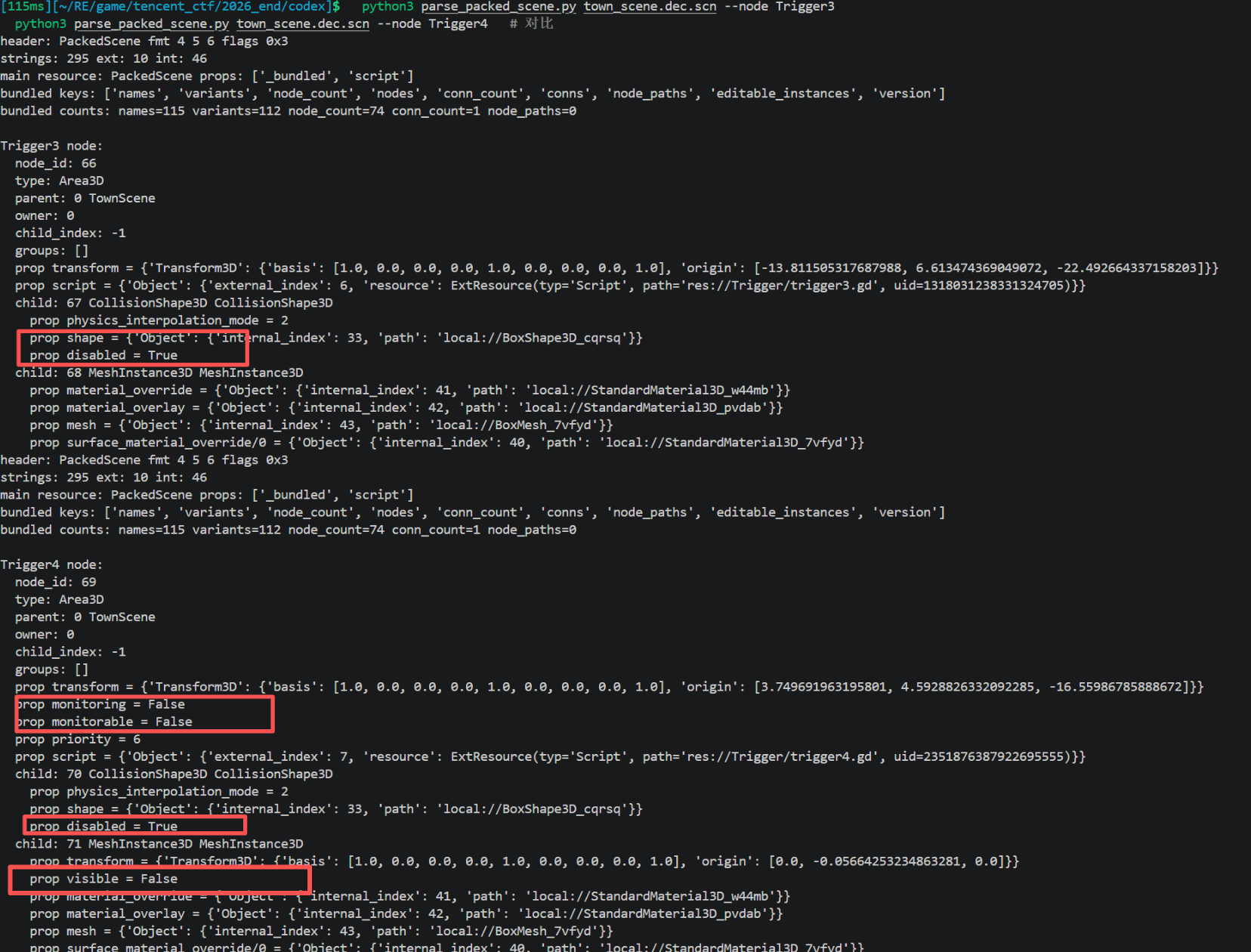
1 | Trigger4 node (id=69): |
4 层全关:
- Area3D.monitoring = False PhysicsServer 压根没把这个 area 当回事,不会发 body_entered
- Area3D.monitorable = False 对称的另一半
- CollisionShape3D.disabled = True 就算 monitoring 打开,area 也没碰撞形状
- MeshInstance3D.visible = False 隐形方块
所以 trigger4_call 的任务就是一次性把这 4 层全部打开,然后因为 Trigger4 离出生点只有很近看起来是,车稍微动一下就自然碰撞,不需要挪位置(不像 trigger2/3 位置高不可达必须传送)。
所以可以ptrace + 调 Godot 4 个 setter 函数。
找 setter 函数偏移,需要的 4 个 setter + 1 个 getter
1 | Area3D::set_monitoring(bool) @ libgodot+0x25F94A4 |
跟之前一样定位方法(capstone 扫描)对每个字符串做 ClassDB::bind_method 注册点查找:
1 | strings -t x libgodot_android.so | awk '$2 == "set_monitoring" {print}' |
ADRP + ADD指向字符串地址的代码点,在 ADRP 前 4 条指令找 ADR X0,
| set_monitoring | set_monitorable | set_disabled | set_visible | get_child | |
|---|---|---|---|---|---|
| 地址 | 0x25F94A4 | 0x25FAA0C | 0x2624AB4 | 0x12424A8 | 0x1FD9BD0 |
5 个函数都是ARM64 标准调用约定:
1 | set_xxx(this, value): X0 = this, X1 = value (整数) |
识别 Trigger4 实例
trigger2/3 得靠世界坐标 fingerprint 区分 4 个 Area3D,trigger4 不用。
识别规则扫内存找 Area3D vptr 拿到 4 个实例,读每个实例 offset +0x578(monitoring 字段):
1 | for (int i = 0; i < n_area; i++) { |
其实就是找唯一不可见的那个
AREA3D_MONITORING_OFFSET= 0x578,通过反汇编 Area3D::set_monitoring 函数体看到 STRB W1, [X0, #0x578] 反推。
ptrace-call 调 setter,通用 remote_call 框架
因为所有 setter 都是 X0, X1, ... 纯寄存器传参,一个通用函数覆盖所有调用:
1 | static int remote_call(pid_t tid, uint64_t func, |
force-zero 字节绕过 setter 早返回,这是 trigger4_call 特有的一个细节。Godot 4 的 setter 都有防抖:
1 | void Area3D::set_monitoring(bool p_enable) { |
如果 monitoring 当前值已经是 p_enable,setter 不会跑 PhysicsServer 注册。但我们希望无论当前值是什么,都强制重新注册一次(确保 PhysicsServer 状态和场景一致)。
因此可以调 setter 之前,用 pwrite64把字节预先清 0:
1 | // 对所有 4 个 Area3D 强制预清 monitoring/monitorable = 0 |
初次解谜时开车撞过 trigger4(导致 monitoring 已经变 1),再跑 trigger4_call 时没 force-zero 的话 setter 全部早返回、PhysicsServer 没重注册导致表面看调用成功但物理层没刷新。
完整流程
1 | 1. find_game_pid 扫 /proc/*/cmdline |
代码
1 |
|
编译
1 | /mnt/d/AndroidNdk/android-ndk-r27d/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android24-clang -O2 -pie trigger4_call.c -o trigger4_call |
flag截图

后面可以直接拿去验证算法真实性
分析线性关系 [解法一]
主要有两个任务
- 定位找算法位置
- 逆向算法
因为一开始以为tick是part3绕了好久,一直没找到part3位置
逻辑定位
入口定位从 GDScript 追到 sub_A9A7C,
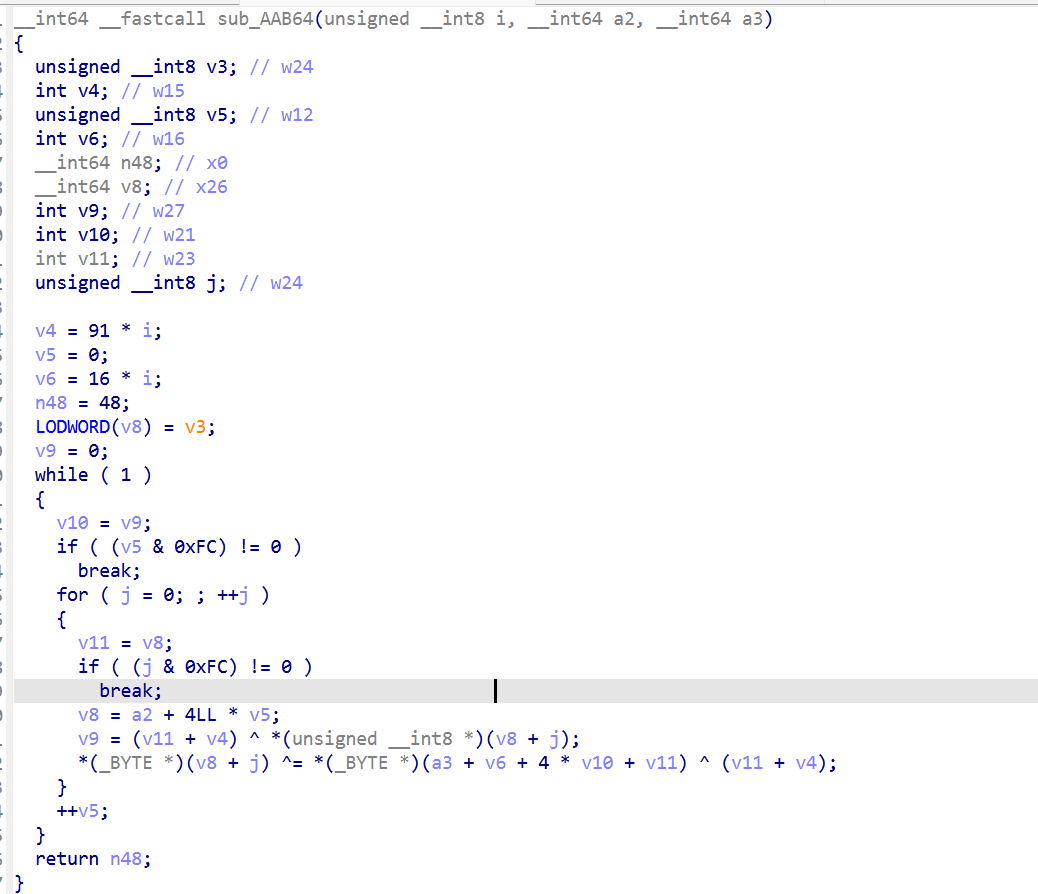
直接搜flagd等字符串也搜不到,感觉libsec2026 不直接构造 flag 字符串,可能有某种收发机制,转向 libgodot 找collided_with发射点。
collided_with 是 trigger4.gd 通过 _w7 接收的信号名,但 trigger4.gd 自己根本没 _w7,证明这个信号由 native 发出。grep libgodot 字符串:
1 | "collided_with" @ libgodot+0x42BBD1 |
直接发现尾部函数尾部确实有:
1 | sub_3C91744(&s_1, "collided_with", 0); |

但这只是发射机制,算法不在这里。算法藏在 arg的构造过程里
在F12搜索里没搜到,但是通过直接对整个文件过滤发现了相关字符串
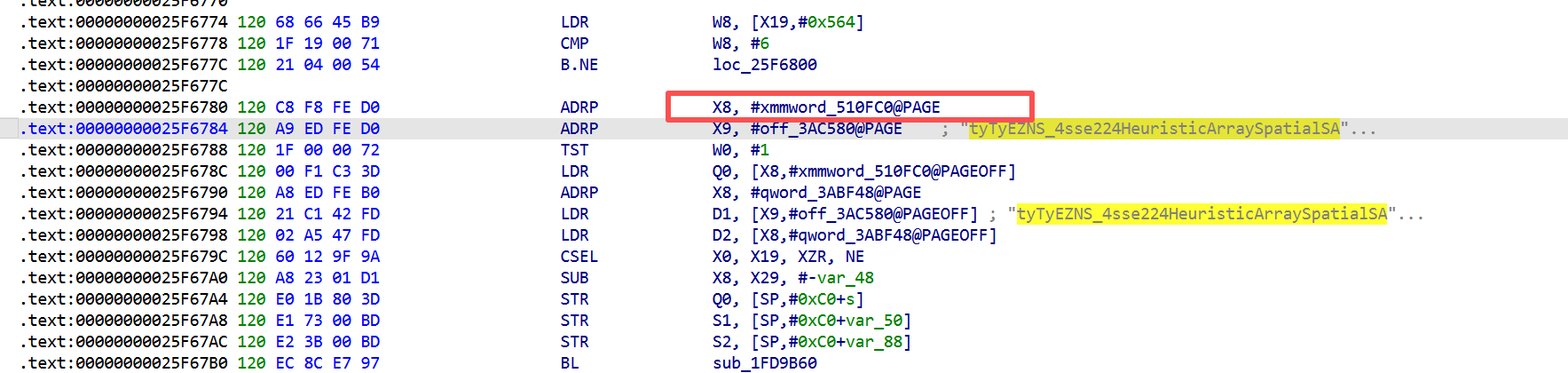

一眼顶真 flag
拼起来就是flag{sec2026_PART3_” + <hash> 由 v27(s_7) 这个函数调用产出:

1 | v27 = (qword_4011848 + dword_400A054); // 动态计算的函数指针 |
跟踪qword_4011848 :
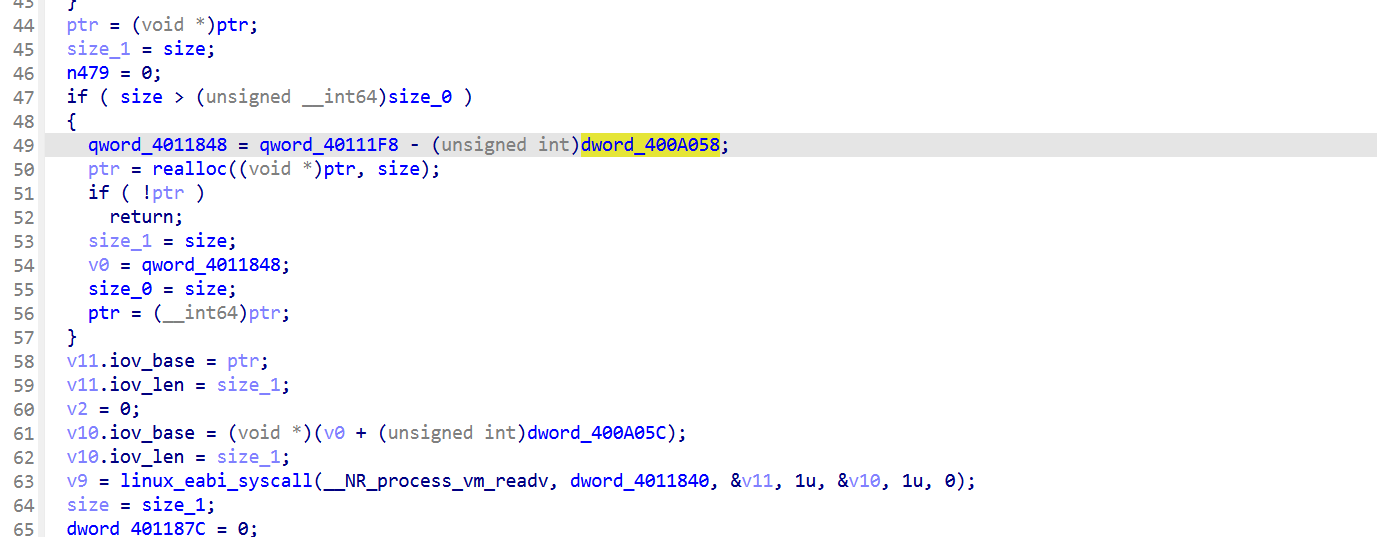
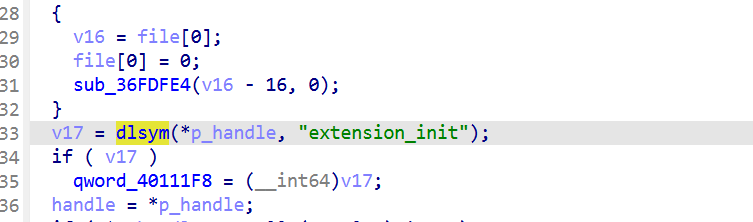
1 | qword_4011848 = qword_40111F8 - dword_400A058; |
把 dword_400A054 = 0x000A9A7C 和 dword_400A058 = 0x000A4074代回去:
1 | v27 = libsec2026.extension_init - 0x000A4074 + 0x000A9A7C |
PART3 = libsec2026.so::sub_A9A7C(token_string)
1 | trigger4.gd::_process |
VM分析
sub_A9A7C 是 OLLVM 扁平化 dispatcher,每个 state 跳到一个 handler,handler 自己又是 OLLVM 状态机。多层嵌套 OLLVM。直接读汇编基本不可行
观察sub_A9A7C的代码结构,dispatcher loop 形态像解释器,每次循环:
- memcpy 32 字节到栈缓冲
- 一些 CPU 指令做解码
- memcpy 把结果写到某处
这是经典 VM 解释器模式。0x63D80 处发现 SBC0 magic + 5414 字节字节码,确认是 VM 程序段:
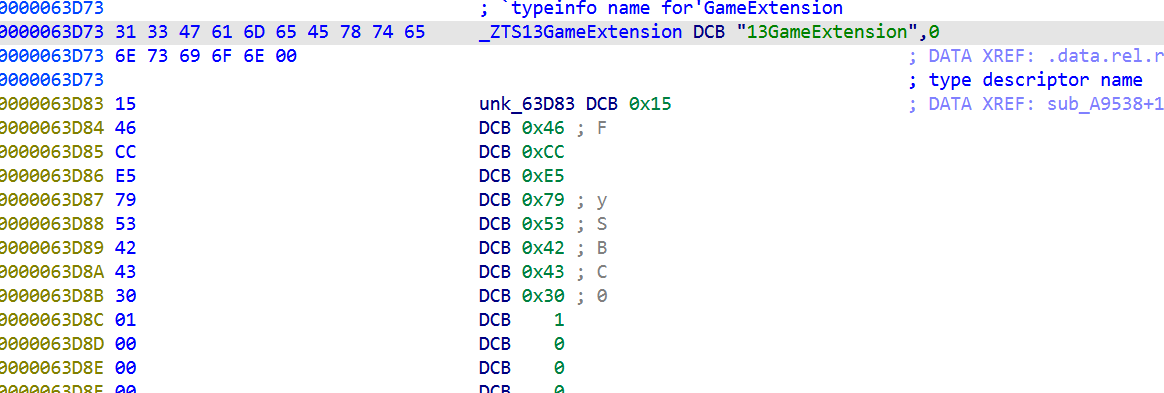
一般VM的处理思路就是动态trace,观察执行,观察它对内存做了什么。
每条 VM 指令的执行模式,这也是大部分CTF题中的例子,一般我们只需要对中间这下断点读出来就能一定程度上反推逻辑。
1 | memcpy(stack_buf, BC_HEAP + VM_PC, 32) |
所以BC_HEAP + 32 字节 memcpy出现一次就是一条 VM 指令开始。基于此写第一个工具:
1 | # disas_sbc0.py |
完整代码
1 | #!/usr/bin/env python3 |
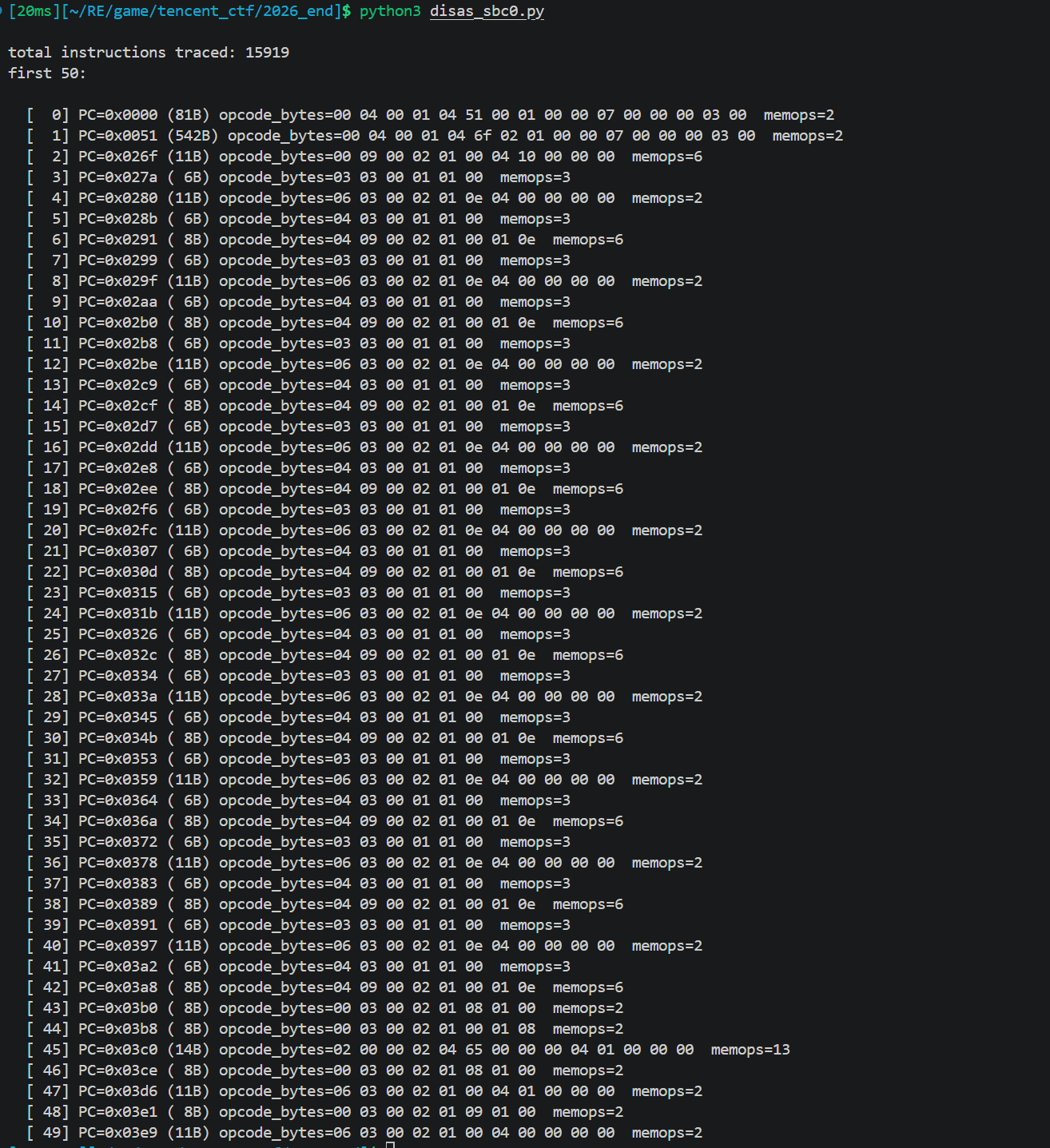
跑一次 token=12345678 的 sub_A9A7C 模拟,输出15919 条指令,662 个独特 PC。
上图只输出了前50
主循环识别:28 轮 × 557 条指令
按 PC 分组统计指令:
1 | PC=0x0000 (81 字节) ← 函数 header |
主循环每轮 557 条指令。28 × 557 + 一些 setup/teardown ≈ 15919。
28 轮这个数字非常关键, 不是常见 AES 的 10或14 轮,可能不是常见密码,有可能是自定义的
观察一轮内的 memcpy 写入目标,每条指令写到栈上 16 个固定槽位之一(每个槽位 4 字节)。每轮重置,所以:
1 | Round r: |
类似 SSA(静态单赋值)形式。每轮 16 个 slot,每个 slot 算一次。问题简化为:每个 slot 的公式是什么?
跑两次 sub_A9A7C,输入只差 1 字节:
1 | trace_a = run("12345678") |
输出2000 条指令的 memop 不一样,剩下 13919 条完全相同。
因此只有那 2000 条指令是输入相关的算术,其他都是 dispatcher 控制流。忽略 13919 条,集中分析剩下 2000 条。
完整代码
1 | #!/usr/bin/env python3 |
每条 VM 指令带着它写了哪些内存地址、每次写了多少字节、写了什么
1 |
|
70 个主循环 PC、每个 PC 恰好命中 28 次
1 | count pc |
70 个 PC × 28 轮 = 1960 条 diff,再加 27+1×13 = 40 条 init finalize,总和 2000 条,这 70 个 PC 就是主循环内每轮都执行且写结果跟 token 相关的 VM 指令。
两次 trace 的 PC 序列一模一样,说明算法是线性的
三类槽位反复出现
1 | dst = 0x100feb70 一个"scratch / accumulator"槽 |
1 | 0x2032f710 ← slot 0 (最终槽) |
连续 16 个地址 + 每个地址出现的 PC 只 1 个,这 16 个 PC 就是 s[0]..s[15] 的赋值点。其他 54 个 PC 是取数据到临时槽、执行算术、写回临时槽这些中间步骤。
从 round#0 数据能看出的关系
1 | slot pc dst run1 data run2 data |
每个 8 字节只用了低 4 字节,第 17 个地址 0x2032f790 跟 slot 7 的数据一致 = fe17327500000000 = 0xFE173275。可能是把 s[7] 复制到 chain 链传给下一轮
核心流程是 constraint-satisfaction:
1. 每个 slot 收集 28 轮的 (输入变量, 输出) 对(输入 = state, prev_s7, r,输出 = slot 值)
2. 枚举可能的公式模板
3. 每个模板在全部 28 轮都成立才接受
其实就是用 28 组 (输入, 输出) 数据反解公式。肉眼看 hex 能直接看出移位关系;减法/XOR 跟恒定常数有关;乘法用模逆解;两变量组合暴力扫。用数据本身的约束把可能的公式缩小到 1 个
从 pickle 抽出每轮每个 slot 的值
1 | rounds1 = [ |
28 × 16 = 448 个 u32 数字(每个 token 一套,两个 token 就是 896 个)。这就是数据,拟合任务变成给 896 个数字,解出公式,因为之前已经证明了都是线性的
建立状态链,从前面还得知每轮的 state 和 prev_s7 不是内存里直接读的,是从上一轮 chain 过来的
1 | state[0] = LE_u32(token[4:8]) # 初始,直接从 token 取 |
对每个 slot 按优先级试 4 种模板
对 slot N,可用输入源 = {state, prev_s7, r, s[0], s[1], …, s[N-1]}
按顺序试:
1. 移位: src << k, src >> k (k = 1..31)
2. 轮号乘: src + r * K
3. 加法常数: src + K
4. XOR 常数: src ^ K
5. 双变量组合: src1 ^ src2, src1 + src2
第一个在全 28 轮 × 2 个 token 都成立的公式就被接受
关键是那些常数K,不需要枚举 2^32 个 K
1 | # round 1 的约束: actual = src + K |
其实很简单,意思就是我们之前跑过一遍,知道对应的所有值,我们可以把这个当成结果,写算法,让它去试那种变化能达到这种结果
1 | 第1轮外循环:src = state |
因此我们可以写个自动化算法,这里的/tmp/memop_trace.pkl,是我们之前代码执行的产物,是已知的结果
1 | import pickle |
对每个 slot 收集所有轮的输入, 输出穷举常见模式:
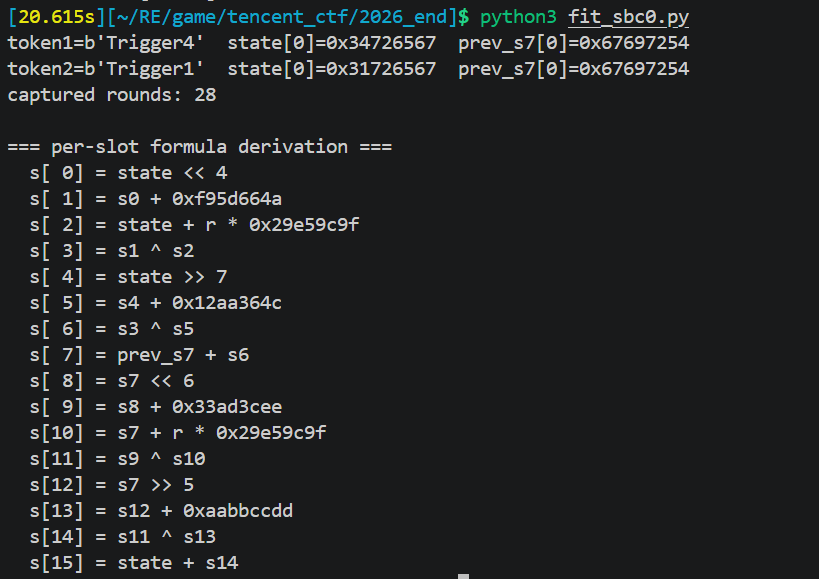
1 | def sbc0_hash(token: str) -> str: |
5 个魔数:
K1 = 0xF95D664AK5 = 0x12AA364CK9 = 0x33AD3CEEKX = 0xAABBCCDDKR = 0x29E59C9F(轮号乘数)
链式状态:state ← s[15]; prev_s7 ← s[7]。每轮把这两个值传到下一轮。
正向测试
之前写的测试unicorn进行测试
1 | from __future__ import annotations |
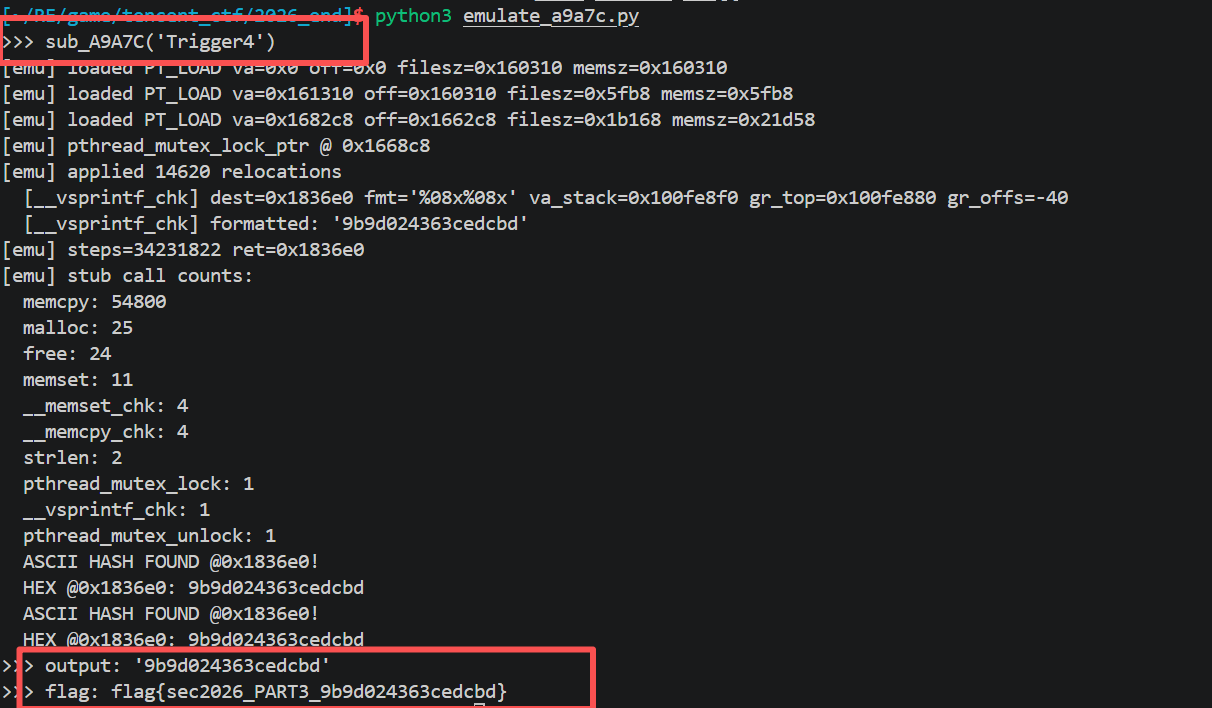
1 | import struct, sys |

逆向分析
PART3 是 hash 但完全可逆,因为每轮是双射:
关键观察:
- s14 的计算只依赖 s7和 r(不依赖 state)因此给定 new_s7 能直接算 s14
s6的计算只依赖 state和 r(不依赖 prev_s7)因此给定 state能算 s6- 所以
state = new_state - s14可解,prev_s7 = new_s7 - s6也可解
1 | def s14_of(s7, r): |
1 | import struct, sys |

ollvm去混淆 [解法二]
时间有点来不及了,写的有点潦草
用前面提到的逆向思想去混淆
代码:
1 | import ida_bytes |
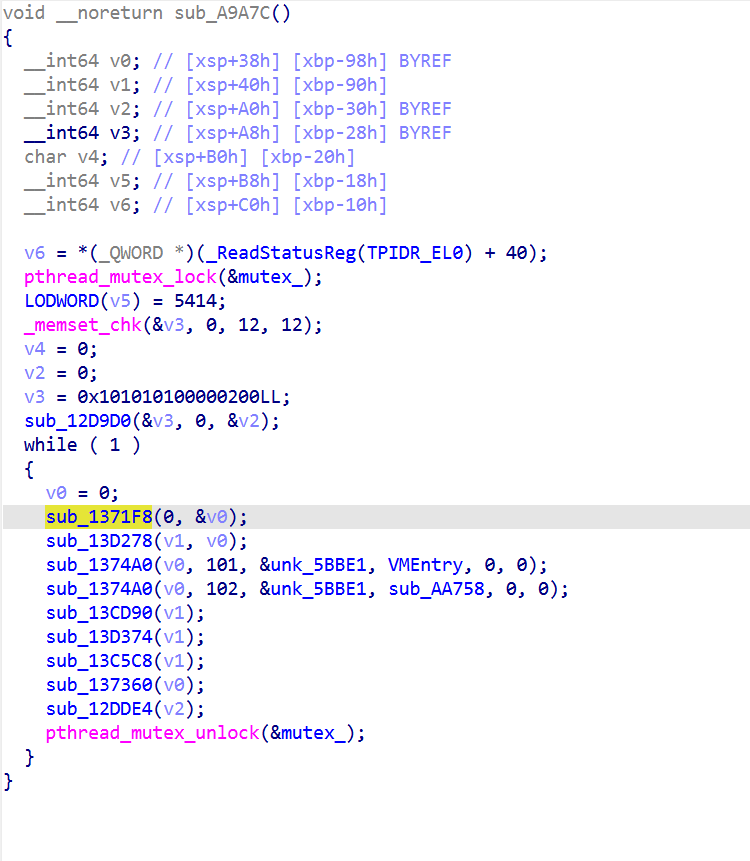
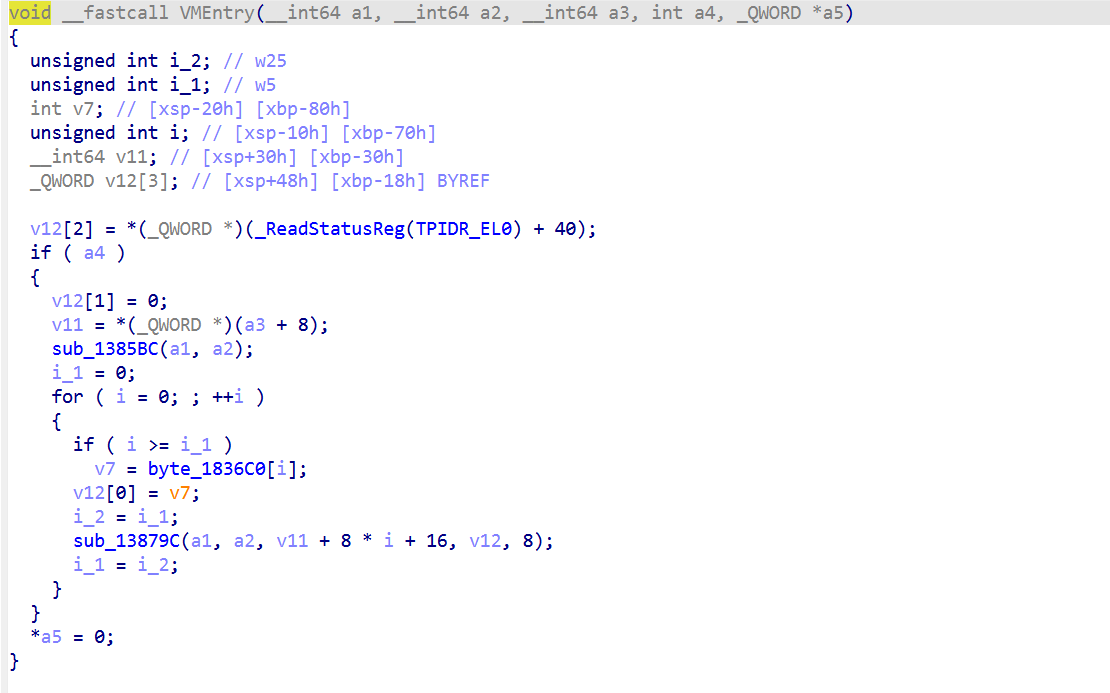
这里就能得到字节码了
下一步要拿 PART3 真实算法,逆向 sub_13879C 的 opcode 表或逆向 sub_A9A7C 看它怎么从 input 编码 bytecode

但是一些函数还是没有被去混淆
实际上从 0x137000 到 0x138B00 的一坨函数,36 个 handler 互相通过 BR X8 链调用,最终都收敛到 handler 35 0x137A98
这里又是一个dispatcher
可以写个IDA脚本,把 36 个 handler 都定义成有名字的独立函数,当然中间也去一个个看这些块的实际意义了
1 | import ida_funcs, ida_bytes, ida_auto, idaapi, ida_name |

1 | import struct, sys |
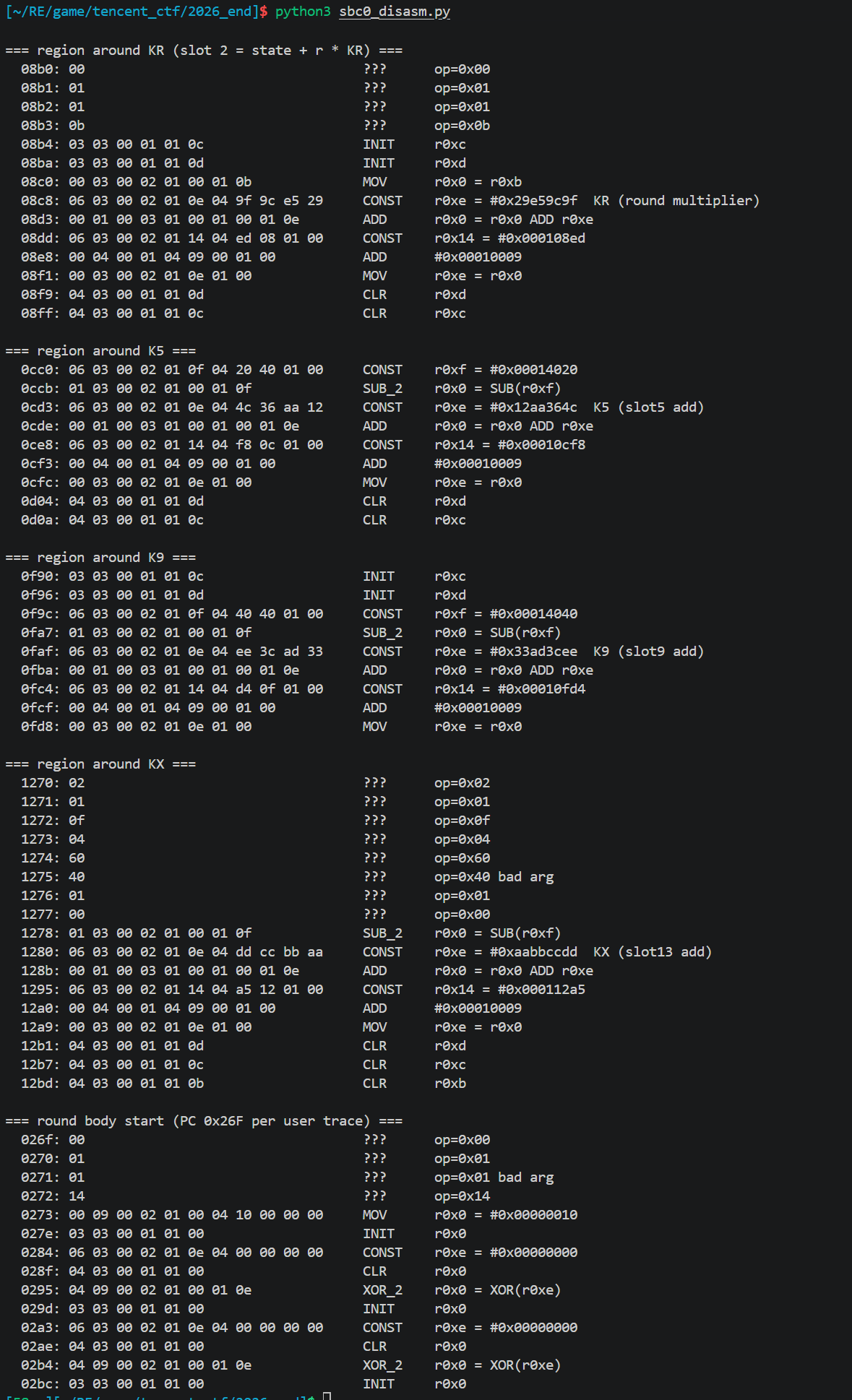
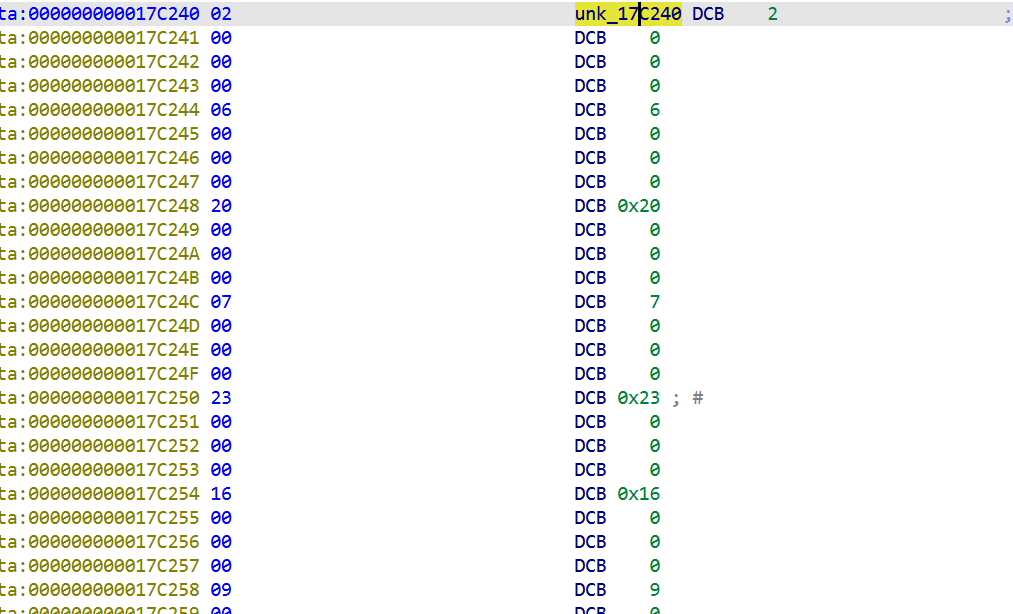
unk_17C240 (opcode→idx) + off_17C120 (36-handler 表) 两层间接
VM 解释器是 sub_13879C + 36-handler 表 + bytecode opcode 编码。
instruction 的统一格式是 OP TYPE 00 NARGS [args]
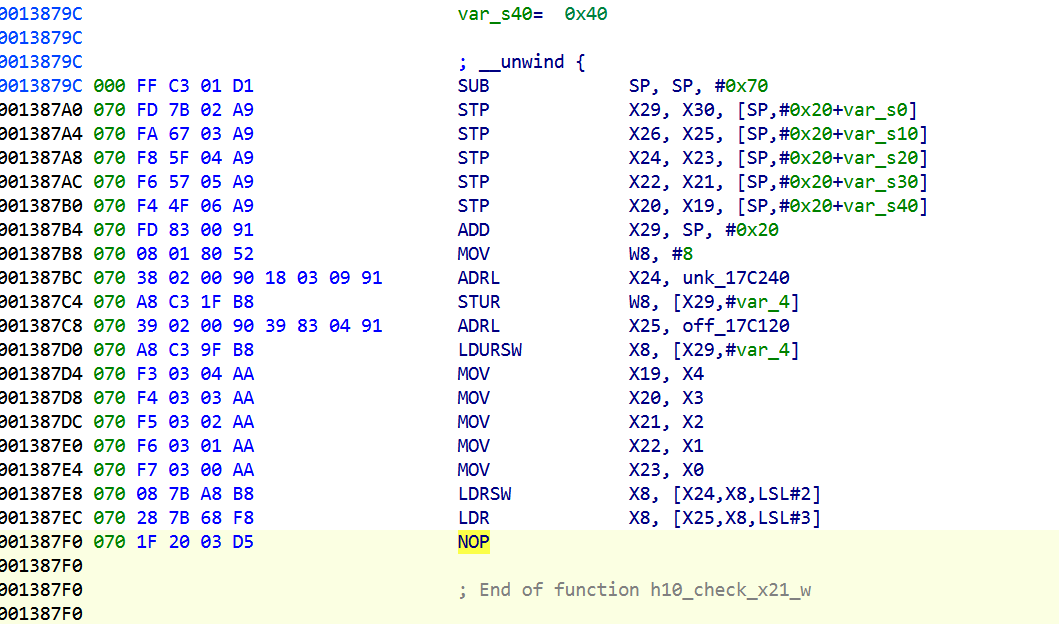
后面的流程其实就跟解法一一样了
用unicorn模拟下
1 | import struct, sys |
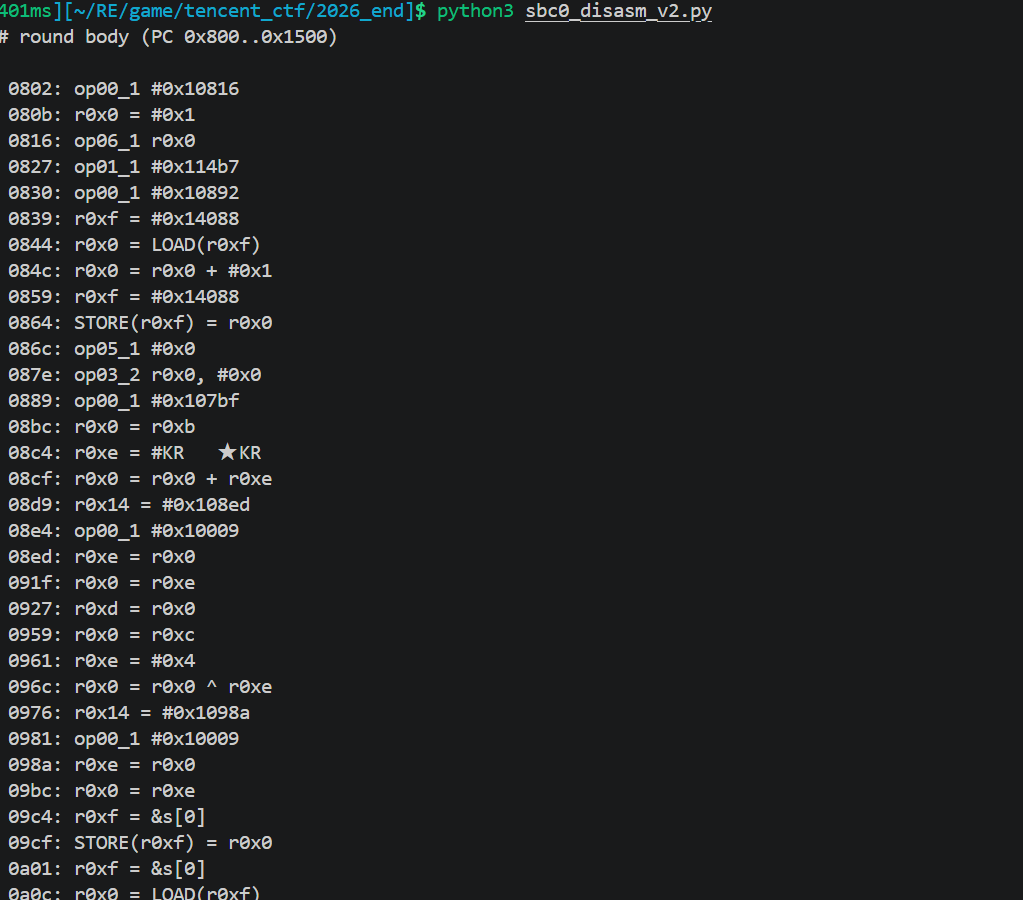
分析这些可以得到所有的slot公式
每条 slot 公式在 bytecode 里都精确定位:
| slot | 用户 Unicorn 公式 | bytecode STORE PC | 关键操作 PC |
|---|---|---|---|
| s[0] | state << 4 |
0x09CF | LSL @ 0x096C (r0xc << #4) |
| s[1] | s[0] + K1 |
0x0A82 | ADD @ 0x0A1F (after CONST K1 @ 0x0A14) |
| s[2] | state + r*KR |
0x0B27 | ADD @ 0x0AC4 (state + r0xd where r0xd = r*KR precomputed) |
| s[3] | s[1] ^ s[2] |
0x0BE2 | XOR @ 0x0B7F (LOAD s[1] XOR LOAD s[2]) |
| s[4] | state >> 7 |
0x0C8A | LSR @ 0x0C27 (r0xc >> #7) |
| s[5] | s[4] + K5 |
0x0D3D | ADD @ 0x0CDA (after CONST K5 @ 0x0CCF) |
| s[6] | s[3] ^ s[5] |
0x0DF8 | XOR @ 0x0D95 (LOAD s[3] XOR LOAD s[5]) |
| s[7] | s[6] + prev_s7 |
0x0EB3 | ADD @ 0x0E50 (LOAD s[16] + LOAD s[6]) |
| s[8] | s[7] << 6 |
0x0F66 | LSL @ 0x0F03 (LOAD s[7] << #6) |
| s[9] | s[8] + K9 |
0x1019 | ADD @ 0x0FB6 (after CONST K9 @ 0x0FAB) |
| s[10] | s[7] + r*KR |
0x10C9 | ADD @ 0x1066 (LOAD s[7] + r0xd) |
| s[11] | s[9] ^ s[10] |
0x1184 | XOR @ 0x1121 (LOAD s[9] XOR LOAD s[10]) |
| s[12] | s[7] >> 5 |
0x1237 | LSR @ 0x11D4 (LOAD s[7] >> #5) |
| s[13] | s[12] + KX |
0x12EA | ADD @ 0x1287 (after CONST KX @ 0x127C) |
| s[14] | s[11] ^ s[13] |
0x13A5 | XOR @ 0x1342 (LOAD s[11] XOR LOAD s[13]) |
| s[15] | state + s[14] |
0x1455 | ADD @ 0x13F2 (r0xc + LOAD s[14]) |
| s[16] | state ← s[15]; prev_s7 ← s[7] |
0x14A6 | (round chain update) |
时间有点来不及了,写的有点潦草
flag生成算法及逆算法 C
1 |
|

- wechat
- alipay


